









有感兴趣量化技术,特别是大数据、人工智能在量化中的应用的童鞋们可以关注我的公众号,脚本代码如果排版不清楚请看公众号:
馨视野(datahomex):

今天,我们来学习一下机器学习是如何应用到量化交易的,机器学习相关的理论知识暂时不做介绍,后面单独开篇。
前面系列课程里我们提到,完整的量化交易包括数据加载、策略开发、策略回溯、实时交易等环节,最核心的部分则是量化策略的开发,之前我们利用快慢均线的变化(金叉和死叉)作为买卖信号,策略简单,但貌似在数据君下载的某币测试集上效果不是很差,今天我们构建一个简单的线性模型来预测一下某股票的价格走势。
前言
正式开发模型之前,首先要考虑我们准备解决什么问题,或者我们想预测什么,其次要考虑的是针对预测的问题,我们可以收集或利用的数据有哪些?
第一个问题:预测什么
预测未来一周内某股票的最高价格。
第二个问题:用什么来预测
过去2周内某股票的收盘价格,当然有很多的数据可以利用,特征工程是机器学习里最耗时间的环节,这里数据君只是做个演示。
正文
明确了问题,正式开始进入机器学习的世界吧~
1、数据处理
首先准备数据,选取最近5年(20150101-20201231)平安银行(000001.sz)日K线数据,详细数据处理的代码如下:
## 数据获取
import pandas as pd
import numpy as np
from scipy import stats
from sqlalchemy import create_engine
# 数据获取
engine = create_engine('mysql://root:123456@127.0.0.1/stock?charset=utf8mb4')
conn = engine.connect()
sql=("select trade_date,close from stock_daily"
" where ts_code='000001.SZ'"
" and trade_date between '20150101' and '20201231'"
)
stock = pd.read_sql(sql,engine)
stock.index=stock.trade_date
del stock['trade_date']
## 窗口数据拉平函数
def add_lags(series, times):
cols = []
column_index = []
for time in times:
cols.append(series.shift(-time))
lag_fmt = "{col_name}+{time}" if time > 0 else "{{time}" if time < 0 else "t"
column_index += [(lag_fmt.format(time=time), col_name)
for col_name in series.columns]
df = pd.concat(cols, axis=1)
df.columns = pd.MultiIndex.from_tuples(column_index)
return df
## 数据处理
X = add_lags(stock,times=range(-14,1)).iloc[15:-5]
y = add_lags(stock,times=range(1,6)).iloc[15:-5]
# 取未来5天最大的收盘价
y = y.apply(lambda x:np.max(x),axis = 1)
## 数据分割
train_slice = slice(None, "20191231") # 训练集
valid_slice = slice("20200101", "20200631") #评估集
test_slice = slice("20200701", None) #测试集
X_train, y_train = X.loc[train_slice], y.loc[train_slice]
X_valid, y_valid = X.loc[valid_slice], y.loc[valid_slice]
X_test, y_test = X.loc[test_slice], y.loc[test_slice]
我们看一下最终的数据样子,监督学习中每个样本都包含特征变量和目标变量,学习的过程就是挖掘特征变量和目标变量之间的关系。
特征变量选用过去15天的收盘价格,目标变量即我们关心的问题:未来5天内的最高收盘价格
上图每一行索引为当日日期,列为过去15日收盘价格,如:第一行表示20150126过去15天每天的收盘价格
trade_date
20150126 8.9963
20150127 8.9963上图每一行表示当日日期未来5天内的最高收盘价,即我们需要预测的变量,如:第一行表示20150126未来5天内最高的收盘价格为8.9963
机器学习有个很有意思的说法“数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这里的数据不是指原始数据,而是经过特征工程提炼后的数据,所以在机器学习过程中特征工程是非常重要的一个环节,深度学习的一个优势就是可以自动的帮我们提炼高阶的特征。
2、模型开发
基于上面的数据,我们先用开源的sklearn机器学习框架开发一个简单的线性回归模型,详细代码如下:
# sklearn 线性
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train) #线性函数上面5行代码实现了一个简单的线性回归模型,大家觉得是不是太简单了,其实无论简单的还是复杂的机器学习就三个步骤:
定义model(function set)
定义评估model的function
选择最优的function
1)、这里model就是线性模型,如果是一元一次线性模型,那么我们需要基于样本的数据在二维平面内寻找一条最优的直线,如果是N元一次线性模型,那么我们需要在(N+1)维的空间内寻找最优的N维超平面。
2)、到底怎么样算是最优的直线或超平面,我们已预测值和实际值的差异来恒量,在机器学习里,评估model好坏的函数也叫损失函数,在回归模型里一般用绝对值误差或均方根误差来表示。
3)、找到使损失函数值最小的直线或超平面,也就是求损失函数的最小值,线性函数的损失函数是凸函数所以肯定存在最优解,sklearn开源框架里直接用最小二乘法获取最优模型。一般机器学习里会用梯度下降法去寻找近似的最优解,因为很多机器学习模型的损失函数非常复杂,很多时候没有解析解或精确解,就算有解析解,如果维度很多,损失函数又复杂,机器是不知道解法的或者解也是非常耗性能,所以直接求优是一步到位,梯度下降则是逐步逼近,当然这里也涉及模型泛化能力、计算效率等很多问题,细节的东西后面在机器学习专栏里分享。
3、模型评估
我们用上面训练得到的模型,看看在评估集上的表现,详细代码如下:
#
y_valid_pred = lin_reg.predict(X_valid) #预测
# 回归模型常用的评估指标
from sklearn.linear_model import LinearRegression,mean_squared_error,median_absolute_error,r2_score
print("平均绝对值误差:", mean_absolute_error(y_valid, y_valid_pred))
print("平均平方误差:", mean_squared_error(y_valid, y_valid_pred))
print("中位绝对值误差:", median_absolute_error(y_valid, y_valid_pred))
print("R2得分:", r2_score(y_valid, y_valid_pred))
#差值分布
(y_valid_pred-y_valid).hist()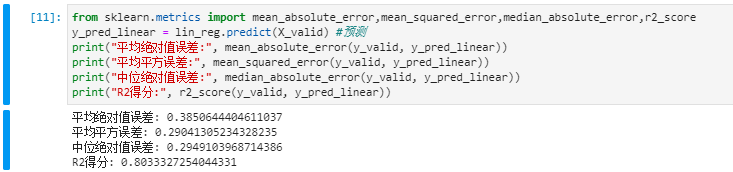

预测值和真实值比对图:
import matplotlib as mpl
import matplotlib.pyplot as plt
def plot_predictions(*named_predictions, start=None, end=None, **kwargs):
day_range = slice(start, end)
plt.figure(figsize=(10,5))
for name, y_pred in named_predictions:
if hasattr(y_pred, "values"):
y_pred = y_pred.values
plt.plot(y_pred[day_range], label=name, **kwargs)
plt.legend()
plt.show()
plot_predictions(("Target", y_valid),
("Linear", y_valid_pred),
end=365)
从验证集的表现看,模型效果一般,毕竟我们只使用了历史收盘价格这一因素,还有很多特征可以提取加工,如成交量、开盘价、各类统计型指标包括macd、boll、kdj等等。
4、模型应用
【模型怎么应用到业务系统?】
如果业务系统运行环境和模型运行环境是一套的,那么直接将模型导出成模型文件,后续业务系统需要用到的时候直接加载就行
#模型保存 import joblib joblib.dump(lr, "sklearn-lr.pkl") #模型加载 lr = joblib.load("sklearn-lr.pkl")
业务系统一般都是java环境,机器学习(包括深度学习)很多都是用python开发的,那如何实现模型可以跨平台应用,有几种解决方式:
1、最直接用java翻译一遍,或者直接用java开发模型,不过这个效率太低
2、搭建机器学习或深度学习平台,将开发完成的模型封装成对外服务的接口
3、python开发的模型导出成pmml文件,pmml文件可以跨平台被调用,java可以用开源的jpmml库调用
# sklearn 模型导出pmml文件 需要安装pip install sklearn2pmml from sklearn2pmml import PMMLPipeline pipeline = PMMLPipeline([("regression", lin_reg)]) pipeline.fit(X_train,y_train) from sklearn2pmml import sklearn2pmml sklearn2pmml(pipeline, "sklearn-lr.pmml", with_repr = True)pmml文件就似乎xml文件,里面定义了模型的详细信息,包括模型类型、输入输出特征、具体参数值,详细如下:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <PMML xmlns="http://www.dmg.org/PMML-4_4" xmlns:data="http://jpmml.org/jpmml-model/InlineTable" version="4.4"> <Header> <Application name="JPMML-SkLearn" version="1.6.18"/> <Timestamp>2021-06-03T08:59:40Z</Timestamp> </Header> <MiningBuildTask> <Extension>PMMLPipeline(steps=[('regression', LinearRegression())])</Extension> </MiningBuildTask> <DataDictionary> <DataField name="None" optype="continuous" dataType="double"/> <DataField name="close-t-14" optype="continuous" dataType="double"/> <DataField name="close-t-13" optype="continuous" dataType="double"/> <DataField name="close-t-12" optype="continuous" dataType="double"/> <DataField name="close-t-11" optype="continuous" dataType="double"/> <DataField name="close-t-10" optype="continuous" dataType="double"/> <DataField name="close-t-9" optype="continuous" dataType="double"/> <DataField name="close-t-8" optype="continuous" dataType="double"/> <DataField name="close-t-7" optype="continuous" dataType="double"/> <DataField name="close-t-6" optype="continuous" dataType="double"/> <DataField name="close-t-5" optype="continuous" dataType="double"/> <DataField name="close-t-4" optype="continuous" dataType="double"/> <DataField name="close-t-3" optype="continuous" dataType="double"/> <DataField name="close-t-2" optype="continuous" dataType="double"/> <DataField name="close-t-1" optype="continuous" dataType="double"/> <DataField name="close-t" optype="continuous" dataType="double"/> </DataDictionary> <RegressionModel functionName="regression" algorithmName="sklearn.linear_model._base.LinearRegression"> <MiningSchema> <MiningField name="None" usageType="target"/> <MiningField name="close-t-14"/> <MiningField name="close-t-13"/> <MiningField name="close-t-12"/> <MiningField name="close-t-11"/> <MiningField name="close-t-10"/> <MiningField name="close-t-9"/> <MiningField name="close-t-8"/> <MiningField name="close-t-7"/> <MiningField name="close-t-6"/> <MiningField name="close-t-5"/> <MiningField name="close-t-4"/> <MiningField name="close-t-3"/> <MiningField name="close-t-2"/> <MiningField name="close-t-1"/> <MiningField name="close-t"/> </MiningSchema> <RegressionTable intercept="-0.059849123733643594"> <NumericPredictor name="close-t-14" coefficient="0.06298077755963864"/> <NumericPredictor name="close-t-13" coefficient="-0.05408509717651838"/> <NumericPredictor name="close-t-12" coefficient="-0.004723572368985171"/> <NumericPredictor name="close-t-11" coefficient="0.041517165056502846"/> <NumericPredictor name="close-t-10" coefficient="0.013550446773910665"/> <NumericPredictor name="close-t-9" coefficient="-0.14018454038086842"/> <NumericPredictor name="close-t-8" coefficient="0.01048025542919341"/> <NumericPredictor name="close-t-7" coefficient="-0.025916098005424673"/> <NumericPredictor name="close-t-6" coefficient="0.15451442848375044"/> <NumericPredictor name="close-t-5" coefficient="0.07171869335982237"/> <NumericPredictor name="close-t-4" coefficient="0.0023058435492882"/> <NumericPredictor name="close-t-3" coefficient="-0.11646536416581277"/> <NumericPredictor name="close-t-2" coefficient="0.005734456338611582"/> <NumericPredictor name="close-t-1" coefficient="-0.047005564169814426"/> <NumericPredictor name="close-t" coefficient="1.053588857926864"/> </RegressionTable> </RegressionModel> </PMML>
【模型又怎么融入到量化交易框架中去?】
应用到量化框架中其实比较简单,上篇【第三篇认识backtrade】中我们在开发自定义交易策略中用快速均线上穿慢速均线作为买入信号,这里我们再结合模型预测的值,比如未来5天预测最高收盘价会超过当前价格的10%则买入。
总结
今天我们开发了一个简单的线性回归模型来预测某股票未来几天内的最高收盘价,并介绍了如何将开发完成的模型应用到线上业务系统和融入到量化框架里。
模型虽然简单,但覆盖了机器学习的主要流程,这里没讲很多细节和原理的东西,后面会单独开个机器学习相关的系列。
下篇我们会手写个线性回归的模型,并将模型应用到量化交易框架,当然这只是个基础模型,后面还会继续改进这个模型,比如应用深度学习中的序列模型,和这个基础模型做比较。
有什么问题,欢迎加微信公众号,线上交流















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









