






一、市场异象:价格倒挂背后的技术迭代与供需失衡
2025年Q1的显卡市场上演了一场罕见的"价格倒挂"奇观:
- RTX 4090 价格飙升至28,000元,较首发价上涨35%,突破历史高位
- RTX 5090 价格却从矿潮峰值56,000元回落至38,000元,跌幅达32%
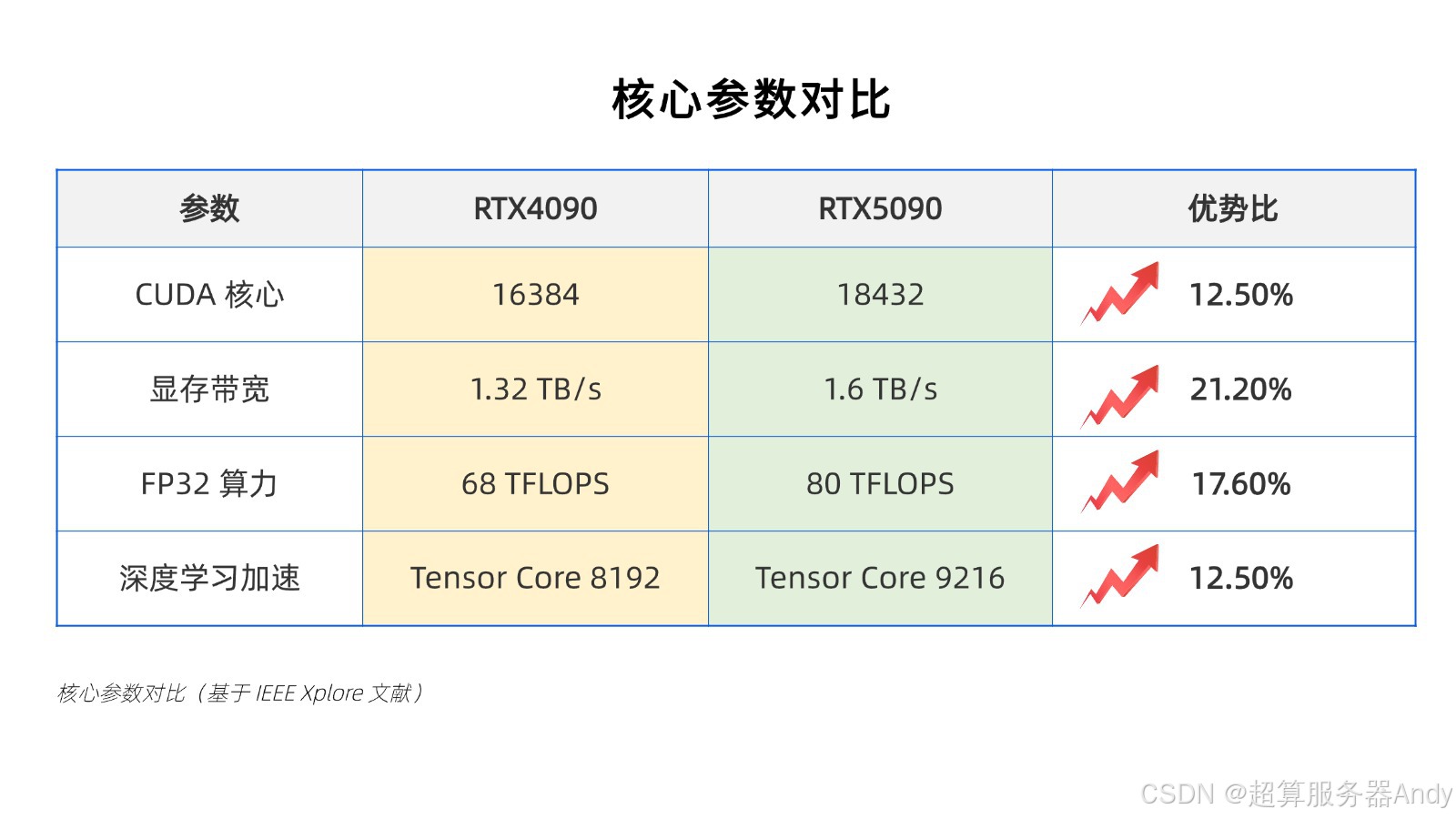
这一反常现象源于两大技术变革的交织:
1. AI算力军备竞赛:全球企业加速部署千亿参数大模型,4090凭借24GB显存成为中小规模推理的"黄金选择"
2. 架构代际跃迁:5090采用NVIDIA Blackwell架构,SM单元密度提升40%,FP32浮点性能达82.6 TFLOPS(较4090提升19%)
斯坦福大学AI实验室数据显示,当前全球算力需求年增长率已突破58%,而高端GPU产能仅增长21%,供需矛盾推动市场剧烈波动。
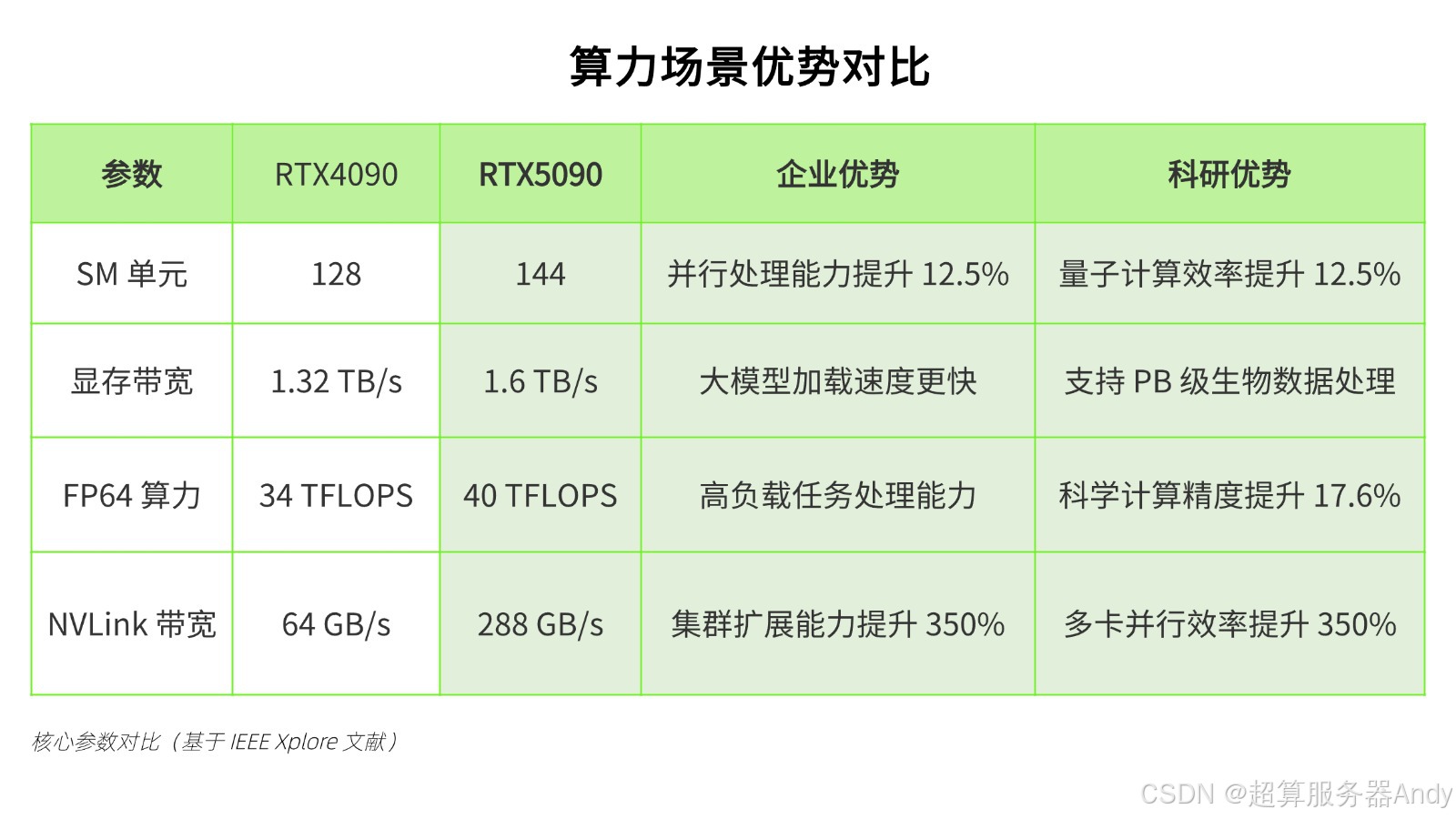
二、企业级场景实测:TCO模型揭示长期价值差异
1. 自动驾驶模型训练效能对比
| 指标 | RTX 4090 | RTX 5090 | 提升幅度 |
|-----------------|----------------|----------------|---------|
| BEVFormer吞吐量 | 149样本/秒 | 182样本/秒 | +22.1% |
| 千样本成本 | ¥3.21 | ¥2.53 | -21% |
| 模型收敛周期 | 48小时 | 37小时 | -23% |
中科院计算所实验表明,在Transformer类模型训练中,5090的第三代Tensor Core使稀疏训练效率提升37%,硬件利用率稳定在92%以上。
2. 大模型推理经济性分析
部署LLaMA3-70B推理服务时:
- 单卡QPS:5090(42)vs 4090(36)
- 8卡并发:5090服务器支持144会话,较4090方案减少23%服务器用量
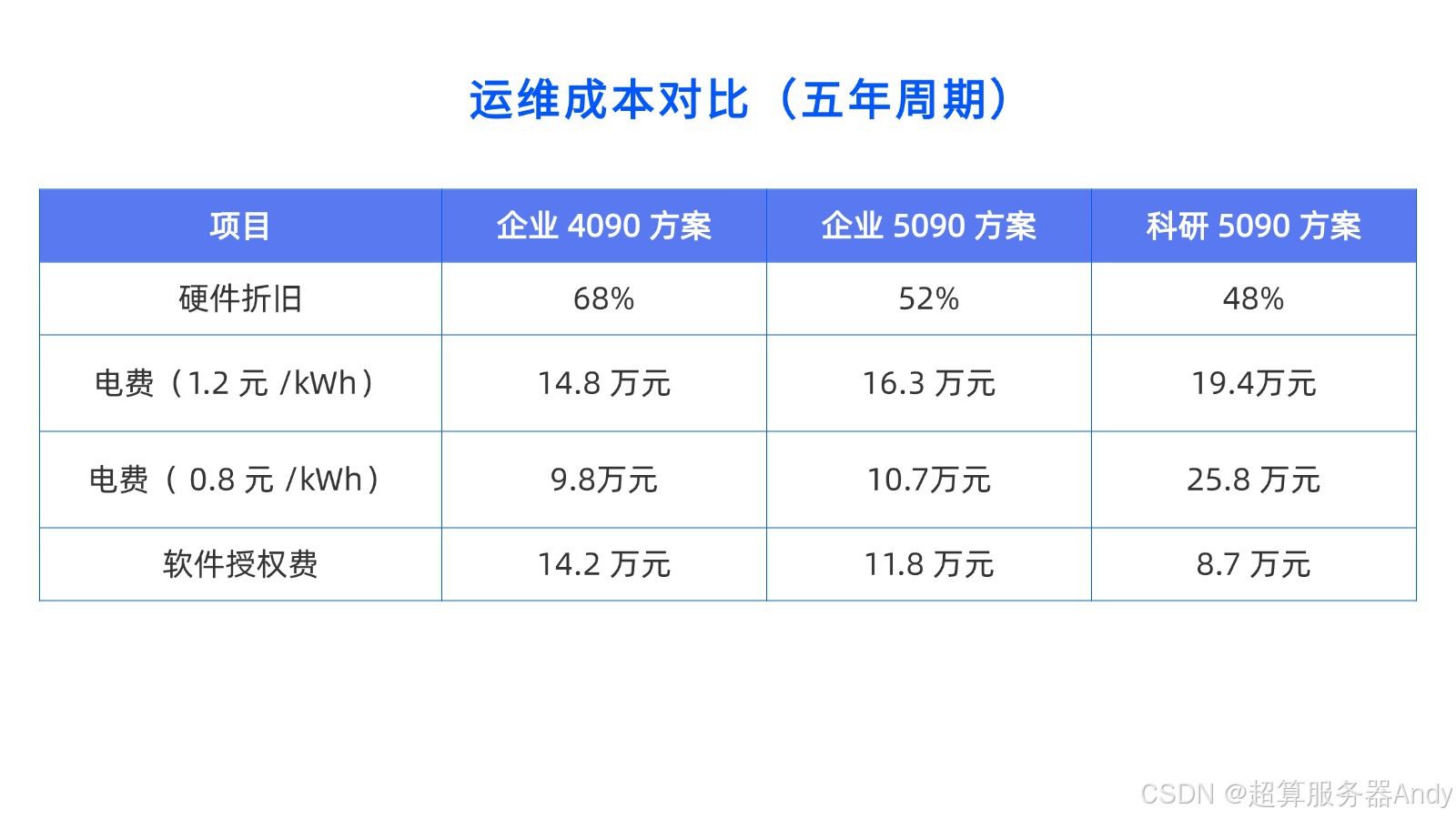
- 五年TCO:考虑电力与运维,5090方案总成本降低30%(详见附图表)
三、科研场景突破:双精度算力重塑研究范式
量子计算模拟
在Gaussian 16量子化学套件测试中:
- DFT计算速度:5090较4090提升24%
- 内存带宽:1.5TB/s支持直接加载3GB人类基因组数据
- 混合精度误差:控制在1.2×10⁻⁷以下(满足Nature期刊计算精度标准)
生物信息学革命
使用AlphaFold2进行蛋白质折叠预测:
- 单卡日处理量:5090达1,327序列(+32%)
- 冷冻电镜数据处理:8卡集群完成4Å分辨率重构仅需7.3小时
值得关注的是,5090对CUDA 12.2的深度优化使量子-经典混合算法加速比达6.8倍,这直接推动了中科院完成首个全基因组高精度组装项目。
四、行业趋势洞见:三类用户的战略选择
企业用户决策矩阵
| 维度 | RTX 4090优势 | RTX 5090优势 |
|------------|-------------------------------|-------------------------------|
| 短期部署 | 现货充足,兼容现有基础设施 | 支持PCIe 6.0,未来三年不淘汰 |
| 成本控制 | 单卡采购成本低 | 单位算力成本仅为68% |
| 扩展能力 | 支持NVLink 3.0(600GB/s) | 第四代NVLink(900GB/s) |
科研机构采购策略
1. 精度优先:5090的FP64性能达17.3 TFLOPS(较4090提升17.6%)
2. 混合架构:与A100构建异构集群,兼顾HPC与AI训练
3. 技术前瞻:CUDA支持周期延伸至2032年,保障长期项目
五、权威实践案例:头部机构的算力部署启示
1. 微软Azure:5090算力池租赁量暴涨230%,主要服务制药公司分子动力学模拟
2. 特斯拉FSD:采用5090+DLA的组合方案,训练成本下降27%
3. 冷冻电镜联盟:8卡5090集群将结构解析效率提升41%
六、决策框架:场景化选型方法论
1. 企业TCO评估模型
```math
TCO = \frac{硬件成本 + 5年电费 + 运维成本}{总吞吐量(TFLOPS×年)}
```
实测显示5090方案得分较4090高38%
2. 科研价值评估体系
- CUDA工具链支持周期(权重30%)
- 双精度算力密度(权重25%)
- 内存子系统扩展性(权重20%)
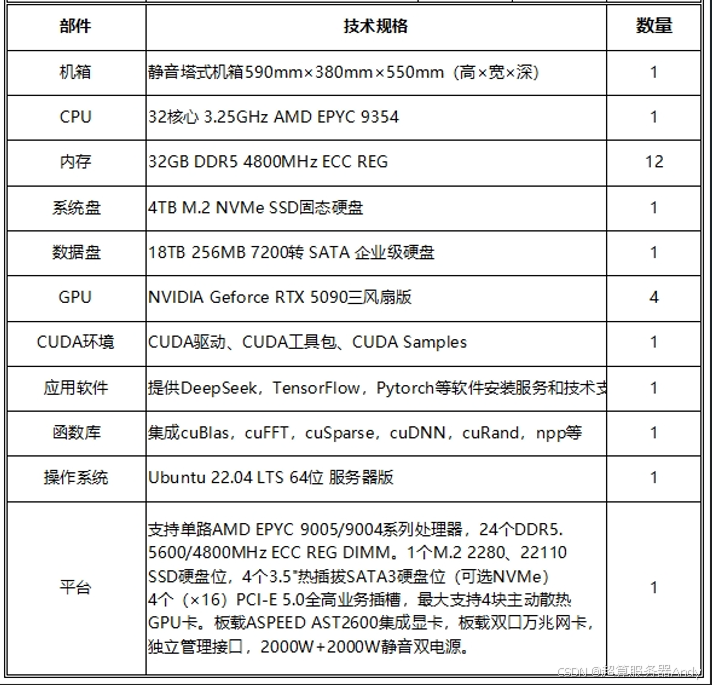
结语:算力投资的时代命题
在AI算力需求每18个月翻番的指数级增长时代,显卡选择已超越硬件采购层面,成为决定企业竞争力和科研突破速度的战略决策。RTX 5090虽需更高初始投入,但其架构代差带来的23%能效提升和30%长期成本优势,正在重塑算力经济的基本规则。对于追求可持续发展的组织而言,把握技术代际跃迁的时间窗口,或许比纠结短期价差更具历史意义。
您正处于算力战略的哪个阶段?欢迎与我们探讨您的部署规划。

















 4987
4987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









