






许多RAG方法侧重于将文档分割成块,并在LLM检索时返回相关的一部分块。然而,块大小和块数量是很难设置好的参数;如果返回的块不包含回答问题的所有上下文,则两者都会显著地影响结果。

解决思路:针对检索优化,使用LLM生成文档摘要。在此基础上,我们创建了两种检索器:(1)multi-vector retriever将摘要向量化,但将完整文档返给LLM。(2) parent-doc retriever将块向量化,但将完整文档返给LLM。核心思想是使用较小/简洁的表示(摘要或块)进行检索,但将它们链接到完整的文档/上下文中进行生成。
Multi-representation Indexing
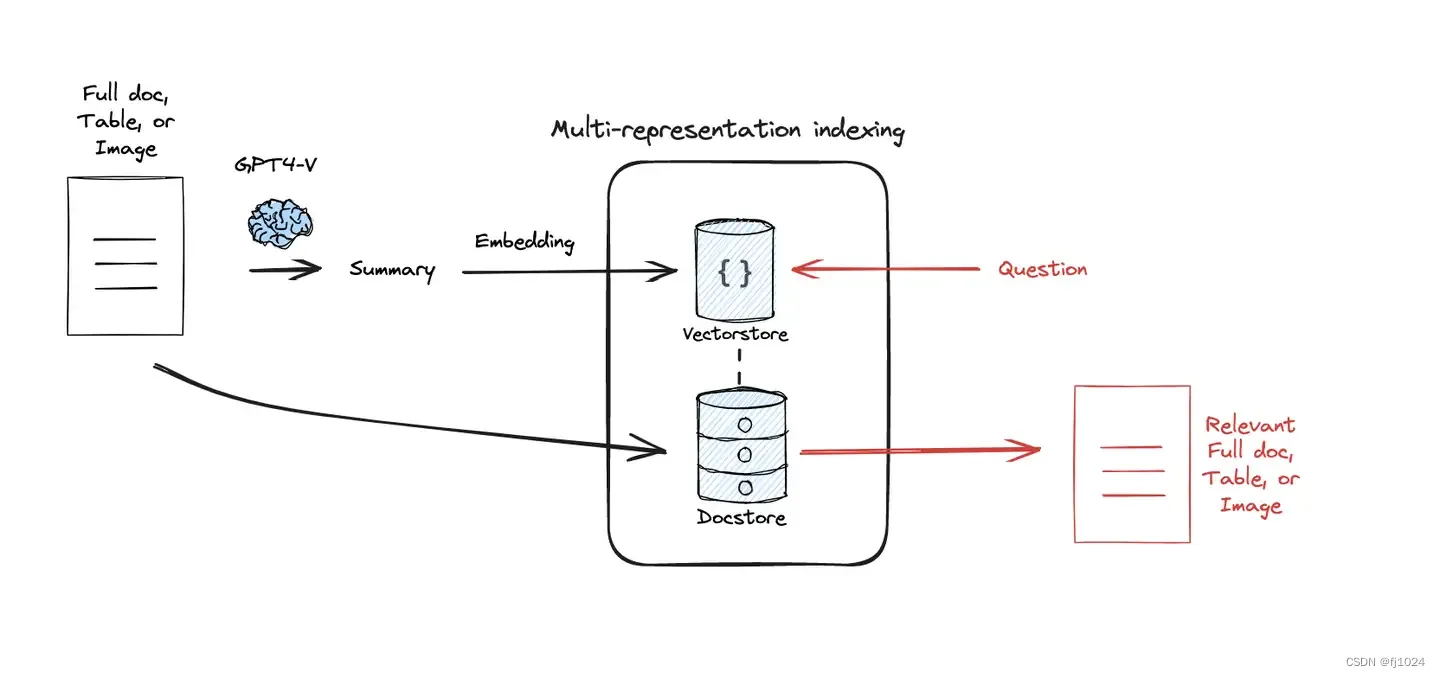
对每个文档进行摘要生成,使用较小/简洁的表示(摘要或块)进行检索,但将它们链接到完整的文档/上下文中进行生成。检索到的文本更多地浓缩了与问题相关的信息,因此减少了冗长token的输入,最大限度地减少了无关信息,增强了下游QA任务的表现。
RAPTOR
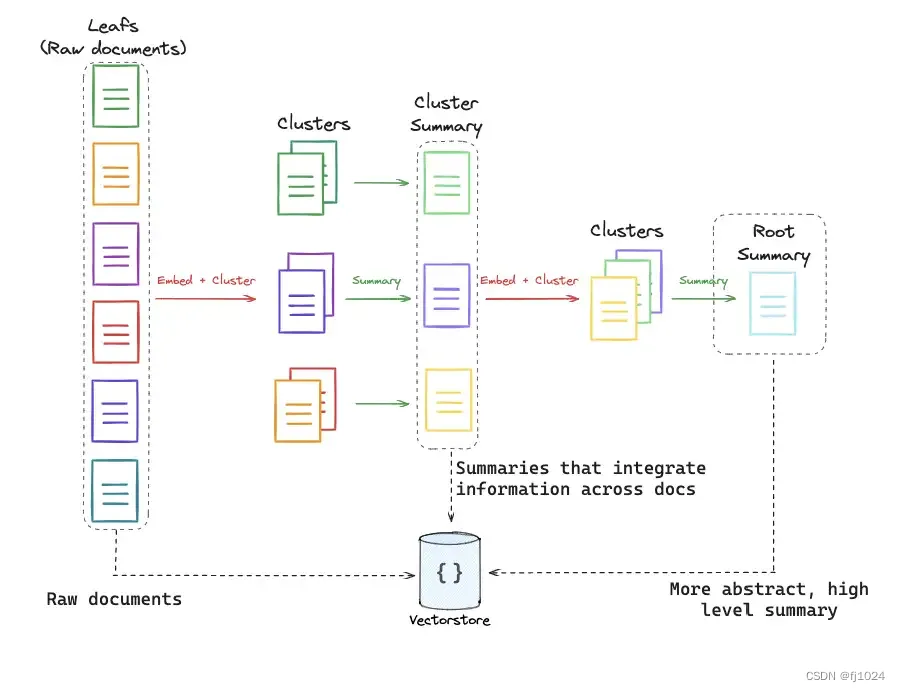
随着LLM的上下文窗口越来越大,RAG管道的设计也面临着改变。作为拆分文档和索引文档块的替代方案,索引整篇文档将变得可行。RAG方法需要灵活回答单篇文档的lower-level问题,或者需要跨多个文档提供信息的higher-level问题。
RAPTOR方法通过构建文档摘要树来解决这个问题:对文档进行聚类,并对类簇进行总结以获取相似文档中higher-level的信息。递归重复这个过程直到生成一颗摘要树,从单篇文档作为树的叶子到相关文档的中间摘要,再到整个文档集合的high-level摘要。摘要和起始文档一起被索引,覆盖query的范围。
ColBERT
ColBERT是一种快速精准的检索模型,能够在数十毫秒内对海量文本集合进行可扩展的基于BERT的搜索。
常规的embedding模型为每个文档存储一个向量,并返回一个分数显示该文档与query的匹配程度。ColBERT的原理略有不同:它为段落中的每个token生成一个受上下文影响的向量,同样地也对query中的每个token生成向量,每个文档的得分是每个query嵌入与任意文档嵌入的最大相似度的总和。















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









