







 这篇博客探讨了无监督学习和监督学习的应用场景和技术。无监督学习中,介绍了硬聚类(如k-均值、k-中心点、层次聚类、自组织映射)和软聚类(如模糊c-均值、高斯混合模型)算法。监督学习部分,讲解了分类(如逻辑回归、kNN、SVM、神经网络)和回归(如线性回归、非线性回归)算法,以及如何改进模型。
这篇博客探讨了无监督学习和监督学习的应用场景和技术。无监督学习中,介绍了硬聚类(如k-均值、k-中心点、层次聚类、自组织映射)和软聚类(如模糊c-均值、高斯混合模型)算法。监督学习部分,讲解了分类(如逻辑回归、kNN、SVM、神经网络)和回归(如线性回归、非线性回归)算法,以及如何改进模型。
应用无监督学习
何时考虑无监督学习
无监督学习适用的场景是,您想要探查数据,但还没有特定目标或不确定数据包含什么信息。这也是减少数据维度的好方法。
无监督学习技术分类
绝大多数无监督学习技术是聚类分析的形式。
在聚类分析中,根据某些相似性的量度或公有特征把数据划分成组。采用聚类的组织形式,同一类(或簇)中的对象非常相似,不同类中的对象截然不同。
聚类算法分为两大类:
- 硬聚类,其中每个数据点只属于一类
- 软聚类,其中每个数据点可属于多类
如果您已经知道可能的数据分组,则可以使用硬聚类或软聚类技术。
如果您不知道数据可能如何分组: - 使用自我组织的特征图或层次聚类,查找数据中可能的结构。
- 使用聚类评估,查找给定聚类算法的”最佳”组数。

常见硬聚类算法
k-均值
工作原理:
将数据分割为k个相互排斥的类。一个点在多大程度上适合划入一个类由该点到类中心的距离来决定。
最佳使用时机:
- 当聚类的数量已知时
- 适用于大型数据集的快速聚类

k-中心点
工作原理:
与k-均值类似,但要求类中心与数据中的点契合。
最佳使用时机:
- 当聚类的数量已知时
- 适用于分类数据的快速聚类
- 扩展至大型数据集

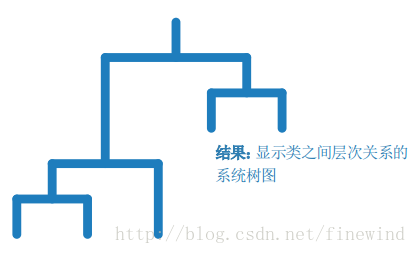
层次聚类
工作原理:
通过分析成对点之间的相似度并将对象分组到一个二进制的层次结构树,产生聚类的嵌套集。
最佳使用时机:
- 当您事先不知道您的数据中有多少类时
- 您想要可视化地指导您的选择
自组织映射
工作原理:
基于神经网络的聚类,将数据集变换为保留拓扑结构的2D图。
最佳使用时机:
- 采用2D或3D方式可视化高维数据
- 通过保留数据的拓扑结构(形状)降低数据维度

常见软聚类算法
模糊c-均值
工作原理:
当数据点可能属于多个类时进行基于分割的聚类。
最佳使用时机:
- 当聚类的数量已知时
- 适用于模式识别
- 当聚类重叠时

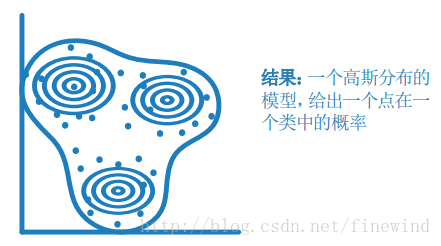
高斯混合模型
工作原理:
基于分割的聚类,数据点来自具有一定概率的不同的多元正态分布。
最佳使用时机:
- 当数据点可能属于多个类时
- 当聚集的类具有不同的大小且含有相关结构时
后续步骤
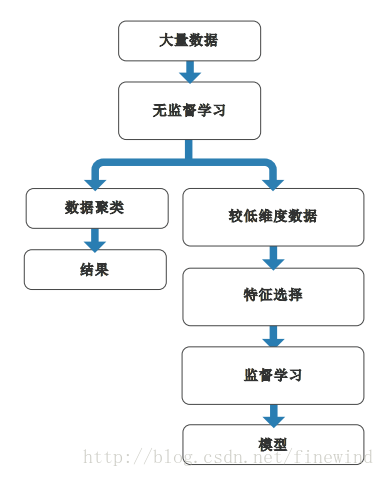
无监督学习可能是您的最终目标。例如:如果您做市场研究并想根据网站行为有针对性地划分消费群体,那么聚类算法几乎肯定能给您想要寻求的结果。
另一方面,您可能想使用无监督学习,作为监督学习的预处理步骤。例如:应用聚类技术得出数量较少的特征,然后使用这些特征作为训练分类器的输入。
应用监督式学习
何时考虑监督式学习
监督式学习算法接受已知的输入数据集合(训练集)和已知的对数据的响应(输出),然后训练一个模型,为新输入数据的响应生成合理的预测。如果您尝试去预测现有数据的输出,则使用监督式学习。
监督学习技术分类
监督学习技术科分为分类或者回归的形式。
分类技术预测离散的响应。
回归技术预测连续的响应。
常见分类算法
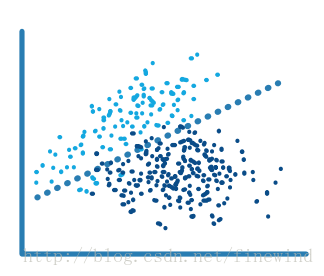
逻辑回归:
工作原理:
适合可以预测属于一个类或者另一个类的二元响应概率的模型。因为逻辑回归比较简单,所以常用作二分类问题的起点。
最佳使用时机:
- 当数据能由一个线性边界清晰划分时
- 作为评估更复杂分类方法的基准
k最近邻(kNN):
工作原理:
kNN根据数据集内类的最近邻关系划分对象的类别。kNN预测假定相互靠近的对象是相似的。距离量度(如欧氏距离、绝对值距离、夹角余弦和Chebychev距离)用来查找最近邻。
最佳使用时机:
- 当您需要简单算法来设立基准学习规则时
- 当无需太关注训练模型的内存使用时
- 当无需太关注训练模型的预测速度时

支持向量机(SVM):
工作原理:
通过搜索能将全部数据点分割开的判别边界(超平面)对数据进行分类。当数据为线性分离时,SVM的最佳超平面是在两个类之间具有最大边距的超平面。如果数据不是线性可分离,则使用损失函数对处于超平面错误一边的点进行惩罚。SVM有时使用核变换,将非线性可分离的数据变换为可找到线性判定边界的更高温度。
最佳使用时机:
- 适用于正好有两个类的数据(借助所谓的纠错输出码技术,也可以将其用于多类分类)
- 适用于高维、非线性可分离的数据
- 当您需要一个简单、易于解释、准确的分类器时

神经网络:
工作原理:
判别分析通过发现特征的线性组合来对数据分类。判别分析假定不同的类根据高斯分布生成数据。训练判别分析模型涉及查找每个类的高斯分布函数。分布参数用来计算边界,边界可能为线性函数或二次函数。这些边界用来确定新数据的类。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 168
168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









