







博文以学习PRML为主,并尽力把其主要内容记录下来,希望大家多多指点。
多项式拟合
首先我们来看一个使用多项式拟合数据的例子,观测集由函数
sin(2πx)
产生, 为了是数据显得更接近真实,通常会对产生的数据加上随机扰动。这里提下,在真实情况下我们搜集到的数据都是有噪声的,所以使模型对观测数据拟合的过分精确反而会造成其泛化能力下降。
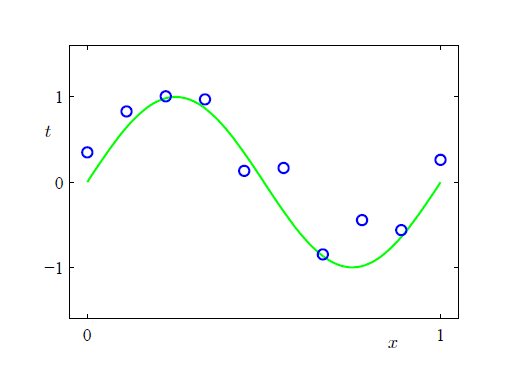
我们的目标是从给定的有限个点拟合出一条曲线使之尽可能的接近图示真实曲线。
其中一个解决办法是使用多项式进行拟合:
注意该多项式函数 y(x,w) 是关于 w 的线性函数。有了基本的模型,我们只需要调节参数
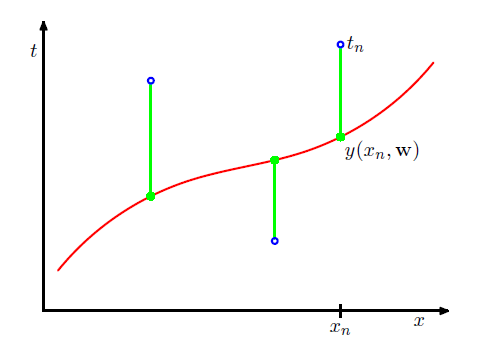
观查表达式可以看出误差函数是关于 w 的二次函数,可以通过求导得到 w 的最优解记为 w∗ ,最终拟合出的多项式函数由 y=(x,w∗) 给出。
那么该如何选择多项式的阶数
M
呢? 我们先通过一个图直观的理解下
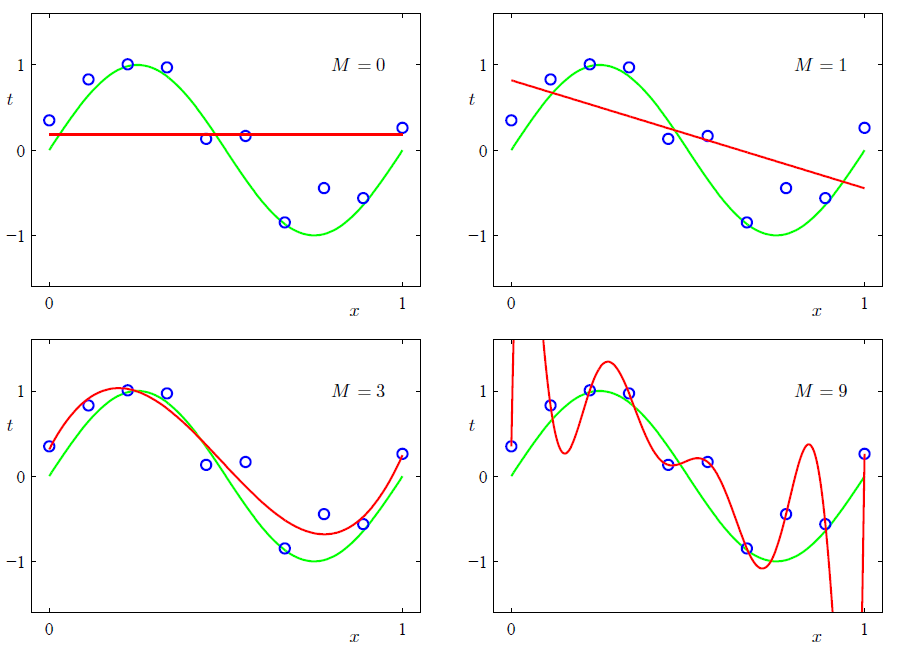
可以看出
M
实际 上在控制模型的复杂度,直观的来看,当
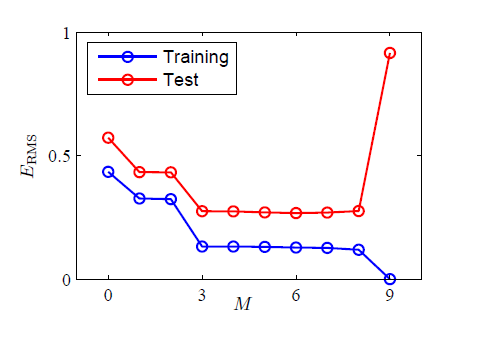
下图展示了不同大小的
M
的泛化能力的强弱。
为什么
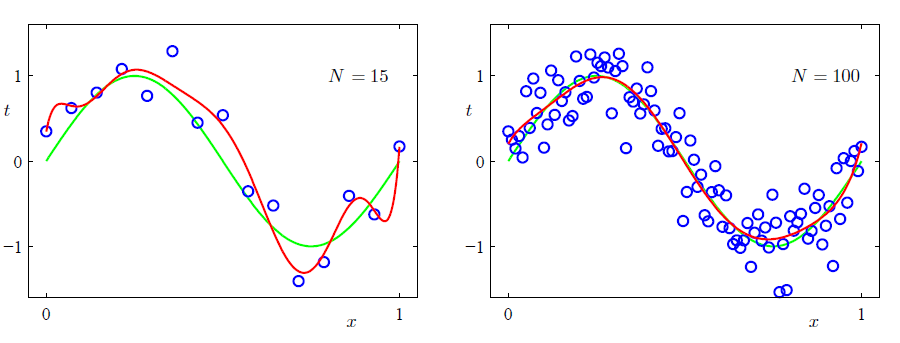
因此我们得到一个粗浅的启发:训练集的数据规模不应低于模型参数的若干倍(5-10倍),但这样会有一个弊端,就是我们不得不根据训练集的规模调整参数的个数。
那么我们如何在有限数据集规模的前提下限制模型的复杂度呢? 一种常用的方法是给误差函数加上一个惩罚项:
系数 λ 则控制着正则化项与误差的平方项之间的比重
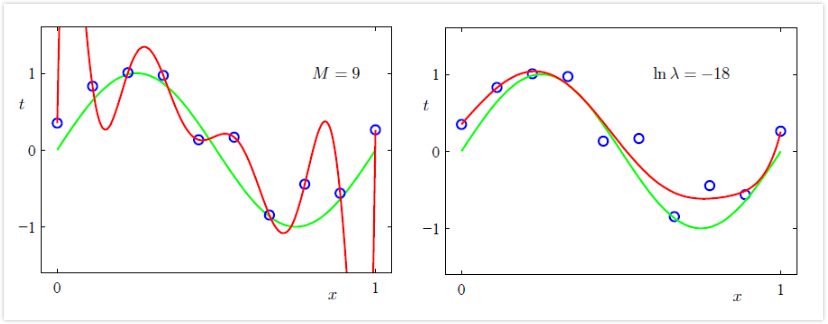
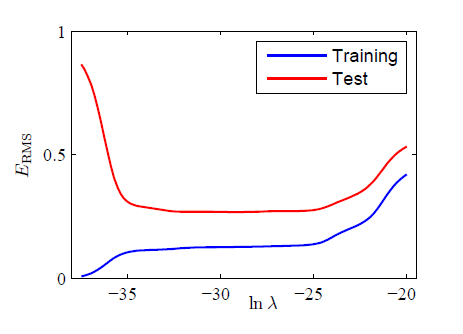
可以看出,同是 M=9 的情况下,加入合适的正则化因子后,模型复杂度得到了很好的控制。类似的,我们可以通过比较模型在训练集和验证集上的表现来选择最优的 λ 值。
小结
上面的讨论简单给出了一种拟合模型:多项式模型,衡量误差的方法,选择最优参数
w∗
和最优模型复杂度
M
,















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









