







强化学习分类
model-based OR model-free
1. model-based RL
建模的是环境,即学习环境状态转移概率和奖励函数的估计值,学得的模型可以提供智能体在未来状态和奖励的预测,从而帮助代理进行策略规划和决策制定。
基于动态规划的强化学习是model-based RL中的重要一类模型,有明确的环境(即环境状态转移概率和奖励函数),它的学习方法只有有两种,分别是值迭代、策略迭代。常见的迷宫游戏是基于动态规划的强化学习的一种。
2. model-free RL
不建模环境,如Atari游戏等,学习
value-based:Sarsa、Q-learning、DQN
policy-based:policy gradient、PPO、TRPO
mixed-based:actor-critic、A2C、A3C
on line OR off line
1. on line RL
on line RL,在线强化学习,学习的过程需要与环境进行交互。分为on-policy RL和off-policy RL,on-policy采用的是当前策略搜集的数据训练模型,每条数据仅使用一次。off-policy训练采用的数据不需要是当前策略搜集的。
2. off line RL
off line RL,离线强化学习,学习的过程不需要与环境进行交互,从已经收集的数据中进行学习。
| algorithm | ||
| on line RL | on policy | SARSA、A3C等 |
| off policy | Q-learning、DQN等 | |
| off line RL | CQL、AWAC等 |
探索与利用
贪心策略:每次选择使得激励最高的action
策略:每次以
的概率随机选择action
衰减贪心策略:策略的变种,
随着时间变化衰减
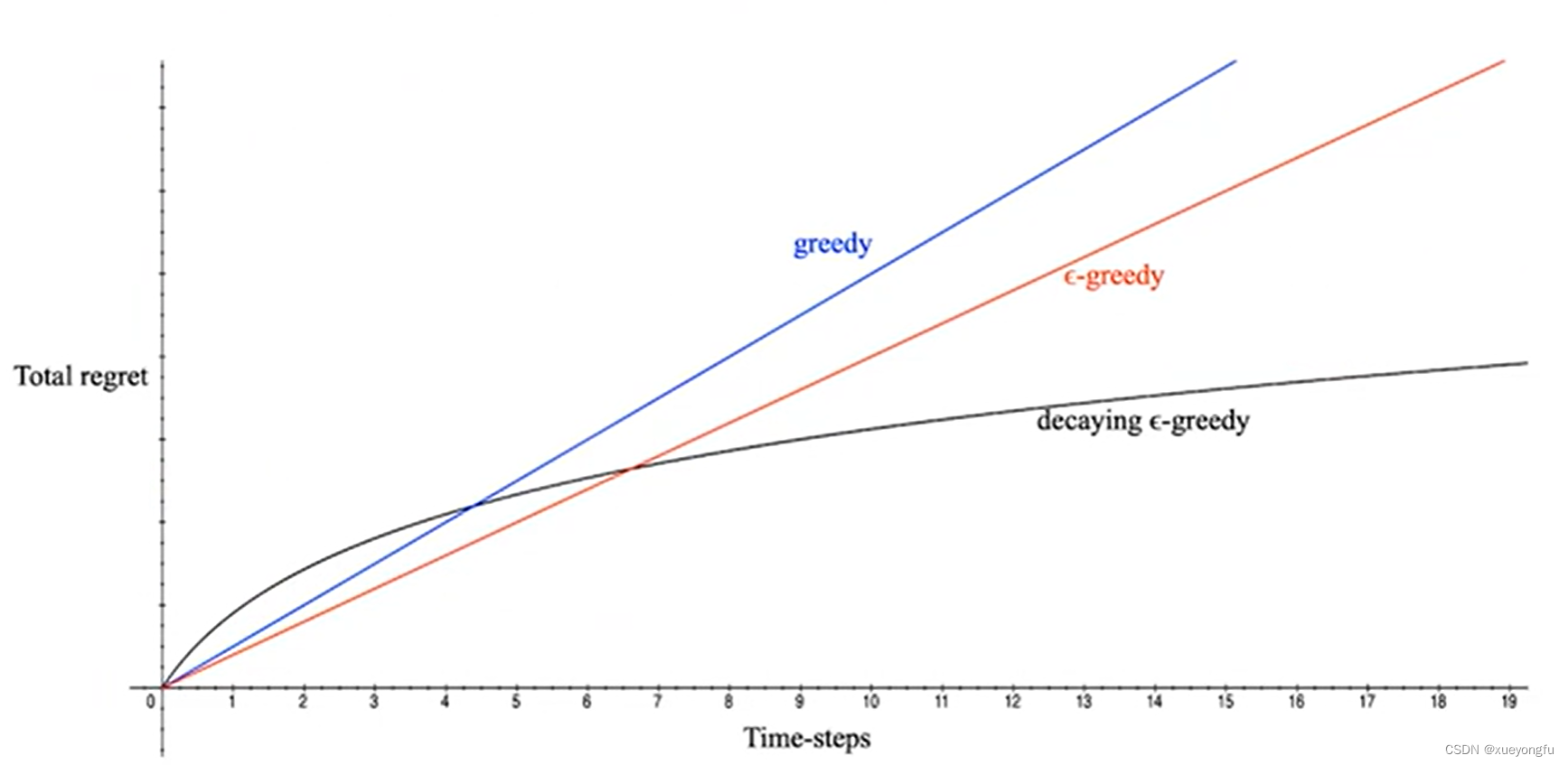
注:regret是决策和最优决策的收益差
Bellman等式
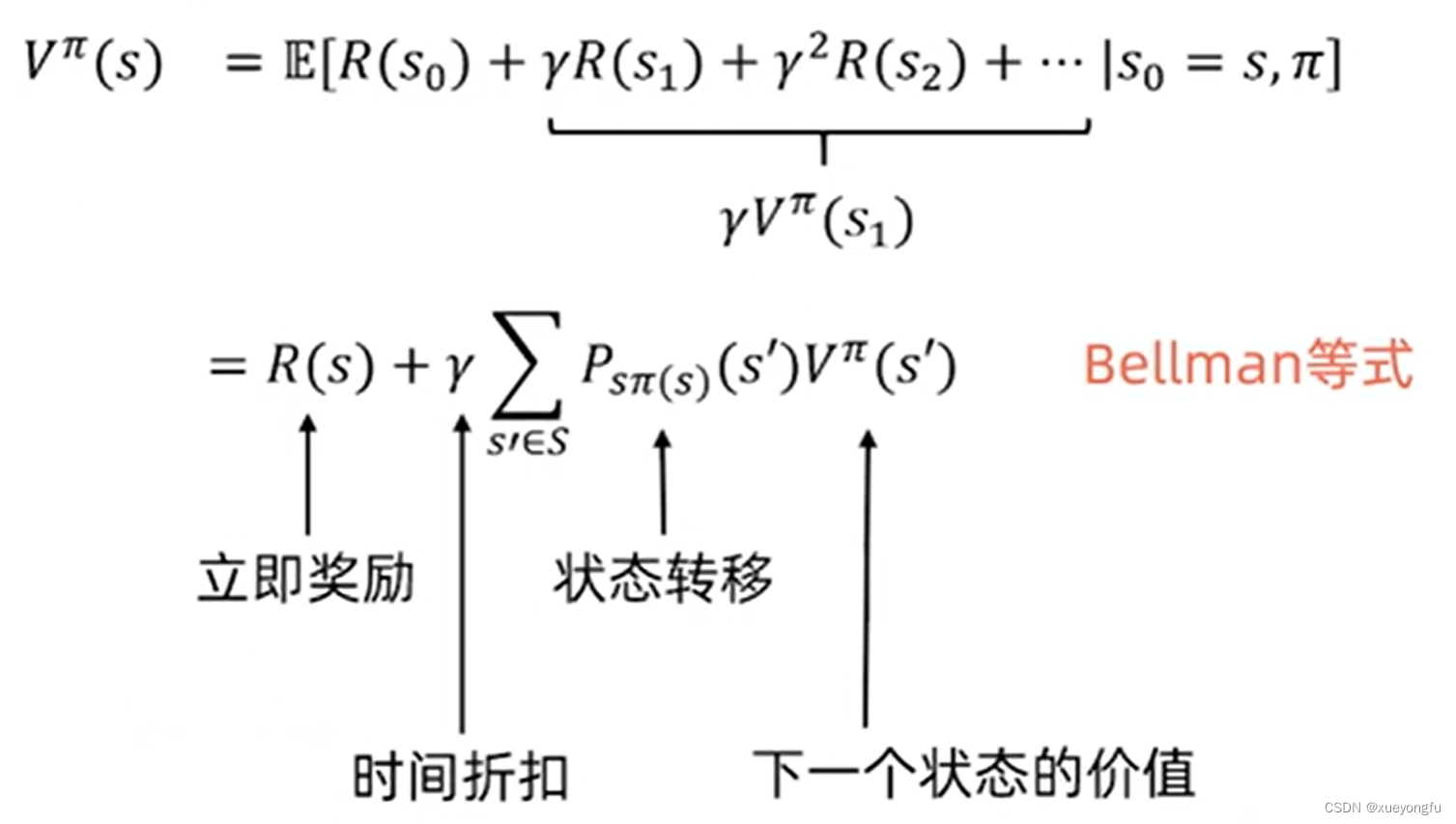
是状态s的期望累计收益,是未来收益的折现累计期望值;
是立即奖励;
对于状态s来说的最优价值函数是所有策略可获得的最大可能折扣奖励的和:
最优价值函数的bellman等式:
最优策略:
对状态s和策略:
基于动态规划的强化学习
价值函数和策略相关
可以最优价值函数和最优策略进行迭代更新:价值迭代、策略迭代
策略迭代
对于一个动作空间和状态空间有限的MDP,状态和行为都是有限的。
策略迭代过程:
1. 初始化
2. policy评估
3. policy提升
价值迭代
对于一个动作空间和状态空间有限的MDP,状态和行为都是有限的。
对于每个状态,初始化V(s)=0;
重复一下过程知道收敛:
常见的两种训练策略:
- 同步的价值迭代会储存两份价值函数的拷贝:
对于S中的所有状态s:
更新下面的式子:
- 异步价值迭代:
对与S中的所有状态s:
存在的问题是训练不太稳定
总结
1. 价值迭代是贪心更新法
2. 策略迭代中,用Bellman等式更新价值函数代价很大
3. 对于空间较小的MDP,策略迭代通常很快收敛
4. 对于空间较大的MDP,价值迭代更实用(效率更高)
5. 如果没有状态转移循环,最好使用价值选代
模型有关的强化学习
通过与环境交互采样多个episode的数据,然后从该“经验”中学习一个MDP模型
1. 学习状态转移概率
2. 学习奖励函数
参考:















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









