










有感兴趣量化技术,特别是大数据、人工智能在量化中的应用的童鞋们可以关注我的公众号,脚本代码如果排版不清楚请看公众号:
馨视野(datahomex):

在【第三篇认识backtrader】里,我们提到backtrader是一个量化交易框架,它提供了丰富的接口供开发者使用,支持量化交易的所有环节,包括数据加载、策略开发、策略回溯、实时交易。
数据是机器学习和量化交易的基础或者原料,所以数据处理是最基础也是必不可少的一个组件,今天我们就详细来讲解一下backtrader的datafeeds组件,总共分为4个部分:
-
backtrader 数据格式
-
data feed 生成方式
-
data feed 访问方式
-
lines 访问方式
-
init和next 函数
一、backtrader 数据格式
现在大家都在谈论大数据,因为大家越来越意识到数据的重要性,我们日常生活中无时无刻不在产生数据,如购买记录、和朋友通话、刷个朋友圈、日常驾驶出行等等,程序是对现实世界的抽象,现实产生的数据最终会以特定的形式和结构被存储到计算机世界里。
总之,数据结构是所有程序开发的基础,不同的系统平台对数据格式会有不同的要求,如大家常用的excel二维表的形式,pandas有dataframe、series,java有arraylist、hashmap,spark有rdd、dataset等等。
backtrader作为量化交易框架也有特定的数据格式,就是“data feed” 或 “data feeds",每一个"data feed"大家可以想象成一张二维表格,类似excel表或dataframe。
backtrader通过datafeeds组件将外部数据加载到cerebro,并以data feed格式输送给我们开发的策略。
datafeeds支持的外部数据源很多,包括第三方api(yahoo、Quandl等),csv文件,pandas的dataframe等,用的最多的就是csv和dataframe
二、data feed 生成方式
在【第三篇认识backtrader】,我们基于pandas dataframe的数据生成data feeds,代码如下:
cerebro = bt.Cerebro() //创建Cerebro实例
# 从本地数据库获取数据,生成pandas dataframe
from sqlalchemy import create_engine
import pandas as pd
import time
engine = create_engine('mysql://root:123456@127.0.0.1/stock?charset=utf8mb4')
conn = engine.connect()
sql=("select * from huobi_daily")
df = pd.read_sql(sql,engine)
df['date'] = df['id'].apply(lambda x:time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(x)))
df['date'] = pd.to_datetime(df['date'])
df.index = df.date
# datafeeds模块加载dataframe,并注入到cerebro
data = bt.feeds.PandasData(dataname=df)
cerebro.adddata(data)
当然针对上面提到的其他外部数据源backtrader也提供了专门的加载方式,详细可以参考官网,因为过程都差不多,这里不做介绍了。
三、data feed 访问方式
cerebro加载到data feed后,我们自定义策略类是如何访问data feed的或者说data feed是如何传输给我们自定义策略类的,我们先看一下在【第三篇认识backtrader】中开发的策略是如何访问的
class SmaCross(bt.Strategy): def __init__(self): self.dataclose = self.datas[0].close self.sma1 = bt.ind.SMA(period=self.p.pfast) # fast moving average self.sma2 = bt.ind.SMA(period=self.p.pslow) # slow moving average self.dif = self.sma1 - self.sma2 self.crossover = bt.ind.CrossOver(self.sma1, self.sma2) # crossover signal self.buyprice = None # 买入价格 ''' 省略其他函数 '''
上面初始化函数中获取收盘价格的方式是:self.datas[0].close,这里self.datas就是我们前面生成的data feeds,都是一张一张二维的数据表格,每一个表格可以理解成一个excel的sheet,按照导入顺序,sheet0表示第一张,sheet1表示第二张……,依次类推。
self.datas有非常灵活的索引方式:
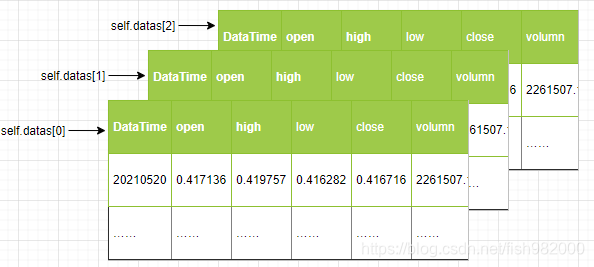
如上图: self.datas[0]:表示导入的第一张data feed self.datas[1]:表示导入的第二张data feed ……
除了self.datas[x]这种访问方式,backtrader提供了多种其他的方式,如:self.datax等同于self.datas[x],所以访问第一张表格也可以表示成self.data0,如果省略数字,self.data就是访问的第一张表格;self.datas 也支持负索引,这个和python保持一致,像self.datas[-1]访问的就是最后一张表格。
另外,如果生成多个data feed时候指定了名称,我们也可以根据数据集的名称获取self.getdatabyname(dataname),下面我们把两只股票的1个月数据加载到backtrader,并在自定义策略中访问这个数据集,详细代码和打印结果如下:
# 加载数据到模型中
from sqlalchemy import create_engine
import pandas as pd
import time
engine = create_engine('mysql://root:123456@127.0.0.1/stock?charset=utf8mb4')
conn = engine.connect()
sql=("select * from stock_daily where ts_code in('000001.SZ','000002.SZ') and trade_date between '20201201' and '20201231'")
df = pd.read_sql(sql,engine)
# df['date'] = df['trade_date'].apply(lambda x:time.strftime('%Y%m%d', time.localtime(x)))
df['date'] = pd.to_datetime(df['trade_date'])
df.index = df.date
#自定义策略
class TestDataFeeds(bt.Strategy):
def __init__(self):
stockList = ['000001.SZ','000002.SZ']
for i in range(len(stockList)):
print("data feeds 清单:")
print("通过下标获取:第%s个数据集(%s,%s)" % (str(i),self.datas[i]._name, self.datas[i]))
print("通过名称获取: 数据集(%s)" % (self.getdatabyname(stockList[i])))
# 创建Cerebro实例,分别注入两只股票数据
cerebro = bt.Cerebro() # create a "Cerebro" engine instance
stockList = ['000001.SZ','000002.SZ']
for stock in stockList:
data = bt.feeds.PandasData(dataname=df[df['ts_code']==stock])
cerebro.adddata(data,name=stock) # Add the data feed
#注入自定义策略
cerebro.addstrategy(TestDataFeeds)
#运行cerebro
cerebro.run()
#打印结果,通过名称获取和下标获取得到的数据集是一致的:
data feeds 清单:
通过下标获取:第0个数据集(000001.SZ,<backtrader.feeds.pandafeed.PandasData object at 0x000001F1828B5160>)
通过名称获取: 数据集(<backtrader.feeds.pandafeed.PandasData object at 0x000001F1828B5160>)
data feeds 清单:
通过下标获取:第1个数据集(000002.SZ,<backtrader.feeds.pandafeed.PandasData object at 0x000001F1FFE11580>)
通过名称获取: 数据集(<backtrader.feeds.pandafeed.PandasData object at 0x000001F1FFE11580>)
[<__main__.TestDataFeeds object at 0x000001F1828D0820>]
四、lines 访问方式
知道了整张数据集的访问方式,接下来是如何定位到数据集中的某个列,有使用pandas经验的童鞋一看就明白,可以通过self.datas[0].close 方式访问,默认情况下,data feed包含7个列,包括datatime,open,high,low,close,volumn,openinterest,其中datatime表示时间序列。
backtrader中把列抽象成为线line,其实这个也很好理解,data feed中每列都有时间序列,顺着时间变化构成了线,所以默认情况下data feed会有7条线,那我们自定义的指标如何加入到lines中。
比如基于上面数据集,我们手工加一个收盘价的5日均价线,看下直接能不能访问:
# 自定义收盘价格5日均线
df['close_ma5'] = df.groupby('ts_code')['close'].transform(lambda x: x.rolling(5).mean())
class TestDataFeeds(bt.Strategy):
def __init__(self):
stockList = ['000001.SZ','000002.SZ']
for i in range(len(stockList)):
# print("data feeds 清单:")
# print("通过下标获取:第%s个数据集(%s,%s)" % (str(i),self.datas[i]._name, self.datas[i]))
# print("通过名称获取: 数据集(%s)" % (self.getdatabyname(stockList[i])))
print("==================[%s]总共lines"%(self.datas[i]._name))
print(self.datas[i].lines.getlinealiases())
print("=================循环打印每条线")
lines = self.datas[i].lines.getlinealiases()
for j in range(len(lines)):
print(self.datas[i].lines[j])
# 打印结果如下:
==================[000001.SZ]总共lines
('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime')
=================循环打印每条线
<backtrader.linebuffer.LineBuffer object at 0x000001F1842127F0>
<backtrader.linebuffer.LineBuffer object at 0x000001F184219070>
<backtrader.linebuffer.LineBuffer object at 0x000001F1842190D0>
<backtrader.linebuffer.LineBuffer object at 0x000001F184219130>
<backtrader.linebuffer.LineBuffer object at 0x000001F184219190>
<backtrader.linebuffer.LineBuffer object at 0x000001F18422B400>
<backtrader.linebuffer.LineBuffer object at 0x000001F18422B310>
==================[000002.SZ]总共lines
('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime')
=================循环打印每条线
<backtrader.linebuffer.LineBuffer object at 0x000001F1842333A0>
<backtrader.linebuffer.LineBuffer object at 0x000001F184233400>
<backtrader.linebuffer.LineBuffer object at 0x000001F184233490>
<backtrader.linebuffer.LineBuffer object at 0x000001F1842334F0>
<backtrader.linebuffer.LineBuffer object at 0x000001F184233550>
<backtrader.linebuffer.LineBuffer object at 0x000001F1842335B0>
<backtrader.linebuffer.LineBuffer object at 0x000001F1842335E0>
[<__main__.TestDataFeeds object at 0x000001F184237850>]
从打印结果看,数据集的lines里并没有包含我们自定义增加的指标,如果策略中需要用到自定义指标,那我们应该怎么做?
其实backtrader提供了很多接口供开发者自定义,上述例子中我们data feed是通过bt.feeds.PandasData得到的,这里默认只包含7条lines,我们可以通过继承bt.feeds.PandasData类,扩展lines数量,如:
class PandasDataExt(bt.feeds.PandasData):
lines = ('close_ma5' )
params=(
('close_ma5', -1),
)
stockList = ['000001.SZ','000002.SZ']
for stock in stockList:
data = PandasDataExt(dataname=df[df['ts_code']==stock])//利用自定义加载类
cerebro.adddata(data,name=stock) # Add the data feed
# 重新执行,打印结果如下,这回我们可以看到close_ma5:
==================[000001.SZ]总共lines
('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime', 'close_ma5')
=================循环打印每条线
<backtrader.linebuffer.LineBuffer object at 0x000001F18449B100>
<backtrader.linebuffer.LineBuffer object at 0x000001F18449B160>
<backtrader.linebuffer.LineBuffer object at 0x000001F18449B1C0>
<backtrader.linebuffer.LineBuffer object at 0x000001F18449B220>
<backtrader.linebuffer.LineBuffer object at 0x000001F18449B280>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844AB3A0>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844AB2E0>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844AB310>
==================[000002.SZ]总共lines
('close', 'low', 'high', 'open', 'volume', 'openinterest', 'datetime', 'close_ma5')
=================循环打印每条线
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B2460>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B2400>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B24F0>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B2550>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B25B0>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B2610>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B2670>
<backtrader.linebuffer.LineBuffer object at 0x000001F1844B26D0>
[<__main__.TestDataFeeds object at 0x000001F1844BA9A0>]
当然和访问data feed一样,访问lines的方式也很灵活,除了通过索引也可以通过名称,如self.data.lines_close,self.data.close,self.data.lines.close,这些方式其实都是等价的,看大家各自的喜欢了。
五、init和next 函数
学会了访问数据集和lines,那么如何获取某条line上具体的点,前面我们提到每条line其实都是有时间属性的,随着时间有序变化,backtrader中通过索引位置表示时间信息,当前位置就是0,-1指向前一个位置,-2,-3依次向后,1指向下一个位置,2,3,……依次向前。
策略类里init() 函数访问的都是整条line,策略类里还有另外一个非常重要的函数next()函数,next()函数会执行多次,执行的次数和line的长度是一样的,执行的顺序是沿着时间轴顺序执行,所以理解next()函数的运行机制对于我们开发自定义策略是非常关键的,下面我们看下在init和next中都是如何访问line上的数据的。
class TestDataFeeds(bt.Strategy):
def __init__(self):
self.stockList = ['000001.SZ','000002.SZ']
for i in range(len(self.stockList)):
# print("data feeds 清单:")
# print("通过下标获取:第%s个数据集(%s,%s)" % (str(i),self.datas[i]._name, self.datas[i]))
# print("通过名称获取: 数据集(%s)" % (self.getdatabyname(stockList[i])))
# print("==================[%s]总共lines"%(self.datas[i]._name))
# print(self.datas[i].lines.getlinealiases())
# print("=================循环打印每条线")
# lines = self.datas[i].lines.getlinealiases()
# for j in range(len(lines)):
# print(self.datas[i].lines[j])
print("==================[%s]的收盘价格"%(self.datas[i]._name))
print("当前日期:%s,当前收盘价格:%s" %(self.datas[i].datetime.date(0),self.datas[i].close[0]))
print("昨天日期:%s,昨天收盘价格:%s" %(self.datas[i].datetime.date(-1),self.datas[i].close[-1]))
print("明天日期:%s,明天收盘价格:%s" %(self.datas[i].datetime.date(1),self.datas[i].close[1]))
def next(self):
for i in range(len(self.stockList)):
print("当前日期:%s,当前收盘价格:%s"%(self.datas[i].datetime.date(0),self.datas[i].close[0]))
# 打印结果
==================[000001.SZ]的收盘价格
当前日期:2020-12-31,当前收盘价格:19.34
昨天日期:2020-12-30,昨天收盘价格:19.2
明天日期:2020-12-01,明天收盘价格:20.05
==================[000002.SZ]的收盘价格
当前日期:2020-12-31,当前收盘价格:28.7
昨天日期:2020-12-30,昨天收盘价格:28.38
明天日期:2020-12-01,明天收盘价格:30.75
当前日期:2020-12-01,当前收盘价格:20.05
当前日期:2020-12-01,当前收盘价格:30.75
当前日期:2020-12-02,当前收盘价格:19.63
当前日期:2020-12-02,当前收盘价格:31.13
当前日期:2020-12-03,当前收盘价格:19.54
当前日期:2020-12-03,当前收盘价格:30.9
当前日期:2020-12-04,当前收盘价格:19.3
从打印结果可以看出,next函数按照日期 从小到大依次循环读取,当前的日期再不断的向前推进,init函数则读取整条line,在策略执行过程只会运行依次。
总结:
今天,关于data feed组件的全部内容就介绍到这了,相信大家对backtrader这个量化框架的运行机制有了更进一步的了解,更多的细节可以查看官网的文档,上面介绍非常详细。
还是一句话:有什么问题,欢迎加微信公众号,线上交流~

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









