







上一篇我们讲了使用CNN进行分类的python代码:
Mr.看海:【深度学习-第5篇】使用Python快速实现CNN分类(模式识别)任务,含一维、二维、三维数据演示案例(使用pytorch框架)
这一篇我们讲CNN的多变量回归预测。
是的,同样是傻瓜式的快速实现。
本篇是之前MATLAB快速实现CNN多变量回归预测的姊妹篇。
一、环境搭建
本篇使用的是Win10系统搭建VSCode+Anaconda+Pytorch+CUDA环境,当然如果你是用的是其他编辑器,没有使用anaconda,或者没有独立显卡,本文的程序也都是可以实现的(不过也需要正确配置好了相关环境)。
如果你还没有配置环境,或者配置的环境运行后边的代码有错误,那么推荐大家按照我之前的这篇文章操作来重新进行配置:
Mr.看海:【深度学习-番外1】Win10系统搭建VSCode+Anaconda+Pytorch+CUDA深度学习环境和框架全过程
环境搭建中遇到的问题,大家可以集中在上边这篇文章中留言反映。
二、什么是多变量回归预测
多变量回归预测则是指同时考虑多个输入特征进行回归预测。举几个例子:
- 房价预测:给定一组房产的特征,如面积、卧室数量、浴室数量、地理位置等,预测房产的销售价格。
- 股票价格预测:使用历史股票价格、交易量、财务指标等信息,预测未来某个时间点的股票价格。
- 销售预测:基于历史销售数据、季节性、促销活动等信息,预测未来某个时间段的销售额。
- 能源需求预测:考虑天气条件、时间(如一天中的时间、一周中的哪一天、一年中的哪个月份等)、历史能源需求等因素,预测未来的能源需求。
- 疾病风险预测:根据患者的年龄、性别、生活习惯、基因信息等,预测患者罹患某种疾病的风险。
在许多实际问题中,我们通常需要考虑多个输入特征。虽然 CNN 最初是为图像分类问题设计的,但它也可以应用于回归预测问题。在这种情况下,CNN 的目标不再是预测输入图像的类别,而是预测一个连续的目标值。为此,我们可以将 CNN 的最后一层全连接层修改为输出一个单一的连续值,然后使用一个回归损失函数(如均方误差)来训练网络。
CNN 由于其强大的特征提取能力,特别适合处理这种多变量的回归预测问题。

这篇文章我们就以房价预测为例吧
三、一个简单的案例——波士顿房价预测
下面我们将演示如何使用pytorch实现一个卷积神经网络(CNN)来进行波士顿房价的多变量回归预测。我们将使用波士顿房价数据集来训练我们的模型,该数据集包含波士顿城郊区域的房屋的多个特性(如犯罪率、房间数量、教师学生比例等)和房价。如下图每组房价数据由13个相关属性(即13个指标变量),1个目标变量(房价)组成,总共有506组数据,即为506*14的数组。
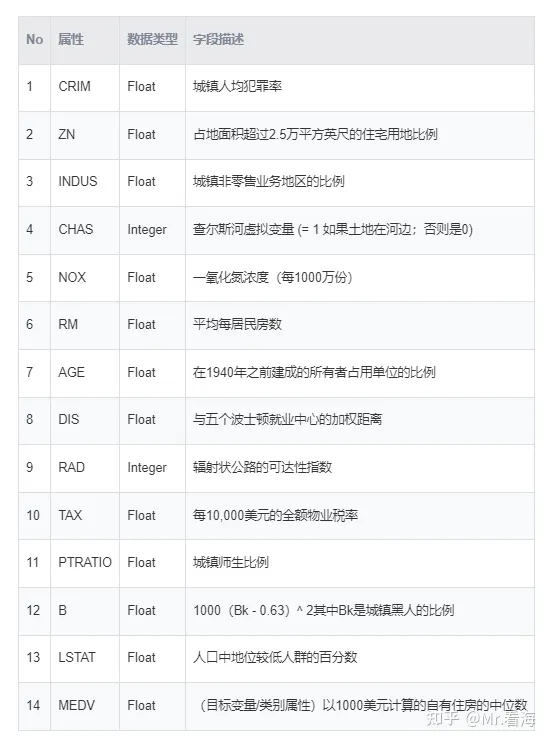
房价数据
下边代码我将详细讲解逐行写到注释当中,为了增加可读性,正文文字仅做流程讲解。
0. 安装必要的库并导入
如果大家使用上述环境搭建方法,使用了conda的环境,则不需要再额外安装库。如果不是的话,你可能会需要安装numpy,torch和sklearn等。
安装好之后,代码中导入必要的库:
import numpy as np
# 导入NumPy库,用于数组操作和数值计算
import torch
# 导入PyTorch库,用于构建和训练神经网络模型
import torch.nn as nn
# 导入torch.nn模块,其中包含了各种神经网络层和损失函数
import torch.optim as optim
# 导入torch.optim模块,其中包含了各种优化算法
from torch.utils.data import DataLoader, TensorDataset
# 从torch.utils.data模块中导入DataLoader和TensorDataset类
# DataLoader用于创建数据加载器,实现批量读取和数据打乱等功能
# TensorDataset用于将数据封装成数据集对象,便于传递给DataLoader
import matplotlib.pyplot as plt
# 导入Matplotlib的pyplot模块,用于绘制图形和可视化结果
from sklearn.preprocessing import MinMaxScaler
# 从scikit-learn库的preprocessing模块中导入MinMaxScaler类
# MinMaxScaler用于对数据进行最小-最大归一化,将数据缩放到[0, 1]的范围内1. 数据预处理
首先,我们从 'housing.txt' 中读取数据。
# 读取数据
data = np.loadtxt('housing.txt')
# 使用NumPy的loadtxt函数从文件'housing.txt'中读取数据
# 假设数据文件的格式为每行代表一个样本,不同的特征值和目标值之间用空格或制表符分隔
# 读取的数据将被存储在NumPy数组data中
X = data[:, :13]
# 数据集中前13列是输入特征,每一行代表一个样本,每一列代表一个特征
# data[:, :13]表示选取数组的所有行和前13列
y = data[:, 13]
# 通过数组切片操作,将数据的第14列提取出来,赋值给变量y
# 这里假设数据集中第14列是目标值,即我们要预测的房价然后将输入和输出数据进行归一化处理。数据归一化的目的是将不同特征的值缩放到相似的范围,以提高模型的收敛速度和性能。这在处理具有不同量纲或范围的特征时尤为重要。
# 数据归一化处理
scaler_x = MinMaxScaler()
# 创建一个MinMaxScaler对象scaler_x,用于对输入特征X进行归一化处理
# MinMaxScaler会将数据缩放到[0, 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7022
7022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











