







On policy: 采样数据所用的policy和参数更新的policy是同一个。
Off policy:采样数据所用的policy和参数更新的policy不是同一个。
重要性采样:从p(x)中采样(对应on policy);
从与p(x)近似的分布q(x)中采样

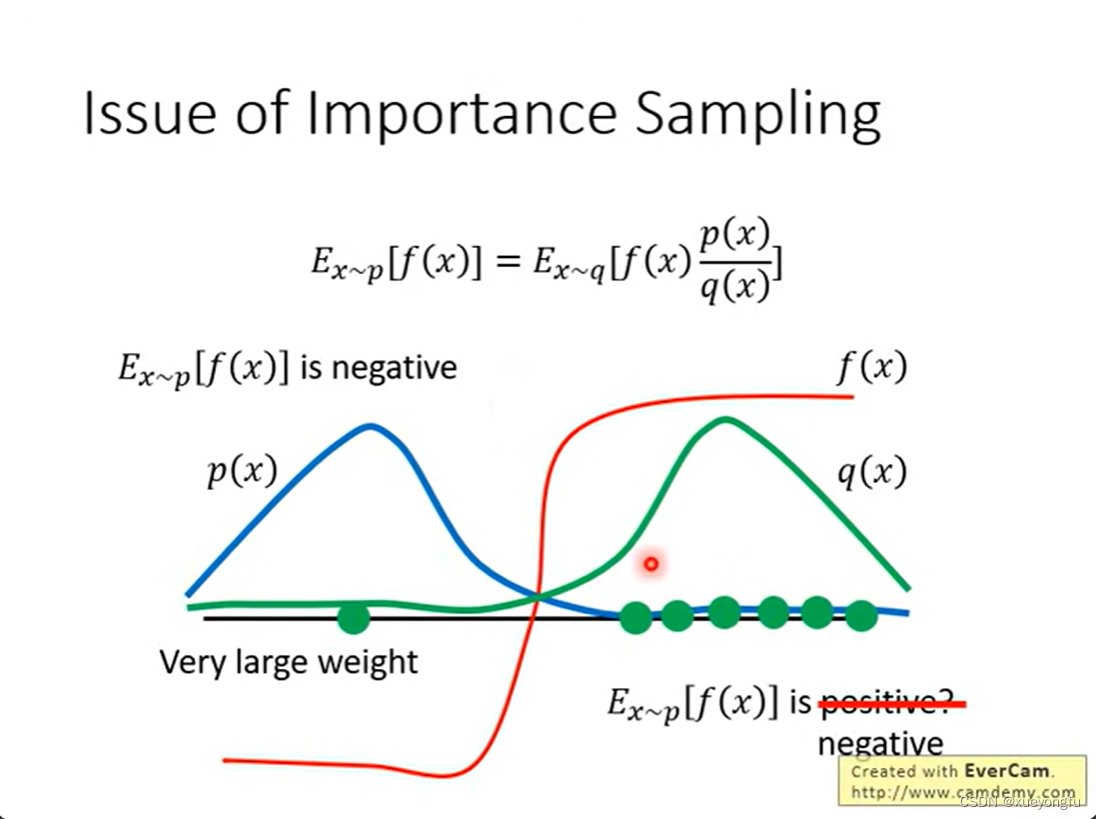
使用重要性采样,期望值相等,当p(x)与q(x)的分布接近时,二者方差的差异较小,因此在使用重要性采样时,两个分布的差异应当比较小。

如下图所示,q(x)分布的采样值更多的落在右半边区域,在采样次数较少的情况下,期望是正值,与p(x)采样得到的期望值是负值的结果不符,但是,当采样次数较多时,q(x)也会采样到左半边区域的值,此时p(x)/q(x)值比较大,使得计算的期望是负值,与p(x)采样得到的期望值是负值的结果相符。
因此可以得出:当p(x)和q(x)分布差异较大时,需要更多的采样才能逼近正确的结果。如果分布差异较小,则需要的采样次数也就相对较少。
使用重要性采样,可以将on-policy模型转化为off policy模型,使用模型采样数据,然后使用采样到的数据训练
模型多次。

使用重要性采样方法更新policy gradient算法, 是基于当前state和action计算的accumulative reward(折现reward减去一个baseline),是与
模型相关的。在这里省略了
,是因为二者的概率很可能是相等的。
最后得到新的目标函数:

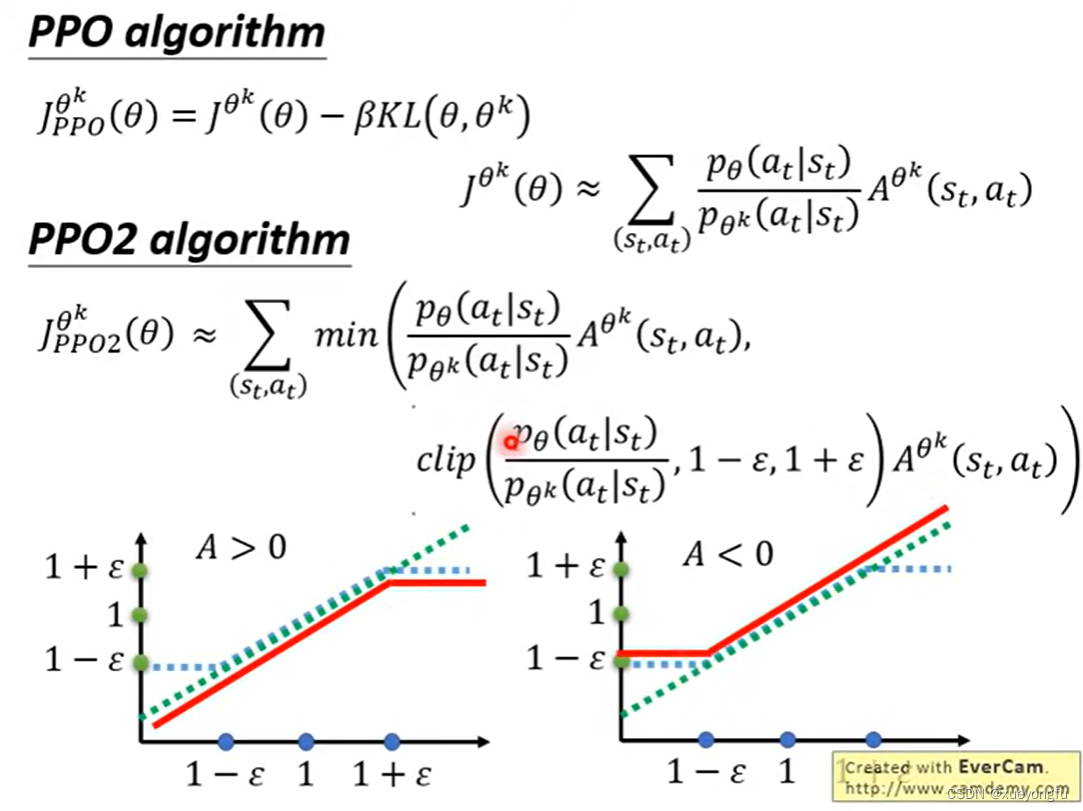
PPO算法在新目标函数的基础上添加了一个KL divergence项,目的是限制两个policy模型分布的差异。TRPO与PPO的区别是,TRPO未把KL divergence加到目标函数。

PPO算法的流程是,使用与环境进行交互来收集数据,并计算优势函数
,然后收集好的数据优化
多次。

PPO2对PPO做了进一步简化,从函数图像中不难得出,当优势函数值大于0时,越大越好,但是不能超过1+
,因为超过1+
,
和
模型分布差异较大,优势函数值小于0时同理。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









