







论文阅读:Segment Anything
2. Segment Anything Task
灵感来源于NLP
Task
我们首先将prompt的概念从NLP转到segmentation,提示可以是一对前景/背景点、rough box or mask、free-form的文本、或者,更通常的情况,any information 可以提示如何分割图片。于是,我们的可提示的分割任务(promptable segmentation),就是在任意提示下返回有效的(valid)分割。对“有效”掩码的要求仅仅意味着,即使当提示不明确并且可能涉及多个对象时,输出应该是这些对象中至少一个的合理掩码。这一要求类似于期望语言模型对模棱两可的提示输出连贯的响应。我们之所以选择这个任务,是因为它导致了一种自然的预训练算法和一种通过提示将零镜头(zero-shot transfer)转移到下游分割任务的通用方法。

Pre-training
可提示分割任务建议自然(naturel)的预训练算法,该算法模拟每个训练样本的提示序列(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。我们从交互式分割(interactive segmentation)中改写这种方法,尽管不同于交互式分割的目的是在足够的用户输入后最终预测有效掩码,我们的目标是始终预测任何提示的有效掩码(即使提示是模糊的)。这确保了预先训练的模型在涉及歧义的用例中是有效的,包括我们的数据引擎§4所要求的自动注释。我们注意到,在这项任务中获得很好的表现是具有挑战性的,并且需要专门的建模和训练损失选择,我们在§3中讨论了这一点。
Zero-shot transfer
直观地说,我们的预训练任务使模型能够在推理时对任何提示做出适当的反应,因此,下游任务可以通过设计适当的提示来解决。例如,如果有一个猫的bounding box detector,则可以通过将检测器的bounding box输出作为提示提供给我们的模型来解决猫实例分割问题。一般而言,一系列实际的细分任务可以看作是提示性的。除了自动数据集标记外,我们还在§7的实验中探索了五个不同的示例任务。
Related tasks
请注意,这与以前关于多任务分割系统的工作不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义、实例和全景分割,但是训练和测试任务是相同的。我们工作中的一个重要区别是,为可提示分割训练的模型可以在推理时通过充当更大系统中的组件来执行新的不同任务,例如,为了执行实例分割,可提示分割模型与现有的对象检测器相结合。
Discussion
提示和组合是强大的工具,使单个模型能够以可扩展的方式使用,潜在地完成模型设计时未知的任务。该方法类似于如何使用其他基础模型。我们预计,在即时工程等技术的支持下,可组合的系统设计将支持比专门为固定任务集培训的系统更广泛的应用程序。从合成的角度比较提示分割和交互分割也很有趣:虽然交互分割模型的设计考虑到了人类用户,但为提示分割而训练的模型也可以被组合成一个更大的算法系统,正如我们将演示的那样。
3. Segment Anything Model
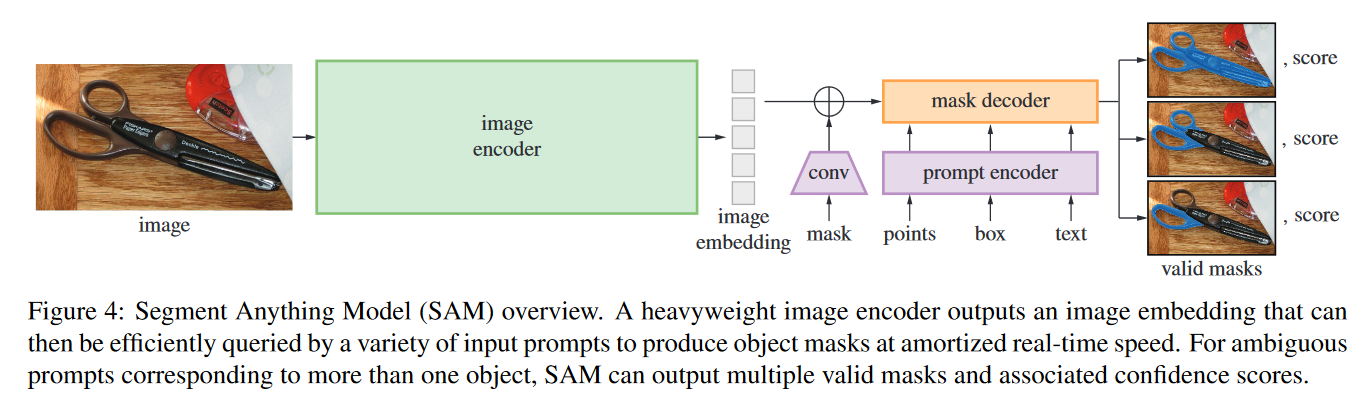
Image ecoder 出于可扩展性和强大的预训练方法的考虑,我们使用MAE预训练的视觉转换器(VIT),最小限度地适应处理高分辨率输入。图像编码器每幅图像运行一次,可以在提示模型之前应用。
Prompt encoder 我们考虑两组提示:稀疏提示(点、框、文本)和密集提示(mask)。我们通过位置编码来表示点和框,位置编码与用于每种提示类型和自由格式文本的学习嵌入相加,并使用来自CLIP的现成文本编码器。密集提示(即,掩码)使用卷积嵌入,并与图像嵌入一起按元素求和。
Mask decoder 掩码解码器有效地将图像嵌入、提示嵌入和输出token映射到mask。该设计受[14,20]的启发,采用了对transformer解码器块[103]的修改,和动态掩码预测磁头。改进后的解码块使用两个方向的提示自我注意和交叉注意(图像提示嵌入和图像提示嵌入)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,然后该分类器计算每个图像位置的掩码前景概率。
Resolving ambiguity 对于一个输出,如果给出一个模棱两可的提示,该模型将平均多个有效掩码。为了解决这个问题,我们修改了模型,以预测单个提示的多个输出掩码(参见图3)。我们发现,3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多有三个深度:整体、部分和子部分)。在训练中,我们只支持mask上最小的损失]。为了对掩码进行排序,该模型预测每个掩码的置信度分数(即,估计IOU)。
Efficiency 整个模型的设计在很大程度上是由效率驱动的。在给定预先计算的图像嵌入的情况下,提示编码器和掩码解码器在∼50ms的中央处理器上的网络浏览器中运行。这种运行时性能使我们的模型能够无缝、实时地交互提示。
Losses and training 我们用中使用的focal loss 和 dice loss的线性组合来监督掩模预测。我们使用几何提示的混合来训练可识别的分割任务(文本提示见§7.5)。在之后,我们通过每个掩码随机抽取11轮提示来模拟交互式设置,从而使SAM无缝集成到我们的数据引擎中。
Appendix A: Segment Anything Model and Task Details
Image encoder
通常,图像编码器可以是输出 C × H × W C×H×W C×H×W图像嵌入的任何网络。出于可伸缩性和获得强大的预训练的动机,我们使用MAE预训练的视觉转换器(VIT)来处理高分辨率输入,特别是具有14×14窗口注意力和四个等间距全局注意力块的VIT-H/16。图像编码器的输出是输入图像的16倍缩小嵌入。因为我们的运行时目标是实时处理每个提示,所以我们可以承受大量的图像编码器FLOPs,因为它们只在每个图像上计算一次,而不是每个提示。
遵循标准做法,我们使用通过重新缩放图像并填充短边获得的1024×1024的输入分辨率。因此,图像嵌入为64×64。为了减少通道维数,我们使用1×1卷积来获得256个通道,然后使用3×3卷积输出256个通道。每次卷积之后都进行层归一化
Prompt encoder
稀疏提示被映射到256维矢量嵌入,如下所示。
一个点被表示为该点的位置的位置编码和指示该点是在前景中还是在背景中的两个学习嵌入之一的和。
框由嵌入对来表示:(1)其左上角的位置编码与表示“左上角”的学习嵌入相加;以及(2)相同的结构,但使用表示“右下角”的学习嵌入。
最后,为了表示自由格式的文本,我们使用CLIP中的文本编码器(任何文本编码器通常都是可能的)。在本节的其余部分,我们将重点介绍几何提示,并在§D.5中深入讨论文本提示。
密集提示(即,mask)具有与图像的空间对应性。我们以比输入图像低4倍的分辨率输入掩码,然后分别使用输出通道4和16使用两个2×2,步幅-2卷积来缩小额外的4倍。最后一个1×1卷积将通道维度映射为256。每一层都由GELU激活和层归一化分开。然后按元素添加掩码和图像嵌入。如果没有掩码提示,则表示“no mask”的学习嵌入被添加到每个图像嵌入位置。
Lightweight mask decoder
该模块有效地将图像嵌入和一组提示嵌入映射到输出mask。为了组合这些输入,我们从transformer分段模型中获得灵感,并修改标准的transformer解码器。在应用我们的解码器之前,我们首先在提示嵌入集合中插入一个可学习的输出token嵌入,它将在解码器的输出中使用,类似于[33]中的[CLASS]令牌。为简单起见,我们将这些嵌入(不包括图像嵌入)统称为“tokens”。
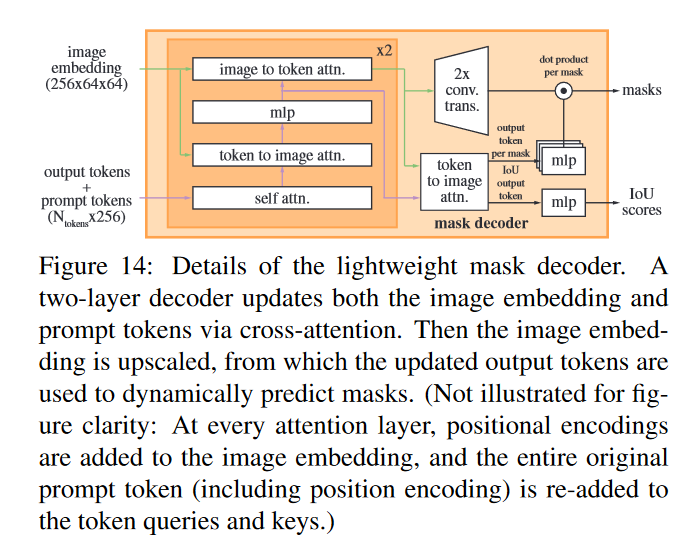
我们的解码器设计如图14所示。每个解码层执行4个步骤:
(1)对令牌的自我注意,
(2)从令牌(作为查询)到图像嵌入的交叉注意,
(3)逐点MLP更新每个令牌,
(4)从图像嵌入(作为查询)到令牌的交叉注意。
最后一步是使用提示信息更新嵌入的图像。在交叉注意过程中,图像嵌入被看作是一组 6 4 2 64^2 642个256维的矢量。每个自我/交叉注意和MLP都有残差连接、层归一化和训练时0.1的dropout。下一解码器层从上一层获取更新的令牌和更新的图像嵌入。我们使用两层解码器。
为了确保解码器可以访问关键的几何信息,每当位置编码参与注意层时,它们都会被添加到图像嵌入中。此外,整个原始提示标记(包括它们的位置编码)在它们参与注意层时被重新添加到更新的标记中。这允许对提示标记的几何位置和类型的强烈依赖。
在运行解码器后,我们将更新后的图像嵌入上采样4倍,并使用两个转置的卷积层(现在相对于输入图像缩小了4倍)。然后,token再次参与图像嵌入,我们将更新后的输出令牌嵌入传递给一个小的3层MLP,该MLP输出与放大的图像嵌入的通道维度相匹配的矢量。最后,我们预测了在放大图像嵌入和MLP的输出之间具有空间点方向乘积的mask。















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









