






智能小程序单卡介绍
智能小程序单卡是一种搜索特型卡片,具有品牌曝光强势、服务交互便捷等优点,能够帮助开发者获取更多用户关注和转化。
在品牌曝光上,用户搜索小程序名称时,会有三大特型样式展现,尤其是高级卡,占据手机一半屏幕,能快速打动搜索用户心智。
在服务交互上,开发者可自行配置单卡子链,用户一搜即达,能够快速找到、使用、分享相关服务能力。
智能小程序单卡样式
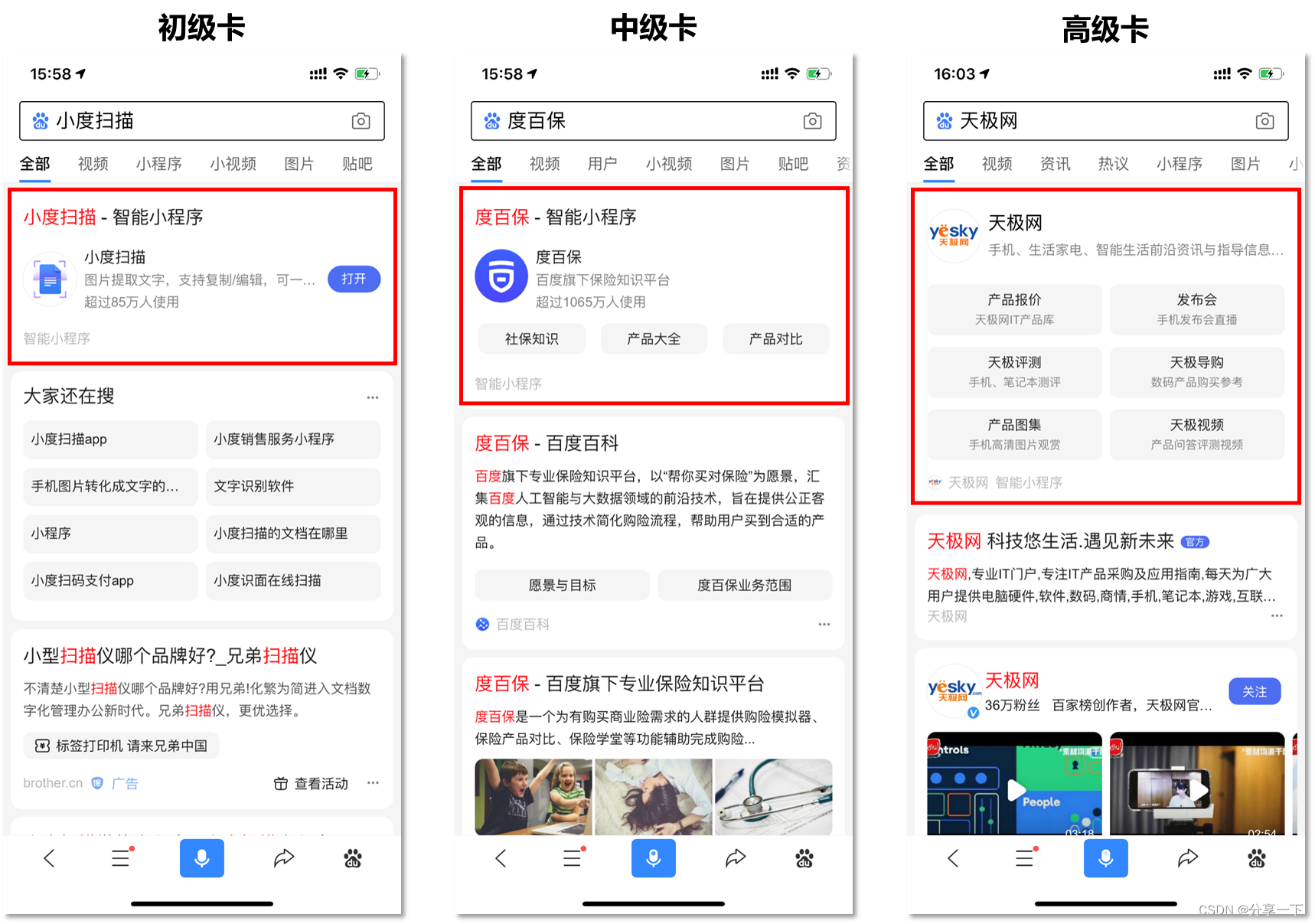
智能小程序单卡获取方式
| 小程序单卡 | 初级卡 | 中级卡 | 高级卡 |
|---|---|---|---|
| 获取方式 | 小程序上线后 24 小时 | 小程序上线后 24 小时 | 小程序达到 A 级 |
| 生效条件 | 无需配置 | 至少 2 条子链审核通过 | 至少 2 条子链审核通过 |
| 子链配置上限 | 0 | 15 | 15 |
| 子链可展现上限 | 0 | 3 | 6 |
| 子链可展现数量 | 0 | 2、3 | 2、4、6 |
智能小程序单卡子链配置方式
操作路径:“百度智能小程序开发者平台 -> 搜索接入 -> 小程序单卡 -> 添加子链”,按提示添加子链信息与 path ,审核通过后即可线上展示给用户。
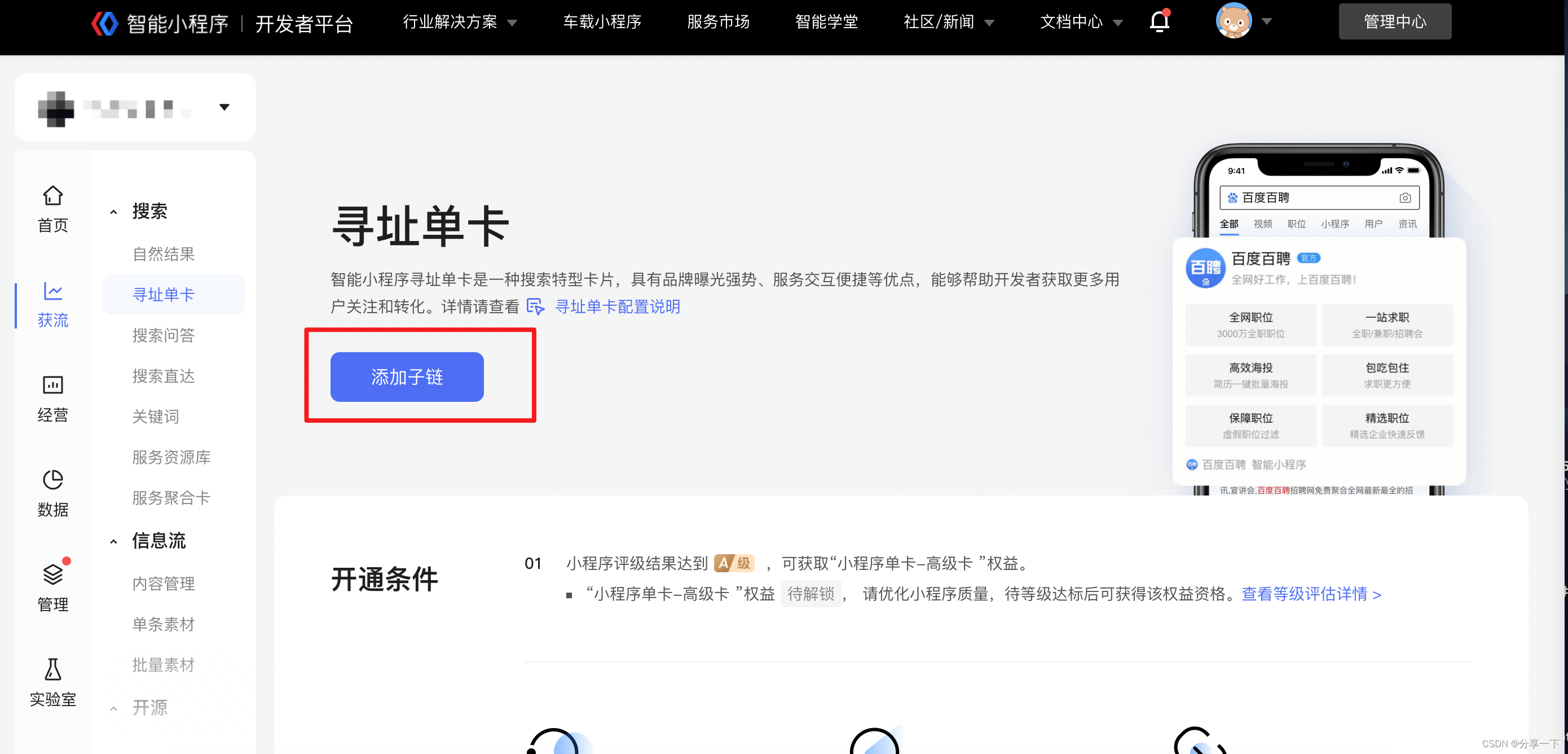
智能小程序单卡子链配置注意事项
-
子链必须为小程序的核心功能页或子频道页,在首页有固定入口,不能为首页、单一商品页、单一内容页。
-
子链标题不超过 10 个字符(即 5 个汉字),子链描述不超过 16 个字符(即 8 个汉字),标题与描述不得重复,子链文案需符合广告法。
-
path 路径即页面路径,与配置 app.json 文件的 pages 字段涵义相同,例如 /pages/ask/index 。
-
至多可提交 15 条子链,至少有 2 条子链审核通过后,线上才会展现子链。
-
审核通过后,排序靠前的子链将优先展现。子链出现异常或用户对其他子链有强需求时,会自动展现其他子链。开发者可自行调整子链排序。
-
子链 path 落地页需功能完善,用户体验优质。

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









