







 LDA(Latent Dirichlet Allocation)是一种文档生成模型,认为文章由多个主题构成,每个主题对应不同词。文章生成过程中,首先选择主题,再在该主题下选词。LDA用于分析文章主题,其非监督学习性质使用词袋模型,需要预设主题数量。LDA涉及多项式分布,包括两点分布、二项分布和多项式分布,以及参数估计方法如极大似然估计和贝叶斯估计。
LDA(Latent Dirichlet Allocation)是一种文档生成模型,认为文章由多个主题构成,每个主题对应不同词。文章生成过程中,首先选择主题,再在该主题下选词。LDA用于分析文章主题,其非监督学习性质使用词袋模型,需要预设主题数量。LDA涉及多项式分布,包括两点分布、二项分布和多项式分布,以及参数估计方法如极大似然估计和贝叶斯估计。
简述LDA
LDA涉及的知识很多,对于作者这样的菜鸟来说想要弄清楚LDA要费一番功夫,想简单说清更是不易,写下此文,也是希望在行文的过程中,把握LDA主要脉络,理顺思路。也希望我理解的方式与顺序,能帮到一部分初学的朋友。如果有不对的地方,也欢迎作出指正。
什么是LDA主题模型
首先我们简单了解一下什么是LDA以及LDA可以用来做什么。
LDA(Latent Dirichlet Allocation)是一种文档生成模型。它认为一篇文章是有多个主题的,而每个主题又对应着不同的词。一篇文章的构造过程,首先是以一定的概率选择某个主题,然后再在这个主题下以一定的概率选出某一个词,这样就生成了这篇文章的第一个词。不断重复这个过程,就生成了整片文章。当然这里假定词与词之间是没顺序的。
LDA的使用是上述文档生成的逆过程,它将根据一篇得到的文章,去寻找出这篇文章的主题,以及这些主题对应的词。
现在来看怎么用LDA,LDA会给我们返回什么结果。
LDA是非监督的机器学习模型,并且使用了词袋模型。一篇文章将会用词袋模型构造成词向量。LDA需要我们手动确定要划分的主题的个数,超参数将会在后面讲述,一般超参数对结果无很大影响。

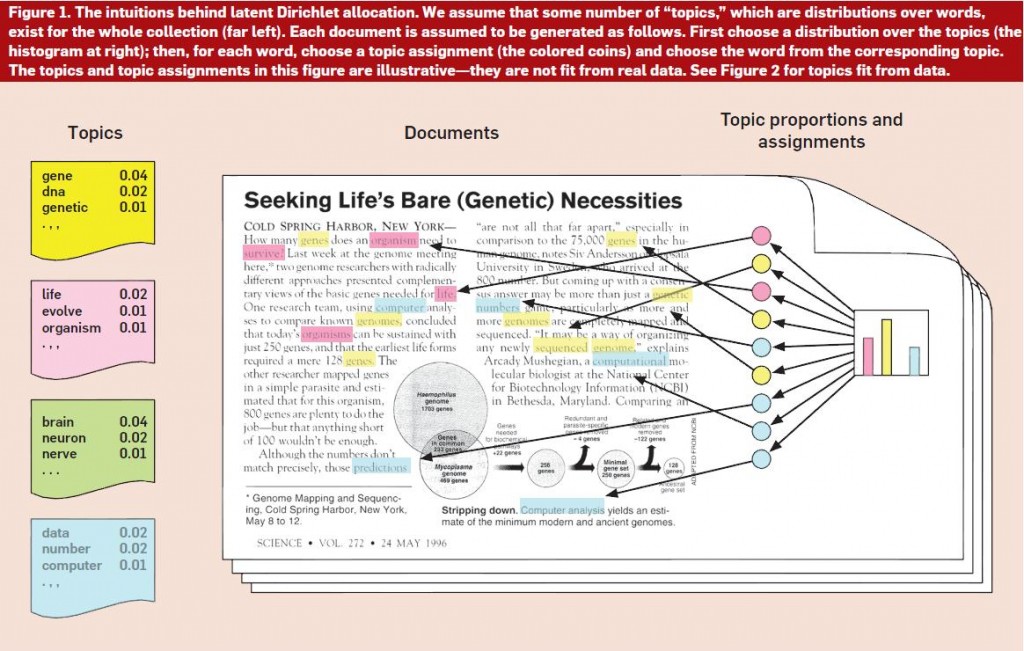

上图是推断《Seeking Life’s Bare(Genetic)Necessities》(Figure 1)的例子。使用主题建模算法(假设有100个主题)推断《科学》上17000篇文章的潜在主题结构,然后推断出最能描述图1中示例文章的主题分布(图左)。需要注意的是,尽管主题分布上有无穷个主题,但事实上只有其中的一小部分的概率不为零。进一步地,文章中词可被分主题进行组织,可以看到最常见的主题所包含的概率最大的词。
主题分布与词分布
上面说了,一篇文章的生成过程,每次生成一个词的时候,首先会以一定的概率选择一个主题。不同主题的概率是不一样的,在这里,假设这些文章-主题符合多项式分布。同理,主题-词也假定为多项式分布。所谓分布(概率),就是不同情况发生的可能性,它们符合一定的规律。
如果你数学基础和我一样薄弱,可能你已经忘了什么事多项式分布,这里我们首先回顾一下两点分布和二项分布,多项式分布是二项分布的延伸。二项分布是两点分布的延伸。
两点分布
已知随机变量X的分布率为
| X | 1 | 0 |
|---|---|---|
| p | p | 1-p |
则有
E(x)=1∗p+0∗q=p
D(x)=E(x2)−[E(x)]2=pq
抛一次硬币的时候,不是正面就是反面,符合两点分布。这里概率P为参数。
二项分布
二项分布,即是重复n次两点分布。设随机变量X服从参数为n,p的二项分布。其中,n为重复的次数,p为两点分布中,事件A发生的概率。设X=k为n次实验中事件A发生了k次的概率。
可以得到X的分布率为:
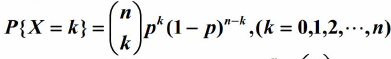
例如,丢5次硬币,事件A为硬币正面朝上,则 PX=k 表示求抛5次硬币,有k次硬币正面朝上的概率。通过计算可以得知二项分布的期望和方差如下,这里就不计算了:
E(x)=np
D(x)=np(1−p)
多项式分布
多项式分布(multinomial)是二项分布在两点分布上的延伸。在两点分布中,一次实验只有两种可能性,p以及 (1-p)。例如抛一枚硬币,不是正面就是反面。在多项式分布中,这种可能的情况得到了扩展。例如抛一个骰子,一共有6种可能,而不是2种。
设某随机实验如果有k个可能情况 A1、A2、…、Ak,分别将他们的出现次数记为随机变量X1、X2、…、Xk,它们的概率分布分别是p1,p2,…,pk,那么在n次采样的总结果中,A1出现n1次、A2出现n2次、…、Ak出现nk次的这种事件的出现概率P有下面公式:
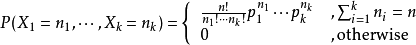
这里,p1,p2…pk都是参数
那么现在我们回到LDA身上,前面已经说了主题和词是符合多项分布的,我们可以用骰子形象地表达一篇文章的生成的过程。
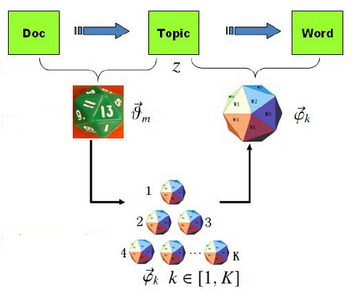

有两类骰子,一种是文章-主题(doc-topic)骰子,骰子的每面代表一种主题。这里设一共有K个主题,则K面。骰子的各个面的概率记为 ϑ⃗ =(p1,p2,p3,...,pk) 。各个面的概率即为这个多项式分布的参数。
另一种骰子为主题-词(topic-word)骰子,一共有K个,从1~K编号,分别对应着不同的主题。骰子的一个面代表一个单词。由于有K个骰子,把不同主题-词骰子各个面的概率分别记为 φ⃗ 1,φ⃗ 2,...φ⃗ k 。对于一个主题-词骰子,他的各个面的概率即为这个多项式分布的参数。
那么一篇文章的生成过程可以表示为:
- 抛掷这个doc-topic骰子,得到主题编号z
- 选择编号为z的topic-word骰子,得到词w
- 不断重复步骤1以及步骤2
参数估计
上面我们已经知道了主题分布和词分布都属于多项式分布,只是它们的参数究竟是什么值,我们还无从知晓。如果我们能估算出它们的参数,我们就能求得这些主题分布和词分布。LDA的主要目的就是求出主题分布和词分布,距离这个目的,我们近在咫尺。
极大似然估计
我们知道,频率可以用来估计参数。例如对于两点分布,抛硬币。当我们抛的次数足够多,可以估出p接近1/2,大数定理是有力的保证。频率学派为参数估计提供了另一种有力的工具——极大似然估计。它的思想可以这样形象地表达:既然样本已经出来了,我们有理由相信它们发生的概率很大,于是我们不如就设给定参数的情况下,出现这些样本的概率是最大的,通过求导计算极值,从而计算出参数。
在这里,我们的样本就是我们观察到的,文章 d ,以及文章里的词
p(w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









