







InfoGAN论文理解及复现
by AHU Random_Walker
主要从四个方面来了解相关工作,即
- Motivation
- Related Work-Method
- Experiments
- Conclusion
然后有三个过程来复现代码,最后的疑问算是对整个框架和代码细节问题的汇总吧
- 框架
- 代码实现与结果
- 总结与疑问
参考的资料
https://arxiv.org/abs/1606.03657
https://study.163.com/course/courseMain.htm?courseId=1005703030
Motivation
InfoGAN全称是Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets,是NIPS2016的工作。
infoGAN的动机是什么呢?就是原始Gan没有对生成器如何使用噪声做出约束,训练出来的生成器,对于 z z z的每一个维度不能够很好的对应到相关的语义特征。而infoGAN可以找到这种语义特征。
先来直观感受一下:

可以看到通过调节参数 c c c,生成的数字可以分类、旋转、调整宽度。相当于是说通过了无监督的形式,学习到了参数和特征的分布关系。
其方法是通过加入一个(多个)新的变量 c c c,使得 c c c与生成的样本有较高的互信息。
这样 c c c就可以用于表示数据某个方面的语义信息,而 z z z 用于表示样本 x x x中与 c c c无关的其它信息。
宏观上看,最后 i n f o G A N infoGAN infoGAN可以看成三个网络的组成:
- 生成网络 x = G ( z , c ) x=G(z,c) x=G(z,c)
- 判别真伪的网络 y 1 = D 1 ( x ) y_1=D_1(x) y1=D1(x)
- 判别类别 c c c的网络 y 2 = D 2 ( x ) y_2=D_2(x) y2=D2(x)
需要注意的是, D 1 D_1 D1和 D 2 D_2 D2共享网络的参数(除了最后一层外),所以和原始的GAN相比,infoGAN的时间复杂度是相同量级的,具体后面会说到。
c c c一般分为categorical latent code(分类潜码)和continuous latent code(连续潜码),取决于最后是要分类还是连续的特征参数。当 c c c用于代表类别信息的时候,网络最后一层是 s o f t m a x softmax softmax层。
Related Work-Method
由于笔者目前知识水平有限,论文中提到的一些早期(2016年之前)的模型和方法就不介绍了。主要介绍这篇论文的工作,当然是基于14年Goodfellow et al.原始GAN的工作之上了。
首先是mutual information 的概念。
互信息 mutual information
我们定义 H ( x ) = ∑ − P ( x ) l o g P ( x ) = E [ − l o g P ( x ) ] H(x)=\sum-P(x)logP(x)=E[-logP(x)] H(x)=∑−P(x)logP(x)=E[−logP(x)]
而互信息
I
(
X
;
Y
)
I(X;Y)
I(X;Y)可以用于衡量随机变量
X
X
X中包含随机变量
Y
Y
Y的信息量
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
=
I
(
Y
;
X
)
I(X;Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)=I(Y;X)
I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)=I(Y;X)

I ( X ; Y ) I(X;Y) I(X;Y) 值越大,则 X X X中包含 Y Y Y的信息就越多。如果 X , Y X,Y X,Y相互独立,那么 I ( X , Y ) = 0 I(X,Y)=0 I(X,Y)=0,反之如果 X X X和 Y Y Y相关性较大,则 , I ( X , Y ) ,I(X,Y) ,I(X,Y)也较大。
这个过程也可以理解为,当 Y Y Y有了观测值后, X X X的不确定性越低,则 I ( X ; Y ) I(X;Y) I(X;Y) 值越大。
本文提出把输入噪声向量分成两部分:
- z,即原始的噪声,不可压缩的噪声。
- c,文中称为latent code ,对应语义向量,可以有多个 c 1 , c 2 , . . . c_1,c_2,... c1,c2,...,这些变量相互独立,则 p ( c 1 , c 2 , . . . c L ) = ∏ i = 1 L p ( c i ) p(c_1,c_2,...c_L)=\prod_{i=1}^{L}p(c_i) p(c1,c2,...cL)=∏i=1Lp(ci) 。为了方便,下文统一用 c c c表示。
现在,我们打算以一种无监督学习的方式,发现这些latent code如何影响生成的图片,以达到我们想要的上面的效果。
我们把 z z z和 c c c都提供给生成器 G G G,记为 G ( z , c ) G(z,c) G(z,c) 。然而,在标准的GAN中,直接将z,c在一起训练的话,生成器将忽略潜变量 c c c的作用,即 P G ( x ∣ c ) = P G ( x ) P_G(x|c)=P_G(x) PG(x∣c)=PG(x),表明变量 c c c和 x x x相互独立。为了使 x x x受 c c c的指定影响,文献提出信息正则化约束项:潜变量 c c c与生成样本 G ( z , c ) G(z,c) G(z,c)的互信息量应该较大,即 I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c)) 应该较大。
为此,在原始Gan损失函数V(D,G)的基础上,加入正则约束 I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c)),现在的博弈变成这个样子:

Variational Mutual Information Maximization
如何最大化上式中的互信息呢?
实际上, I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c))很难直接最大化,因为他需要获得后验概率项 P ( c ∣ x ) P(c|x) P(c∣x) (为什么是这个,后面化简可以看出)
幸运的是,我们可以通过一个辅助分布 Q ( c ∣ x ) Q(c|x) Q(c∣x),获得一个 P ( c ∣ x ) P(c|x) P(c∣x)的下界,从而得到 P ( c ∣ x ) P(c|x) P(c∣x)的近似解:

怎么理解上面的式子呢?
x x x是 G ( z , c ) G(z,c) G(z,c)的观测值,而记 c ′ c' c′ 是一个后验概率的观测值,即 c ′ ∼ P ( c ∣ x ) c'\sim P(c|x) c′∼P(c∣x)
由于 H ( x ) = ∑ − P ( x ) l o g P ( x ) = E [ − l o g P ( x ) ] H(x)=\sum-P(x)logP(x)=E[-logP(x)] H(x)=∑−P(x)logP(x)=E[−logP(x)] ,
则 − H ( c ∣ G ( z , c ) ) = − E [ − l o g P ( c ∣ G ( z , c ) ) ] = E x ∼ G ( z , c ) [ E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) ] ] -H(c|G(z,c))=-E[-logP(c|G(z,c))]=E_{x\sim G(z,c)}[E_{c'\sim P(c|x)}[logP(c'|x)]] −H(c∣G(z,c))=−E[−logP(c∣G(z,c))]=Ex∼G(z,c)[Ec′∼P(c∣x)[logP(c′∣x)]] 注意负号消去了
然后我们从 E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) ] E_{c'\sim P(c|x)}[logP(c'|x)] Ec′∼P(c∣x)[logP(c′∣x)] 中分解出一项“误差项”
即 E c ′ ∼ P ( c ∣ x ) [ l o g P ( c ′ ∣ x ) ] = D K L ( P ( ⋅ ∣ x ) ∣ ∣ Q ( ⋅ ∣ x ) ) ) + E c ′ ∼ P ( c ∣ x ) [ l o g Q ( c ′ ∣ x ) ] E_{c'\sim P(c|x)}[logP(c'|x)]=D_{KL}(P(\cdot|x) \ ||\ Q(\cdot|x)))+E_{c'\sim P(c|x)}[logQ(c'|x)] Ec′∼P(c∣x)[logP(c′∣x)]=DKL(P(⋅∣x) ∣∣ Q(⋅∣x)))+Ec′∼P(c∣x)[logQ(c′∣x)]
而 D K L ( P ( ⋅ ∣ x ) ∣ ∣ Q ( ⋅ ∣ x ) ) ) ≥ 0 D_{KL}(P(\cdot|x) \ ||\ Q(\cdot|x))) \ge 0 DKL(P(⋅∣x) ∣∣ Q(⋅∣x)))≥0
因此,下界就是

这种操作应该也是比较经典的方法,也不是infogan的作者提出的,This technique of lower bounding mutual information is known as Variational Information Maximization [26].
然后,潜码的 H ( c ) H(c) H(c)也可以被优化,因为它具有常见分布的简单解析形式。而在这篇文章中,作者将为了简化,将 H ( c ) H(c) H(c)视为常数处理。(想一想为什么可以当做常数?)
到现在为止,我们解决了 I ( c ; G ( z , c ) ) I(c;G(z,c)) I(c;G(z,c))显式计算的问题(通过找到问题的下界),但是我们还需要从后验样本中取样计算,(因为要计算多个 c ′ c' c′),可不可以简化这个过程呢?
然后作者使用了一个引理,从而不需要上述计算。

有了这个lemma,我们对之前的下界得到一个变分公式 L 1 L_1 L1 :

这个式子用Lemma很好证明(替换一下即可)。而关于lemma本身的证明referred to论文的Appendix 1。
然后你发现 c ′ c' c′没了。。这应该是本文的关键点之一
注意到, L 1 ( G , Q ) L_1(G,Q) L1(G,Q)很容易用蒙特卡洛方法近似估计(对 c c c和 x x x进行采样即可),具体来说,对于 Q Q Q,可以直接将 L 1 L_1 L1最大化,而对于 G G G,可以使用reparametrization trick(重参数化技巧)来最大化。reparametrization trick经常用于蒙特卡洛估计中,具体可以参见http://blog.shakirm.com/2015/10/machine-learning-trick-of-the-day-4-reparameterisation-tricks/。
此外,当 c c c是离散值时,如果 L 1 ( G , Q ) = H ( c ) L_1(G,Q)=H(c) L1(G,Q)=H(c),那么这个下界取到了最大值。(想一想为什么,连续值呢?)
在附录中,论文作者还指出了infoGAN与Wake-Sleep algorithm[27]的关联,其也提供了另外一种解释。
因此,最终InfoGAN被定义为如下的极大极小博弈:(变分互信息正则化,翻译比较僵硬…)

简单理解就是,生成器 G G G和判断类别网络 Q Q Q目标是使后面的式子尽量小,一方面是 G G G考虑到“欺骗”D使 V V V尽量小,另一方面是 G , Q G,Q G,Q要把 L 1 L_1 L1搞大,这样 c c c和生成的数据相关性就大,加上负号后,整个式子就小。
而 D D D就要使后面大了。这一点和原始 G A N GAN GAN一样。
Experiments
在实践中,作者将辅助分布 Q Q Q作为神经网络训练来参数化。在多数实验中, Q Q Q和 D D D共享前面所有的卷积层,对于 Q Q Q,最后通过一层全连接层输出参数(在下面复现中,采用了两层全连接)。而且作者提到,L(G; Q) converge的速率比原始GAN的网络要快,所以时间并没有增加多少(一个量级的)。
对于离散分类编码 c c c,使用常见的softmax nonlinearity来表示 Q ( c i ∣ x ) Q(c_i|x) Q(ci∣x),在下面的代码实现中采用的是交叉熵方法来计算 l o s s loss loss;
对于连续特征编码 c c c,作者说简单把 Q ( c j ∣ x ) Q(c_j|x) Q(cj∣x)看做高斯因素就行,在下面的代码实现中采用的是MSE方法,将高斯分布拉近,从而降低 l o s s loss loss
另外作者说 G A N GAN GAN相对来说比较难以训练,所以他们使用了 D C − G A N DC-GAN DC−GAN中的一些techniques,然后他们也没有什么新的训练trick。
最后关于那个式子中的超参数 λ \lambda λ, 对于离散潜编码c简单的设置为1即可,而对于连续码,应该确保 λ L 1 ( G , Q ) \lambda L_1(G,Q) λL1(G,Q)和 G A N GAN GAN的那些objectives在同一量级上。在后面代码实现中,都视作为1了,之后可以对连续尝试不同的数值。
关于Batch normalization
1.在实现中,D的第一层、G的最后一层分别通过卷积、反卷积时不进行batch normalization,因为会造成样本震荡和模型的不稳定。
2.Batch normalization的计算公式是 y = γ ( x − μ ) σ + β y=\frac{\gamma(x-\mu)}{\sigma }+\beta y=σγ(x−μ)+β , y y y是输出, μ \mu μ是均值, σ \sigma σ是方差, 和 γ 和 β 和\gamma和\beta 和γ和β是缩放、偏移系数。 μ \mu μ和 σ \sigma σ在 训练时使用的是一个batch数据的统计值,但是测试时,采用的是训练时计算出的滑动平均值。
3.在训练时注意将training设置为True,而在测试是设为False,并reuse设为True
优化时,添加以下代码进行 μ \mu μ和 σ \sigma σ的滑动平均值的更新操作:

框架
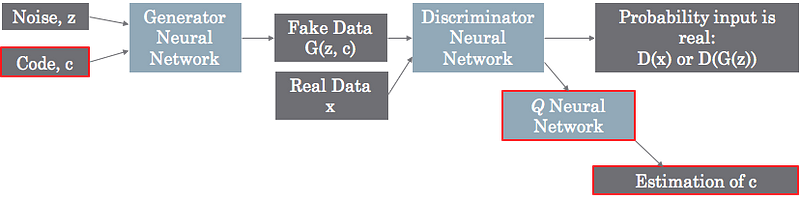
代码实现与结果
环境
- win10
- python 3.6
- TensorFlow 1.10 (截至8.30.2018最新版本)
- CUDA 9.0 cudnn7.1
代码
共有四个文件
- main.py
- infoGAN.py
- ops.py #Most codes from https://github.com/carpedm20/DCGAN-tensorflow
- utils.py #Most codes from https://github.com/carpedm20/DCGAN-tensorflow
其中,只有infoGAN是具体的关于本文的实现,main.py配置一些用户参数,ops.py和utils.py是一些文件路径管理、图片操作和优化方法。
from infoGAN import infoGAN
from utils import show_all_variables
from utils import check_folder
import tensorflow as tf
import argparse
import os
def parse_args():
desc = "Tensorflow implementation of GAN collections"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--gan_type', type=str, default='infoGAN',
choices=['infoGAN'],
help='The type of GAN', required=False)
parser.add_argument('--dataset', type=str, default='mnist',
choices=['mnist', 'fashion-mnist', 'celebA'],
help='The name of dataset')
parser.add_argument('--epoch', type=int, default=7,
help='The number of epochs to run')
parser.add_argument('--batch_size', type=int, default=64,
help='The size of each batch')
parser.add_argument('--z_dim', type=int, default=62,
help='Dimension of noise vector')
parser.add_argument('--checkpoint_dir', type=str, default='checkpoint',
help='The directory name to save the checkpoints')
parser.add_argument('--result_dir', type=str, default='results',
help='The directory name to save the generated images')
parser.add_argument('--log_dir', type=str, default='logs',
help='The directory name to save training logs')
return check_args(parser.parse_args())
# checking arguments
def check_args(args):
# --checkpoint_dir
check_folder(args.checkpoint_dir)
# --result_dir
check_folder(args.result_dir)
# --log_dir
check_folder(args.log_dir)
# --epoch
assert args.epoch >= 1, 'number of epochs must be larger than or equal to one'
# --batch_size
assert args.batch_size >= 1, 'batch size must be larger than or equal to one'
# --z_dim
assert args.z_dim >= 1, 'dimension of noise vector must be larger than or equal to one'
return args
def main():
args = parse_args()
if args is None:
print("args is None")
exit()
# open session
models = [infoGAN] # 导入infoGAN中的对象
# GPU settings
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
gpu_options = tf.GPUOptions(allow_growth=True)
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
# declare instance for GAN
gan = None
for model in models:
if args.gan_type == model.model_name:
gan = model(sess,
epoch=args.epoch,
batch_size=args.batch_size,
z_dim=args.z_dim,
dataset_name=args.dataset,
checkpoint_dir=args.checkpoint_dir,
result_dir=args.result_dir,
log_dir=args.log_dir,
SUPERVISED=True,
reload=False)
break
if gan is None:
raise Exception("[!] There is no option for " + args.gan_type)
# build graph
gan.build_model()
# show network architecture
show_all_variables()
# launch the graph in a session
gan.train()
print(" [*] Training finished!")
# visualize learned generator
gan.visualize_results(args.epoch-1)
print(" [*] Testing finished!")
if __name__ == '__main__':
main()
#-*- coding: utf-8 -*-
from __future__ import division
import os
import time
import tensorflow as tf
import numpy as np
from ops import *
from utils import *
class infoGAN(object):
model_name = "infoGAN"
def __init__(self, sess, epoch, batch_size, z_dim, dataset_name, checkpoint_dir,
result_dir, log_dir, SUPERVISED=True, reload=True):
self.sess = sess
self.dataset_name = dataset_name
self.checkpoint_dir = checkpoint_dir
self.result_dir = result_dir
self.log_fir = log_dir
self.epoch = epoch
self.batch_size = batch_size
self.reload = reload
if dataset_name == 'mnist' or dataset_name == 'fashion-mnist':
# parameters
self.input_height = 28
self.input_width = 28
self.output_height = 28
self.output_width = 28
self.z_dim = z_dim # demension of noise-vector
self.y_dim = 12 # dimension of code-vector (label+ two features)
self.c_dim = 1 # channel
# code
self.len_discrete_code = 10 # categorical distribution (i.e. label)
self.len_continuous_code = 2 # gaussian distribution (e.g. rotation, thickness)
self.SUPERVISED = SUPERVISED # if it is true, label info is directly used for code
# train para
self.learning_rate = 0.0002
self.beta1 = 0.5
# test
self.sample_num = 64 # number of generated images to be saved(one time)
# load mnist
self.data_X, self.data_y = load_mnist(self.dataset_name)
# get number of batches for a single epoch
self.num_batches = len(self.data_X) // self.batch_size
else:
print("sure mnist?")
raise NotImplementedError
def generator(self, z ,y, is_training=True, reuse=False):
# [batch_size, z_dim+y_dim] > [batch_size, 1024] > [batch_size, 128*7*7] >
# [batch_size, 7, 7, 128] > [batch_size, 14, 14, 64] > [batch_size, 28, 28, 1]
with tf.variable_scope("generator", reuse=reuse):
# merge noise and code 1是axis 表明是列
z = concat([z, y], 1)
# 注意batch_norm操作
net = tf.nn.relu(bn(linear(z, 1024, scope='g_fc1'), is_training=is_training, scope='g_bn1'))
# 再做一次全连接,为后面反卷积做准备
net = tf.nn.relu(bn(linear(net, 128*7*7, scope='g_fc2'), is_training=is_training, scope='g_bn2'))
net = tf.reshape(net, [self.batch_size, 7, 7, 128])
net = tf.nn.relu(
bn(deconv2d(net, [self.batch_size, 14, 14, 64], 4, 4, 2, 2, name='g_dc3'), is_training=is_training,
scope='g_bn3')
)
# 注意out层不用bn
out = tf.nn.sigmoid(deconv2d(net, [self.batch_size, 28, 28, 1], 4, 4, 2, 2, name='g_dc4'))
return out
def discriminator(self, x, is_training=True, reuse=False):
with tf.variable_scope("discriminator", reuse=reuse):
# 对图片做卷积 和G的反卷积完全相反的过程
net = lrelu(conv2d(x, 64, 4, 4, 2, 2, name='d_conv1'))
net = lrelu(bn(conv2d(net, 128, 4, 4, 2, 2, name='d_conv2'), is_training=is_training, scope='d_bn2'))
net = tf.reshape(net, [self.batch_size, -1]) # 注意-1简化了细节
net = lrelu(bn(linear(net, 1024, scope='d_fc3'), is_training=is_training, scope='d_bn3'))
out_logit = linear(net, 1, scope='d_fc4') # 直接做成1
out = tf.nn.sigmoid(out_logit)
return out, out_logit, net # 这里返回net是为了classifier
def classifier(self, x, is_training=True, reuse=False):
# >[batch_size, 64] > [batch_size, y_dim]
# All layers except the last two layers are shared by discriminator
with tf.variable_scope("classifier", reuse):
net = lrelu(bn(linear(x, 64, scope='c_fc1'), is_training=is_training, scope='c_bn1'))
out_logit = linear(net, self.y_dim, scope='c_fc2')
out = tf.nn.softmax(out_logit) # 对连续标签取softmax不会出问题吗?
return out, out_logit
def build_model(self):
# some parameters
image_dims = [self.input_height, self.input_width, self.c_dim]
bs = self.batch_size
""" Graph Input """
# images
self.inputs = tf.placeholder(tf.float32, [bs]+image_dims, name='real_images')
# labels
self.y = tf.placeholder(tf.float32, [bs, self.y_dim], name='y')
# noises
self.z = tf.placeholder(tf.float32, [bs, self.z_dim], name='z')
""" Loss Function"""
# output of D for real images
D_real, D_real_logits, _ = self.discriminator(self.inputs, is_training=True,
reuse=False)
# output of D for fake images
G = self.generator(self.z, self.y, is_training=True, reuse=False)
D_fake, D_fake_logits, input4classifier_fake = self.discriminator(G, is_training=True,
reuse=True)
# get loss for discriminator (交叉熵)" -[log(D(x)) - log(1-D(G(z,y)))] "
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real_logits, labels=tf.ones_like(D_real))
)
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits, labels=tf.zeros_like(D_fake))
)
self.d_loss = d_loss_real + d_loss_fake
# get loss for generator(交叉熵) " -log(D(G(z,y))) "
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits, labels=tf.ones_like(D_fake))
)
# Information Loss " ? ?~?(?),?~?(?,?)[????(?|?)] + ?(?) "
code_fake, code_logit_fake = self.classifier(input4classifier_fake, is_training=True,
reuse=False)
# discrete code : catogorical 交叉熵
disc_code_est = code_logit_fake[:, :self.len_discrete_code] # 取出数据
disc_code_tg = self.y[:, :self.len_discrete_code] # 取出标签
q_disc_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=disc_code_est,
labels=disc_code_tg)) # 与所给y的交叉熵
# continuous code : gaussian (MSE: 高斯分布拉近)
cont_code_est = code_logit_fake[:, self.len_discrete_code:]
cont_code_tg = self.y[:, self.len_discrete_code:]
q_cont_loss = tf.reduce_mean(tf.reduce_sum(tf.square(cont_code_tg - cont_code_est), axis=1)) # 对列求和后取平均
# get information loss
self.q_loss = q_disc_loss + q_cont_loss
"""Training"""
# divide trainable variables into a group for D and a group for G and for Q
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]
g_vars = [var for var in t_vars if 'g_' in var.name]
# 注意q的loss 会影响三个网络
q_vars = [var for var in t_vars if ('d_' in var.name) or ('q_' in var.name) or ('g_' in var.name)]
#optimizers
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
self.d_optim = tf.train.AdamOptimizer(self.learning_rate, beta1=self.beta1) \
.minimize(self.d_loss, var_list=d_vars)
self.g_optim = tf.train.AdamOptimizer(self.learning_rate * 5, beta1=self.beta1) \
.minimize(self.g_loss, var_list=g_vars)
self.q_optim = tf.train.AdamOptimizer(self.learning_rate * 5, beta1=self.beta1) \
.minimize(self.q_loss, var_list=q_vars)
""" test """
# for test 不训练,reuse之前的参数
self.fake_images = self.generator(self.z, self.y, is_training=False, reuse=True)
"""Summary"""
d_loss_real_sum = tf.summary.scalar("d_loss_real", d_loss_real)
d_loss_fake_sum = tf.summary.scalar("d_loss_fake", d_loss_fake)
d_loss_sum = tf.summary.scalar("d_loss", self.d_loss)
g_loss_sum = tf.summary.scalar("g_loss", self.g_loss)
q_loss_sum = tf.summary.scalar("q_loss", self.q_loss)
q_disc_sum = tf.summary.scalar("q_disc_loss", q_disc_loss)
q_cont_sum = tf.summary.scalar("q_cont_loss", q_cont_loss)
# final summary operations
self.g_sum = tf.summary.merge([d_loss_fake_sum, g_loss_sum])
self.d_sum = tf.summary.merge([d_loss_real_sum, d_loss_sum])
self.q_sum = tf.summary.merge([q_loss_sum, q_disc_sum, q_cont_sum])
def train(self):
# initialize all variables
tf.global_variables_initializer().run()
# graph inputs for visualize training results
self.sample_z = np.random.uniform(-1, 1, size=(self.batch_size, self.z_dim))
self.test_labels = self.data_y[0:self.batch_size]
self.test_codes = np.concatenate((self.test_labels, np.zeros([self.batch_size, self.len_continuous_code])),
axis=1) # 连起来
# saver to save model
self.saver = tf.train.Saver()
# summary writer
self.writer = tf.summary.FileWriter(self.log_fir + '/' + self.model_name + '/' + self.dataset_name, self.sess.graph)
# restore check-point if it exits
could_load, checkpoint_counter = self.load(self.checkpoint_dir)
if could_load and self.reload:
start_epoch = (int)(checkpoint_counter / self.num_batches)
start_batch_id = checkpoint_counter - start_epoch * self.num_batches
counter = checkpoint_counter
print(" [*] load SUCCESS")
# 重新训练所有
else:
start_epoch = 0
start_batch_id = 0 # 每个epoch中的第几块batch
counter = 1
print(" [!] reload from begin")
#loop for epoch
start_time = time.time()
for epoch in range(start_epoch, self.epoch):
#get batch data 每一个batch更新一次网络的参数
for idx in range(start_batch_id, self.num_batches):
batch_images = self.data_X[idx * self.batch_size : (idx+1) * self.batch_size] # real data
# generate codes
if self.SUPERVISED == True:
batch_labels = self.data_y[idx * self.batch_size : (idx+1) * self.batch_size] #用对应的标签
else:
batch_labels = np.random.multinomial(1, self.len_discrete_code * [float(1.0 / self.len_discrete_code)],
size=[self.batch_size])
# batch_codes 和 batch_z 分别传入
batch_codes = np.concatenate((batch_labels, np.random.uniform(-1, 1, size=(self.batch_size, 2))), axis=1)
batch_z = np.random.uniform(-1, 1, [self.batch_size, self.z_dim]).astype(np.float32)
# update G network
_, summary_str_g, g_loss = self.sess.run(
[self.g_optim, self.g_sum, self.g_loss],
feed_dict={self.inputs: batch_images, self.z: batch_z, self.y: batch_codes}
)
self.writer.add_summary(summary_str_g, counter)
# update D and Q network
_, summary_str_d, d_loss, _, summary_str_q, q_loss = self.sess.run(
[self.d_optim, self.d_sum, self.d_loss, self.q_optim, self.q_sum, self.q_loss],
feed_dict={self.inputs: batch_images, self.z: batch_z, self.y: batch_codes}
)
self.writer.add_summary(summary_str_d, counter)
self.writer.add_summary(summary_str_q, counter)
# display training status
counter +=1
print("Epoch: [%2d] [%4d/%4d] time: %4.4f, d_loss: %.8f, g_loss: %.8f" \
% (epoch, idx, self.num_batches, time.time() - start_time, d_loss, g_loss))
# save training results for every 300 steps
if np.mod(counter, 300) == 0:
samples = self.sess.run(self.fake_images,
feed_dict={self.z: self.sample_z, self.y: self.test_codes})
# 一次多少张图片 如果比batch_size大则取batch_size
tot_num_samples = min(self.sample_num, self.batch_size)
manifold_h = int(np.floor(np.sqrt(tot_num_samples)))
manifold_w = int(np.floor(np.sqrt(tot_num_samples)))
save_images(samples[:manifold_h * manifold_w, :, :, :], [manifold_h, manifold_w],
'./' + check_folder(self.result_dir + '/' + self.model_dir) + '/' + self.model_name + '_train_{:02d}_{:04d}.png'.format(
epoch, idx))
# After an epoch, start_batch_id is set to zero
# non-zero value is only for the first epoch after loading pre-trained model
start_batch_id = 0
# save model
self.save(self.checkpoint_dir, counter)
# show temporal results
self.visualize_results(epoch)
# save model for final step
self.save(self.checkpoint_dir, counter)
def visualize_results(self, epoch):
tot_num_samples = min(self.sample_num, self.batch_size)
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
""" random noise, random discrete code, fixed continuous code """
y = np.random.choice(self.len_discrete_code, self.batch_size) #1*batch_size的行向量 每一个范围是[0,len_discrete_code-1]
y_one_hot = np.zeros((self.batch_size, self.y_dim)) # y_dim初始化为12
y_one_hot[np.arange(self.batch_size), y] = 1 #一个trick 方便的置1
z_sample = np.random.uniform(-1, 1, size=(self.batch_size, self.z_dim))
samples = self.sess.run(self.fake_images, feed_dict={self.z: z_sample, self.y: y_one_hot})
save_images(samples[:image_frame_dim * image_frame_dim, :, :, :], [image_frame_dim, image_frame_dim],
check_folder(self.result_dir + '/' + self.model_dir) + '/' + self.model_name + '_epoch%03d' % epoch + '_test_all_classes.png')
""" random noise, specified discrete code, fixed continuous code """
n_styles = 10 # must be less than or equal to self.batch_size
np.random.seed()
si = np.random.choice(self.batch_size, n_styles)
for l in range(self.len_discrete_code):
y = np.zeros(self.batch_size, dtype=np.int64) + l #指定 l
y_one_hot = np.zeros((self.batch_size, self.y_dim))
y_one_hot[np.arange(self.batch_size), y] = 1
samples = self.sess.run(self.fake_images, feed_dict={self.z: z_sample, self.y: y_one_hot})
# save_images(samples[:image_frame_dim * image_frame_dim, :, :, :], [image_frame_dim, image_frame_dim],
# check_folder(self.result_dir + '/' + self.model_dir) + '/' + self.model_name + '_epoch%03d' % epoch + '_test_class_%d.png' % l)
samples = samples[si, :, :, :]
if l == 0:
all_samples = samples
else:
all_samples = np.concatenate((all_samples, samples), axis=0)
""" save merged images to check style-consistency """
canvas = np.zeros_like(all_samples)
for s in range(n_styles):
for c in range(self.len_discrete_code):
canvas[s * self.len_discrete_code + c, :, :, :] = all_samples[c * n_styles + s, :, :, :]
save_images(canvas, [n_styles, self.len_discrete_code],
check_folder(self.result_dir + '/' + self.model_dir) + '/' + self.model_name + '_epoch%03d' % epoch + '_test_all_classes_style_by_style.png')
""" fixed noise,specified discrete code, gradual change continuous code """
assert self.len_continuous_code == 2
c1 = np.linspace(-1, 1, image_frame_dim)
c2 = np.linspace(-1, 1, image_frame_dim)
xv, yv = np.meshgrid(c1, c2)
xv = xv[:image_frame_dim, :image_frame_dim]
yv = yv[:image_frame_dim, :image_frame_dim]
c1 = xv.flatten()
c2 = yv.flatten()
z_fixed = np.zeros([self.batch_size, self.z_dim])
for l in range(self.len_discrete_code):
y = np.zeros(self.batch_size, dtype=np.int64) + l
y_one_hot = np.zeros((self.batch_size, self.y_dim))
y_one_hot[np.arange(self.batch_size), y] = 1
y_one_hot[np.arange(image_frame_dim*image_frame_dim), self.len_discrete_code] = c1
y_one_hot[np.arange(image_frame_dim*image_frame_dim), self.len_discrete_code+1] = c2
samples = self.sess.run(self.fake_images,
feed_dict={ self.z: z_fixed, self.y: y_one_hot})
save_images(samples[:image_frame_dim * image_frame_dim, :, :, :], [image_frame_dim, image_frame_dim],
check_folder(self.result_dir + '/' + self.model_dir) + '/' + self.model_name + '_epoch%03d' % epoch + '_test_class_c1c2_%d.png' % l)
@property
def model_dir(self):
return "{}_{}_{}_{}".format(
self.model_name, self.dataset_name,
self.batch_size, self.z_dim)
def save(self, checkpoint_dir, step):
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir, self.model_name)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess, os.path.join(checkpoint_dir, self.model_name+'.model'), global_step=step)
def load(self, checkpoint_dir):
import re
print(" [*] Reading checkpoints...")
checkpoint_dir = os.path.join(checkpoint_dir, self.model_dir, self.model_name)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
self.saver.restore(self.sess, os.path.join(checkpoint_dir, ckpt_name))
counter = int(next(re.finditer("(\d+)(?!.*\d)",ckpt_name)).group(0))
print(" [*] Success to read {}".format(ckpt_name))
return True, counter
else:
print(" [*] Failed to find a checkpoint")
return False, 0
"""
Most codes from https://github.com/carpedm20/DCGAN-tensorflow
"""
import math
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops
from utils import *
if "concat_v2" in dir(tf):
def concat(tensors, axis, *args, **kwargs):
return tf.concat_v2(tensors, axis, *args, **kwargs)
else:
def concat(tensors, axis, *args, **kwargs):
return tf.concat(tensors, axis, *args, **kwargs)
def bn(x, is_training, scope):
return tf.contrib.layers.batch_norm(x,
decay=0.9,
updates_collections=None,
epsilon=1e-5,
scale=True,
is_training=is_training,
scope=scope)
def conv_out_size_same(size, stride):
return int(math.ceil(float(size) / float(stride)))
def conv_cond_concat(x, y):
"""Concatenate conditioning vector on feature map axis."""
x_shapes = x.get_shape()
y_shapes = y.get_shape()
return concat([x, y*tf.ones([x_shapes[0], x_shapes[1], x_shapes[2], y_shapes[3]])], 3)
def conv2d(input_, output_dim, k_h=5, k_w=5, d_h=2, d_w=2, stddev=0.02, name="conv2d"):
with tf.variable_scope(name):
w = tf.get_variable('w', [k_h, k_w, input_.get_shape()[-1], output_dim],
initializer=tf.truncated_normal_initializer(stddev=stddev))
conv = tf.nn.conv2d(input_, w, strides=[1, d_h, d_w, 1], padding='SAME')
biases = tf.get_variable('biases', [output_dim], initializer=tf.constant_initializer(0.0))
conv = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape())
return conv
def deconv2d(input_, output_shape, k_h=5, k_w=5, d_h=2, d_w=2, name="deconv2d", stddev=0.02, with_w=False):
with tf.variable_scope(name):
# filter : [height, width, output_channels, in_channels]
w = tf.get_variable('w', [k_h, k_w, output_shape[-1], input_.get_shape()[-1]],
initializer=tf.random_normal_initializer(stddev=stddev))
try:
deconv = tf.nn.conv2d_transpose(input_, w, output_shape=output_shape, strides=[1, d_h, d_w, 1])
# Support for verisons of TensorFlow before 0.7.0
except AttributeError:
deconv = tf.nn.deconv2d(input_, w, output_shape=output_shape, strides=[1, d_h, d_w, 1])
biases = tf.get_variable('biases', [output_shape[-1]], initializer=tf.constant_initializer(0.0))
deconv = tf.reshape(tf.nn.bias_add(deconv, biases), deconv.get_shape())
if with_w:
return deconv, w, biases
else:
return deconv
def lrelu(x, leak=0.2, name="lrelu"):
return tf.maximum(x, leak*x)
def linear(input_, output_size, scope=None, stddev=0.02, bias_start=0.0, with_w=False):
shape = input_.get_shape().as_list()
with tf.variable_scope(scope or "Linear"):
matrix = tf.get_variable("Matrix", [shape[1], output_size], tf.float32,
tf.random_normal_initializer(stddev=stddev))
bias = tf.get_variable("bias", [output_size],
initializer=tf.constant_initializer(bias_start))
if with_w:
return tf.matmul(input_, matrix) + bias, matrix, bias
else:
return tf.matmul(input_, matrix) + bias
"""
Most codes from https://github.com/carpedm20/DCGAN-tensorflow
"""
import math
import random
import pprint
import scipy.misc
import numpy as np
from time import gmtime, strftime
from six.moves import xrange
import matplotlib.pyplot as plt
import os
import gzip
import tensorflow as tf
import tensorflow.contrib.slim as slim
def load_mnist(dataset_name):
data_dir = os.path.join("./data", dataset_name)
def extract_data(filename, num_data, head_size, data_size):
with gzip.open(filename) as bytestream:
bytestream.read(head_size)
buf = bytestream.read(data_size * num_data)
data = np.frombuffer(buf, dtype=np.uint8).astype(np.float)
return data
data = extract_data(data_dir + '/train-images-idx3-ubyte.gz', 60000, 16, 28 * 28)
trX = data.reshape((60000, 28, 28, 1))
data = extract_data(data_dir + '/train-labels-idx1-ubyte.gz', 60000, 8, 1)
trY = data.reshape((60000))
data = extract_data(data_dir + '/t10k-images-idx3-ubyte.gz', 10000, 16, 28 * 28)
teX = data.reshape((10000, 28, 28, 1))
data = extract_data(data_dir + '/t10k-labels-idx1-ubyte.gz', 10000, 8, 1)
teY = data.reshape((10000))
trY = np.asarray(trY)
teY = np.asarray(teY)
X = np.concatenate((trX, teX), axis=0)
y = np.concatenate((trY, teY), axis=0).astype(np.int)
seed = 547
np.random.seed(seed)
np.random.shuffle(X)
np.random.seed(seed)
np.random.shuffle(y)
# 变为向量
y_vec = np.zeros((len(y), 10), dtype=np.float)
for i, label in enumerate(y):
y_vec[i, y[i]] = 1.0
return X / 255., y_vec
def check_folder(dir):
if not os.path.exists(dir):
os.makedirs(dir)
return dir
def show_all_variables():
model_vars = tf.trainable_variables()
slim.model_analyzer.analyze_vars(model_vars, print_info=True)
def get_image(image_path, input_height, input_width, resize_height=64, resize_width=64, crop=True, grayscale=False):
image = imread(image_path, grayscale)
return transform(image, input_height, input_width, resize_height, resize_width, crop)
def save_images(images, size, image_path):
return imsave(inverse_transform(images), size, image_path)
def imread(path, grayscale=False):
if (grayscale):
return scipy.misc.imread(path, flatten=True).astype(np.float)
else:
return scipy.misc.imread(path).astype(np.float)
def merge_images(images):
return inverse_transform(images)
def merge(images, size):
h, w = images.shape[1], images.shape[2]
if (images.shape[3] in (3, 4)):
c = images.shape[3]
img = np.zeros((h * size[0], w * size[1], c))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w, :] = image
return img
elif images.shape[3] == 1:
img = np.zeros((h * size[0], w * size[1]))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j * h:j * h + h, i * w:i * w + w] = image[:, :, 0]
return img
else:
raise ValueError('in merge(images,size) images parameter ''must have dimensions: HxW or HxWx3 or HxWx4')
def imsave(images, size, path):
image = np.squeeze(merge(images, size))
return scipy.misc.imsave(path, image)
def center_crop(x, crop_h, crop_w, resize_h=64, resize_w=64):
if crop_w is None:
crop_w = crop_h
h, w = x.shape[:2]
j = int(round((h - crop_h)/2.))
i = int(round((w - crop_w)/2.))
return scipy.misc.imresize(x[j:j+crop_h, i:i+crop_w], [resize_h, resize_w])
def transform(image, input_height, input_width, resize_height=64, resize_width=64, crop=True):
if crop:
cropped_image = center_crop(image, input_height, input_width, resize_height, resize_width)
else:
cropped_image = scipy.misc.imresize(image, [resize_height, resize_width])
return np.array(cropped_image)/127.5 - 1.
def inverse_transform(images):
return (images+1.)/2.
""" Drawing Tools """
# borrowed from https://github.com/ykwon0407/variational_autoencoder/blob/master/variational_bayes.ipynb
def save_scattered_image(z, id, z_range_x, z_range_y, name='scattered_image.jpg'):
N = 10
plt.figure(figsize=(8, 6))
plt.scatter(z[:, 0], z[:, 1], c=np.argmax(id, 1), marker='o', edgecolor='none', cmap=discrete_cmap(N, 'jet'))
plt.colorbar(ticks=range(N))
axes = plt.gca()
axes.set_xlim([-z_range_x, z_range_x])
axes.set_ylim([-z_range_y, z_range_y])
plt.grid(True)
plt.savefig(name)
# borrowed from https://gist.github.com/jakevdp/91077b0cae40f8f8244a
def discrete_cmap(N, base_cmap=None):
"""Create an N-bin discrete colormap from the specified input map"""
# Note that if base_cmap is a string or None, you can simply do
# return plt.cm.get_cmap(base_cmap, N)
# The following works for string, None, or a colormap instance:
base = plt.cm.get_cmap(base_cmap)
color_list = base(np.linspace(0, 1, N))
cmap_name = base.name + str(N)
return base.from_list(cmap_name, color_list, N)
结果
由于gtx950m算力有限…,只跑了7 epochs,batch size是64,learning_rate = 0.0002
最后的结果如下
不同类全部输出,连续c不变:

0粗细和倾斜程度的变化:

总结与疑问
这是我第二次复现论文,上一篇就是原始gan了...
学习到了很多基本的概念... 比如Batch normalization等
tensorflow的熟练程度很重要,可以极大的提高训练、调参效率,比如设置checkpoint以重载,记录log,summary可视化等 ,这些还需要探索。
另外,程序一开始有warning,(往往是告诉你函数的一些更改),这个交叉熵好像即将弃用。

问题
-
这是一个无监督的方法,就是对于C我可以随机给初值,最后互信息都会很大。然后如果我用输入的real图片的标签(离散)作为 c c c训练,可不可以控制训练好后,恰好 c = 0 c=0 c=0时就输出0的图像呢?
上面的代码尝试了这个,

但是并不对应。因为这个标签只是real的标签,而和这一次你随机的噪声没有关系, G G G生成的确实很像 r e a l real real,然后成功欺骗了 D D D,然后 Q Q Q根据输入 G G G的 c c c优化参数,尽量使 G G G生成的图片和 c c c关系大,但是并不一定生成想要的那个数字。一种粗暴的方法是,最后人工观察,哪个离散值对应哪个数字。
所以,现在 G G G学到了 r e a l real real数据的分布,但原始GAN不知道具体怎么对应分布,只会生成其中某一种,而infoGAN通过训练 c c c,使得指定参数后,可以得到固定的分布,但好像还不知道指定哪个参数能得到指定的分布?
-
1.18.2019 update
采用mnist的标签,使用其对qnet训练,G也对Qnet训练,应该可以映射















 3224
3224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









