







目录
一 预测电影评分
现在一共有五部电影,并且有四个观众的评分数据,评分从一星到五星,观众有可能并没看该电影,也就是未评分。
给出如下定义
- n_u=用户的数量
- n_m=电影的数量
- 如果用户j对电影i进行了评分,r(i,j)=1
- y(i,j)=1用户j对电影i的评分(只有r(i,j)=1时才有效)。
通过学习,得到用户对某些未曾评分的电影的预测评分,并进行电影推荐。

二 基于内容的推荐
1.对于上述示例,建立两个特征 (x1,x2)->(romance,action),并对不同的电影给出特征值
2.对于每一个用户j,学习一个参数 ,预测用户j 对低i部电影的评分为
个星。
具体公式化如下所示

三 如何学习参数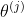


一句话总结,确定优化目标,用梯度下降法进行优化(给出学习率)
四 协同过滤
1.背景介绍
根据上述例子,假设我们不知道每部电影的的”浪漫程度“和”动作程度“的具体值,可以通过用户的评价来进行预测,但是如果用户没有给出评价怎么办?也可以对每个用户都询问其偏好,然后得到这个用户的参数,然后根据下述计算,得到每部电影的特征值


总结:所以我们可以通过每部电影的特征值,计算出用户对电影的评分,也可以根据用户的偏好,计算出电影的特征向量
如何同时计算上述两种参数?引入协同过滤算法
2.协同过滤算法
将上述两个代价函数加起来,得到如下代价函数

其计算过程如下
1.初始化特征值和参数值以非常小的随机值
2.用梯度下降法最小化上述代价函数
3.使用一个用户的偏好参数θ和电影的特征系数x来预测该用户未评价过的电影的评星θ_Tx。

四 协同过滤的向量化实现
首先给出数据集如下

计算目标为得到下图右侧的矩阵(每个元素对应用户对电影的评分)

然后将每个电影的评分做为矩阵X ,将每个用户的参数作为,则
可以计算出P中的每一个元素
以上过程也叫低秩矩阵分解
五 如何找到跟某个电影相似的电影
计算两个电影的特征向量的模即可

六 均值规范化
之前的例子中,所有的用户都至少有一个偏好设置(比如喜欢动作电影,参数里面会有体现),但是对于一个新用户,没有任何偏好设置,也没有任何评分的时候,该如何去处理?
如果在这种情况下进行预测,系统会认为新用户对所有电影的评分都是0,显然这样是不对的。

因此引入了均值规范化来解决上述问题
1.首先计算平均值,然后将Y矩阵减去平均值得到新的Y矩阵(使得Y矩阵中每行的求和结果都是0)
2.用户j 对电影i的评分预测为:

因为前面减去了均值,所以需要再加回来
3.对于新用户,假设参数为[0,0],则按上面的公式计算,从而的到预测值















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









