







AC
先说下Policy gradient存在的问题,期望累计收益是非常不稳定的,只有当采样丰富的样本时,才可以获得接近真实的G值,但是现实情况往往不能采样足够丰富的样本。
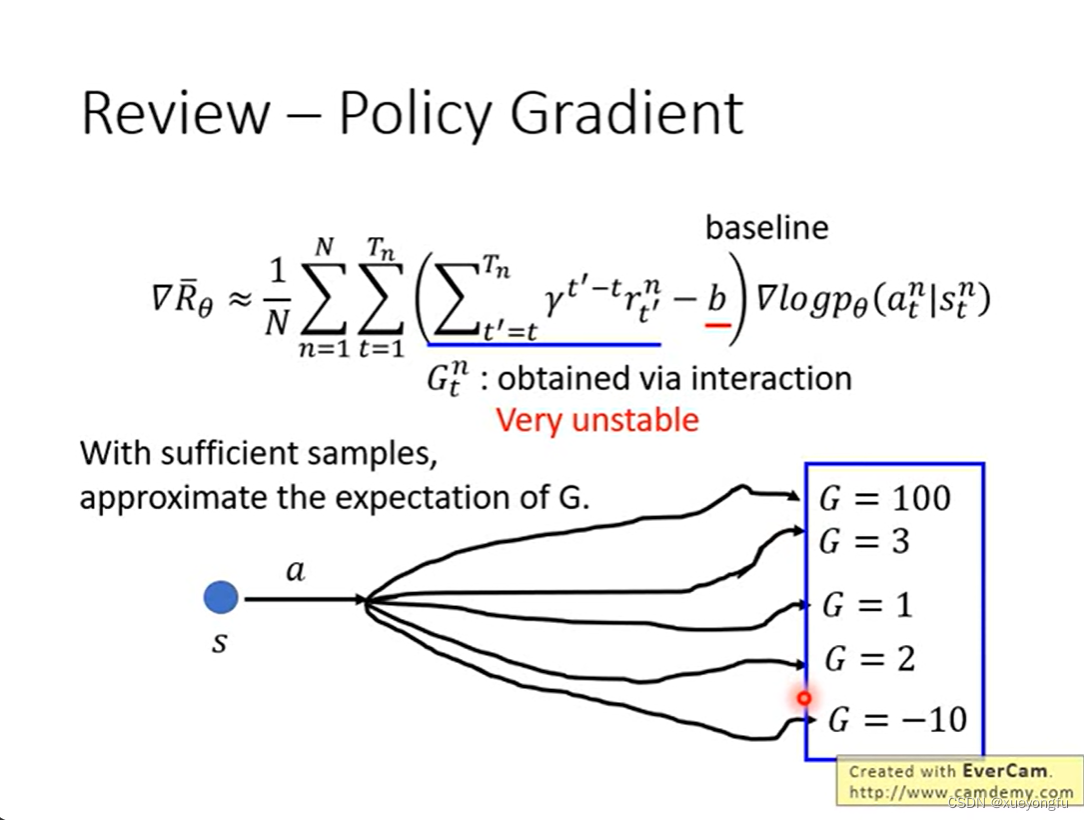
如果我们将policy gradient中的用Q函数替代,相当于我们创建一个Critic网络来计算Q函数值,那么我们就得到了Actor-Critic方法。
回顾policy gradient的讲解中,baseline b是状态s的期望收益,其实就是。

A2C
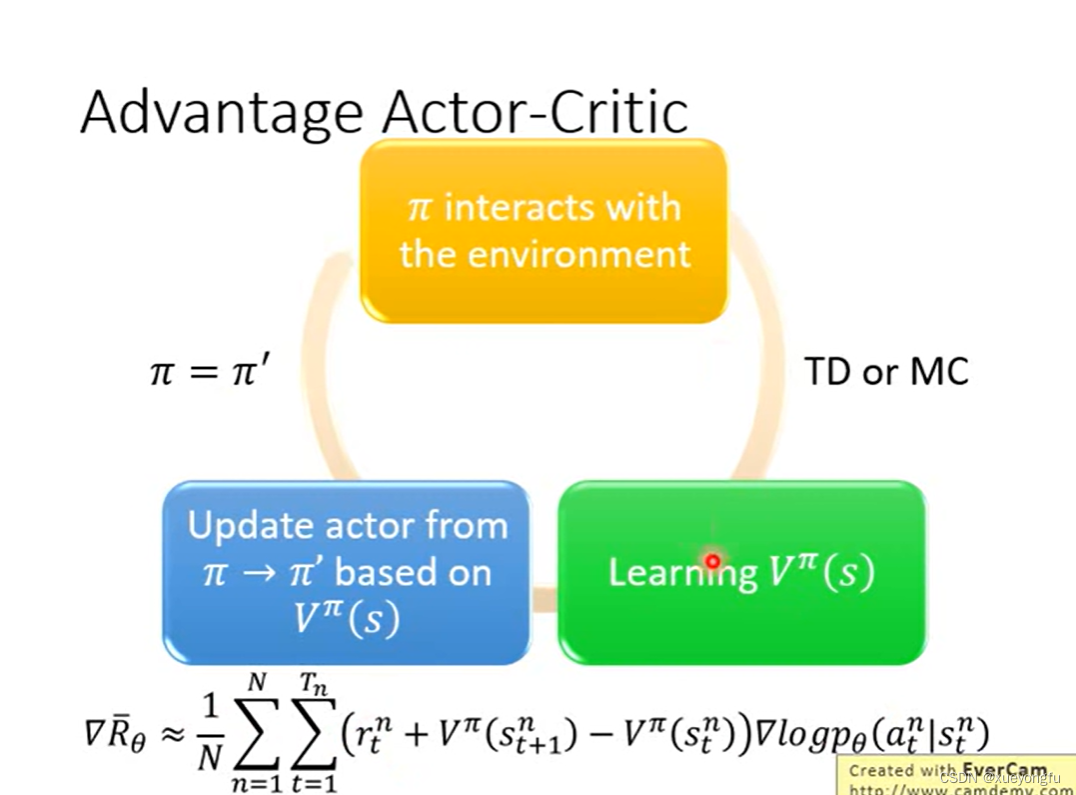
我们得到的等式中出现了Q函数和V函数,那么就需要学习这两个网络,那么如何转化为只估计其中一个网络呢?
思考Q值和V值之间的关系:
V值:就是从状态S出发,到最终获取的所获得的奖励总和的期望值。
Q值:S状态下有若干个动作,每个动作的Q值,就是从这个动作之后所获得的奖励总和的期望值。
1. 基于Q值计算V值:
2. 基于V值计算Q值(注意采取action之后会获得一定的奖励):
actor在状态
采取a行为获取一定的奖励R,状态转移到
因此,我们可以将Q函数转化为V函数,这样我们就可以只估计V函数即可。

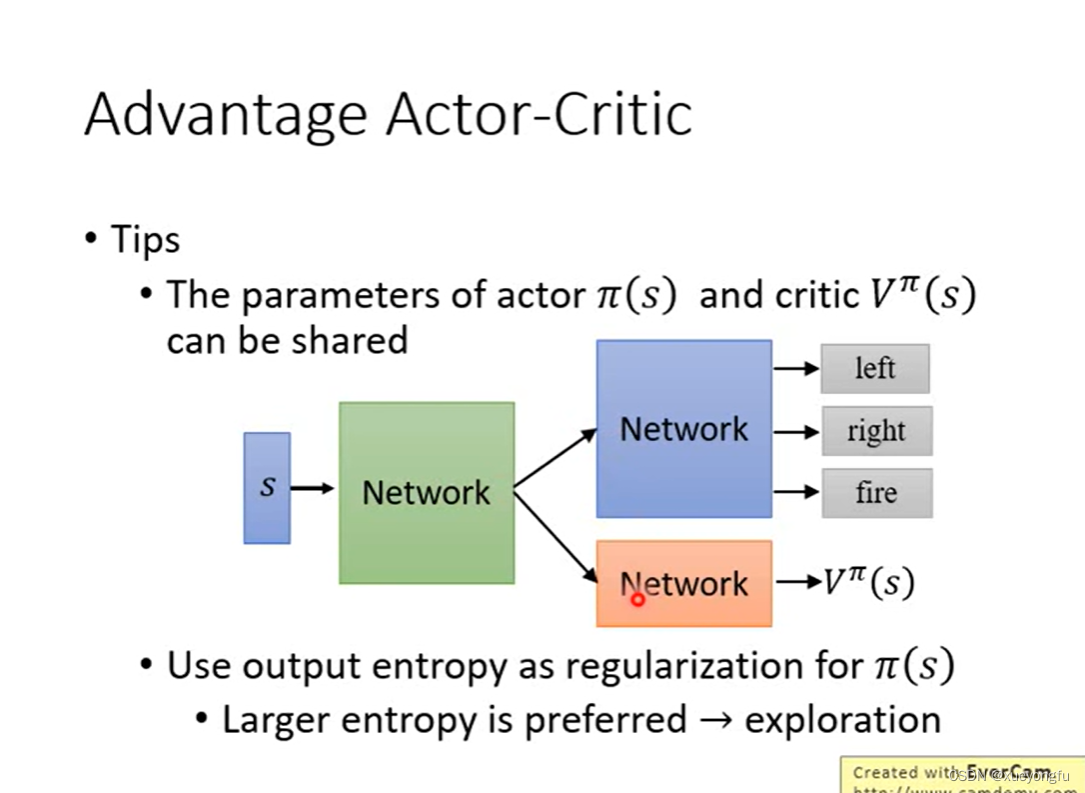
我们将AC需要学习三个网络(Q函数,V函数,策略网络)优化成了只需要学习V函数和策略网络。可以进一步优化,将策略网络和V函数进行网络参数共享。
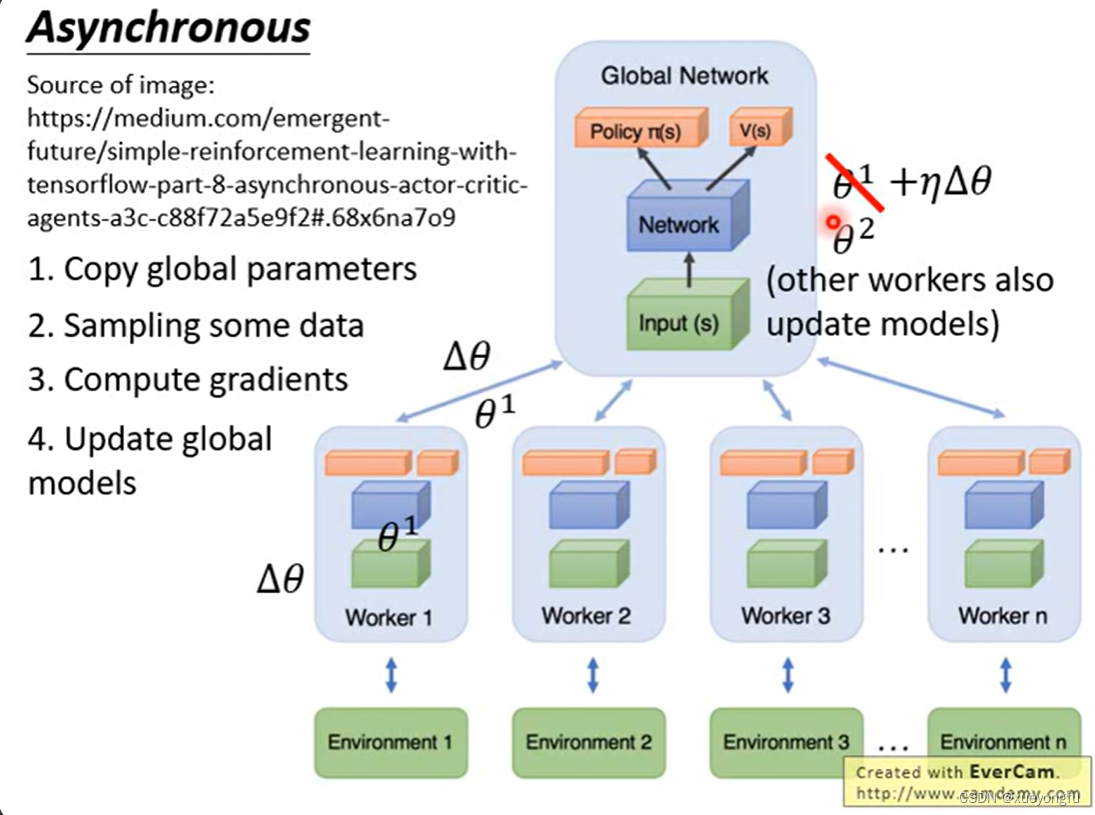
A3C
A3C将actor与环境的交互变成了异步的,每个worker可以分别与环境进行交互,并进行参数更新,更新完之后需要梯度更新到global network,并拉取最新的global network的参数替换掉worker的参数。















 1858
1858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









