







我们经常听说,建模时应当尽量避免共线性(collinearity),共线性会导致参数估计不稳定、模型不可靠等等。那么共线性究竟有多可怕?共线性具体会带来什么问题?共线性得到的模型是否真的不行?笔者通过自己的一些思考,结合模拟数据的测试,对共线性的问题进行了些探讨。笔者拙见,如有纰漏,烦请指教。
其实很多变量都存在少量的共线性关系,但是对建模基本没有造成影响。本文主要探讨的是共线性较严重的情况。
转载请注明出处:https://blog.csdn.net/fjsd155/article/details/94852770
问题引入
现在模拟一个情景:现在需要建立一个关于消费水平的预测模型,对于每个消费者收集了3个变量:月收入 ,存款
,所在地区的经济水平
,假设月收入与存款之间存在线性关系,这里为了简化问题,假设是2倍的关系(当然实际情况不是2倍,而且不是严格线性关系),即
,并且假定消费水平与这3个变量之间的关系为:
。当然这些是假定的理想情况,实际关系要复杂很多。因果关系是存在的,月收入、存款或当地经济水平,任意一个因素都确实可能影响消费者的消费水平。
很明显,如果直接建模,变量之间存在严重的共线性关系。我们来看看具体会产生哪些现象。
代码测试
为了解答这个问题,我用 R 和 Python 做了些测试,下面以R 代码为例:
# Test the influence of collinearity
# add random effect for the variable
add_random<-function(x, sd){
# generate random effect on the full data, using sd=sd
len<-length(x)
y=x+rnorm(len, mean = 0, sd = sd*1)
# generate random effect on the random 20% of data, using sd=sd*1.6
len1<-round(len*0.2)
index<-sample(1:len,len1,replace = FALSE)
y[index]<-y[index]+rnorm(len1,mean = 0, sd = sd*1.6)
# generate random effect on the random 16% of data, using sd=sd*1.8
len2<-round(len*0.16)
index<-sample(1:len,len2,replace = FALSE)
y[index]<-y[index]+rnorm(len2,mean = 0, sd = sd*1.8)
return(y)
}
# x1, x2, x3 are the true factor that generate the event (result varaiable, Y)
x1<-rnorm(100, mean = 16, sd = 1)
x2<-2*x1
x3<-rnorm(100, mean = 18, sd = 3)
# add random effect for x1, x2, x3, using sd=0.001.
# to guarantee the collinearity, the random effect should be small.
x1<-add_random(x1, sd=0.001)
x2<-add_random(x2, sd=0.001)
x3<-add_random(x3, sd=0.001)
# validate the relationship between x1 and x2.
cor(x1, x2)
# [1] 0.9999981
# if the cause-effect relationship is: y=8*x1+8*x2+6*x3
y<-8*x1 + 8*x2 + 6*x3
y<-add_random(y, sd=1)
# validate the relationship between y and (8*x1 + 8*x2 + 6*x3).
cor(y, 8*x1 + 8*x2 + 6*x3)
# [1] 0.9990227
# x4 is the combination of x1 and x2 with the same weight.
x4<-x1+x2
# fit the model using x1 and x3
model_A<-lm(y~x1+x3)
summary(model_A)
# Coefficients:
# Estimate Std.Error t value Pr(>|t|)
# (Intercept) 0.14680 2.42208 0.061 0.952
# x1 24.03943 0.15005 160.207 <2e-16 ***
# x3 5.94959 0.04482 132.745 <2e-16 ***
# Multiple R-squared: 0.9981, Adjusted R-squared: 0.998
# fit the model using x2 and x3
model_B<-lm(y~x2+x3)
summary(model_B)
# Coefficients:
# Estimate Std.Error t value Pr(>|t|)
# (Intercept) 0.16278 2.42378 0.067 0.947
# x2 12.01916 0.07508 160.088 <2e-16 ***
# x3 5.94944 0.04485 132.643 <2e-16 ***
# Multiple R-squared: 0.9981, Adjusted R-squared: 0.998
# fit the model using x4 and x3
model_C<-lm(y~x4+x3)
summary(model_C)
# Coefficients:
# Estimate Std.Error t value Pr(>|t|)
# (Intercept) 0.15712 2.42293 0.065 0.948
# x4 8.01290 0.05003 160.146 <2e-16 ***
# x3 5.94949 0.04484 132.692 <2e-16 ***
# Multiple R-squared: 0.9981, Adjusted R-squared: 0.998
# fit the model using x1, x2 and x3. This is the case which existing the collinearity.
model_D<-lm(y~x1+x2+x3)
summary(model_D)
# Coefficients:
# Estimate Std.Error t value Pr(>|t|)
# (Intercept) 0.14387 2.43502 0.059 0.953
# x1 28.98087 75.73214 0.383 0.703
# x2 -2.47062 37.86443 -0.065 0.948
# x3 5.94962 0.04505 132.055 <2e-16 ***
# Multiple R-squared: 0.9981, Adjusted R-squared: 0.998 下面,我们对这些结果进行解读。
共线性对非共线性变量的影响
共线性对非共线性变量的影响。这句话有点拗口,具体来说,我想探讨的第一个问题是:如果保留共线性的变量,那么建模时,那些非共线性的变量的系数估计会不会受到影响?
由上述 model_D 可知, 的系数的估计没有受到任何影响。并且,在增加变量数目或改变样本量后重新进行测试,都显示:非共线性的变量的系数估计都没有受到任何影响。
因此得出结论1:共线性对非共线性的变量的系数估计不产生影响。
共线性对模型拟合优度的影响
共线性对模型拟合优度的影响。这句话有点学术化,具体来说,我想探讨的第二个问题是:如果保留共线性的变量,那么建立的模型的预测能力是否受到影响?
由上述 model_D 可知,模型的 没有下降。并且,在增加变量数目或改变样本量后重新进行测试,都验证了这个现象。
因此得出结论2:共线性不会影响模型的拟合优度。
共线性对模型产生的具体影响
由 model_D 可知,共线性变量 和
的系数估计变得不确定,方差很大,这在系数是否为 0 的检验( t 检验或 Wald 检验)中是会被认为没有统计学意义的(有可能该系数为 0 )。实际上,这是因为
和
的系数解空间是全体实数,只需要保证二者系数保持一定的关系即可。我们所看到的方差并不是无穷大,是因为在估计参数的时候,迭代次数有限制(当迭代次数达到某个值时,如果仍然没有确定系数的最佳选择,则程序认为该参数的估计无法收敛 [ converge ] )。
但是注意到, 的系数
和
的系数
,总是会近似保持一种关系:
。这是因为:
并且,在增加变量数目或改变样本量后重新进行测试,都验证了这个系数间的类似关联。当然,笔者在测试时还发现了几种情况(随噪声扰动大小不同而出现):第一种是各个系数的估计有显著意义且系数估计偏差很小(尽管变量间相关系数在0.99左右),第二种是各个系数的估计有显著意义但系数估计偏差较大,第三种是其中一个变量准确估计而另一个变量显示结果为NA(当完全没有噪声时)。由此可见,共线性存在的情况下,有时候也能准确估计系数,不过总体来说,系数的很难保证可靠(即使事后的参数检验有显著差异)。
建模后的参数检验,常常用来评估某些参数是否可能为 0 (系数为 0 的变量常被认为没有意义),而共线性变量的系数由于是可以取得 0 作为解的(无穷组解),因此参数检验认为这些系数可能为 0,但是其实这并不代表这些变量没有意义。为了避免这两种情况混淆,我们事先消除共线性也是不错的选择。另外,我们经常把参数估计不准的模型定性为不可靠的模型,但实际上,共线性并不导致模型不可靠,而是参数有无穷种选择,每种选择都是可以的。
因此得出结论3:共线性会使得共线性的变量的系数估计变得不可靠,但共线性变量的系数之间维持一种近似的特殊关系。
原理解析
以上分析了共线性造成的影响,得出了3个结论,那么这些结论背后的原理是什么呢?
首先我们看一下 、
与
之间的关系图(本应该是三维坐标图,这里就放几张截图吧):
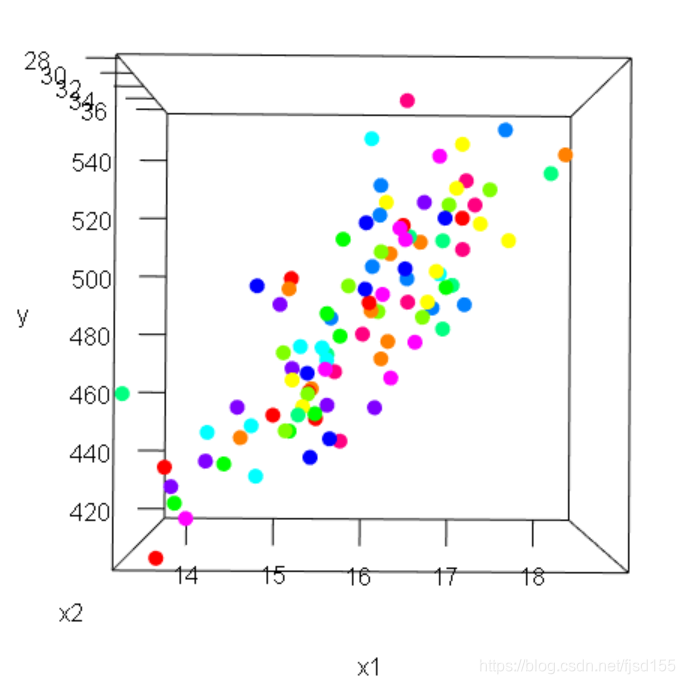
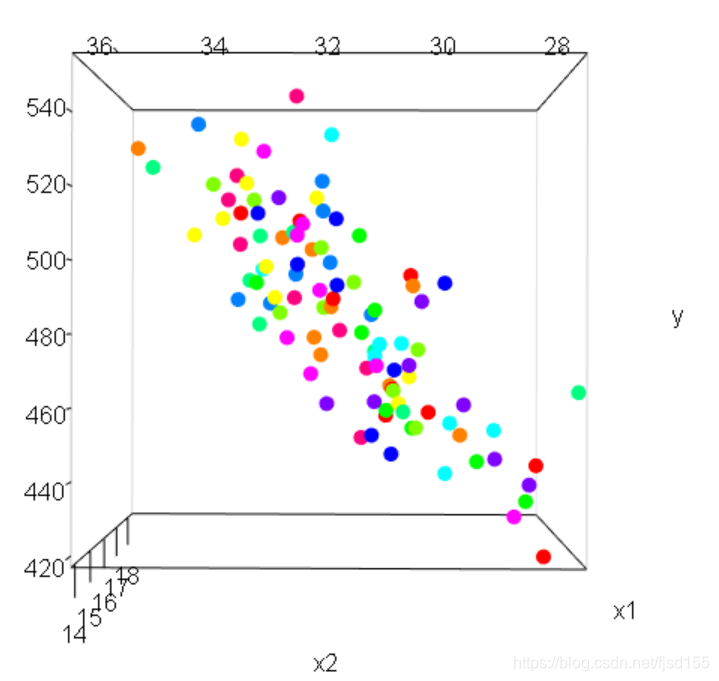
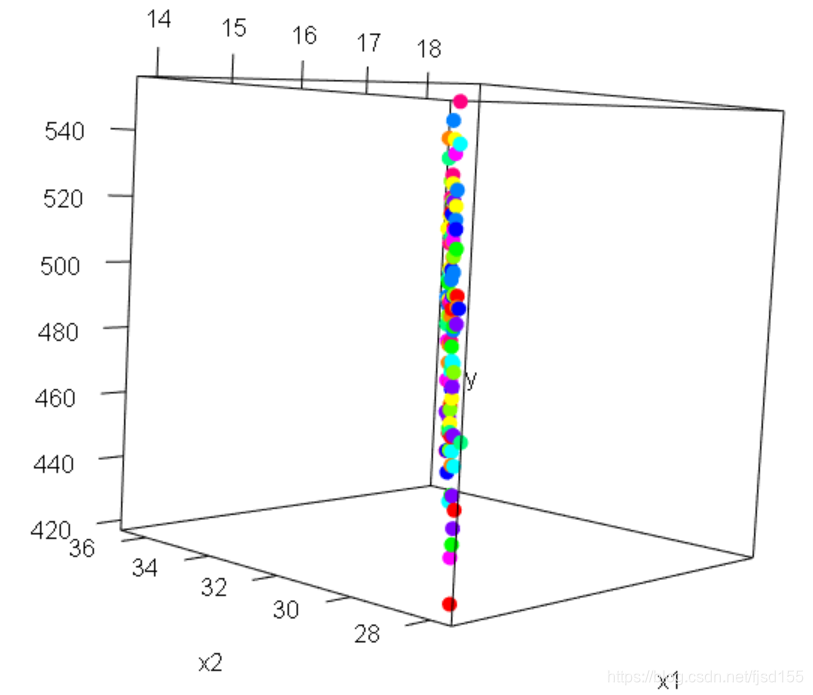
从这3张图可以看出,所有的点都分布在同一个平面上,可能你觉得没什么,这主要是因为还有 的存在,其实如果把
事先拟合进来(将
的方差部分消除,留下残差),那么所有的点将会近似分布在一条直线上。如果不信,我们假设一个模型:
我再次构建三维散点图,如下所示:
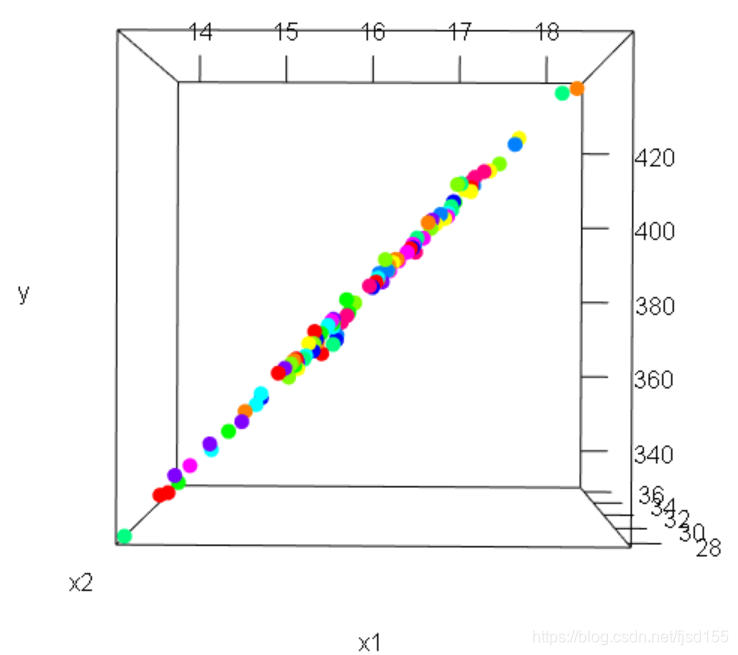
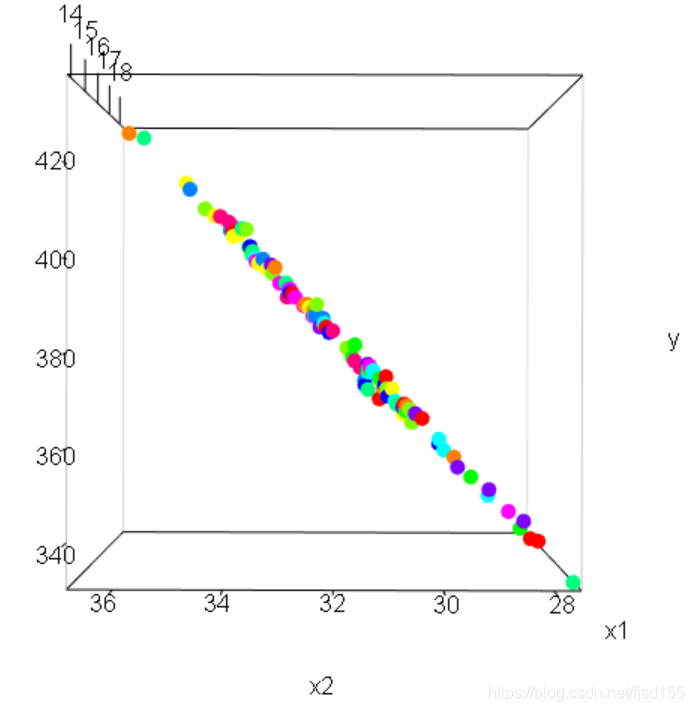
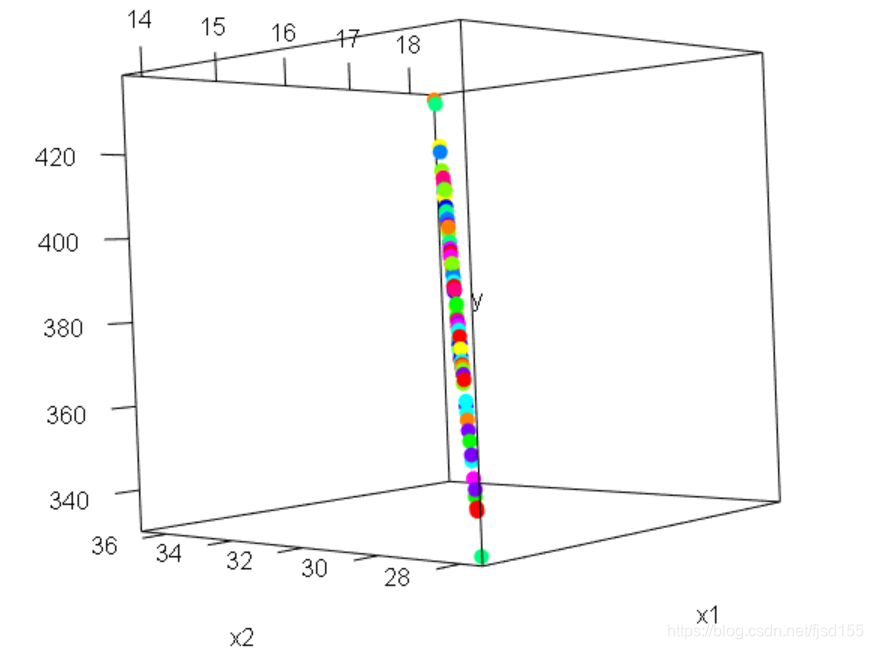
我们知道,1个自变量的回归模型是1条线(线性模型为直线、非线性模型为曲线或折线),2个自变量的回归模型是一个平面(线性模型为平面、非线性模型为曲面或折面),3个及以上自变量的回归模型为超面。那么对于如上这个两个自变量的线性回归模型来说,其解有无数个平面(这些平面有一个共同特点:都穿过这些散点所在的直线)。这也就解释了为什么共线性模型的系数有无数种可能(取值为全体实数,只需保证系数之间存在特殊的线性关系即可)。
而从损失函数的角度来讲,这种情况其实是损失函数的最小值处是一条水平的很细的沟、并且沟是可以无限延长的,沟的两侧会平滑地上升,这条沟所在的直线为:
损失函数的图像不太好画,只能请读者自行脑补啦。
根据这些,之前得到的那3个结论,也就顺理成章了。
这些结论,在Logistic 模型中仍然适用(笔者也进行了一些测试)。但注意,Logistic 的参数解其实不是唯一的,因为线性回归部分的拟合,其实是为了拟合成一个均值为 0 的变量 ,使得这个拟合的构造变量
取得正数值的部分样品尽可能多的是分类为1的样品,取得负数值的部分样品尽可能多的是分类为 0 的样品。各个参数成比例变大或缩小时,不影响这个构造变量
的分类能力,模型是不变的(详细解释可以类比笔者的另一篇博客:模型求解 中的“当 Logistic 回归遇到线性可分数据”部分的解释)。因此在得到测试结果时,需注意查看系数之间的比例关系是否保持稳定。
人为避开共线性
平时建模时,我们一般会事先把共线性的变量进行选择性保留,从而避免共线性。避免共线性有很多好处。上文中提到的,避开共线性可以让参数的估计变得稳定可靠,让模型更有说服力。
避开共线性,也就意味着共线性的变量中,只能保留其中一个。保留下来的变量,其数据将被纳入分析建模,但是该变量的系数的估计值其实不再是真实值了。从上述代码中的 model_A 和 model_B 的结果可以看出, 的系数
或
的系数
和事先给定的系数不一致。因此所得系数的意义的解读需要谨慎。
另外注意到,如果我们用先验知识知道 与
应当如何组合(即
),那么根据 model_C,我们是可以估计出所有变量的真实系数的。另外,随着噪声扰动的增大(使共线性关系稍微变弱),将共线性的变量直接建模,也仍然是可以估计出真实系数的(参数检验时可以得到有统计学差异,并且系数估计值是偏差都很小。但是根据结论3,又不太敢相信这个估计值)。
当我们只能获取少量信息时,我们很少遇到共线性的情况;后来我们能收集的信息增多,共线性出现了,这时我们又故意无视产生共线性的那些变量(只保留其中一个)。随着我们科技进步和数据收集能力增加,并且抛开“因果关系”建模的现象日益普遍,共线性的情况将会越来越常见。而随着我们经验的增加,或许有一天我们可以更有信心地保留共线性变量,从而利用更完备的信息来建立所有相关因素的“网络关联模型”。
避开共线性的技巧有很多,变量较少时,可以采用逐步回归的策略,逐个挑选变量;变量很多时可以用 LASSO 挑选变量进行建模。注意:主成分分析(PCA及相应的PCR主成分回归)、偏最小二乘法(PLS 及 OPLS)等方法并没有对变量进行选择,建模后仍然可以追溯相应的原始变量,是巧妙地避开了共线性造成的问题。具体方法此处不展开阐述,可以参考:
但是,这些方法都只是从变量的选择上避开了共线性,所得到的系数估计仍然是不准确的,需谨慎解读系数的意义。还有一种方法可以更准确地评估共线性变量的真实系数——分层匹配法。下文“解释变量的意义解读”中将进一步介绍这个方法。
共线性影响模型泛化的一种情况
其实,有一种情况下,共线性建模会影响模型的泛化能力。当共线性的情况是由数据偶然所造成时,换一批数据后,共线性关系如果消失了,那么使用原先数据训练的模型,在新的数据中预测准确性会很差。
这种情况是存在的,仍然以刚刚的模拟情景为例。当我们用之前包含共线性变量的模型去测试这样一群消费者:刚刚毕业进入IT大厂的高收入程序员。高收入程序员,由于刚刚毕业,存款极少,那么存款与收入之间的共线性关系就消失了,那么之前保留共线性所训练的模型就有可能出现问题(因为系数的估计是不准的)。
更一般的情况是,当前选定的样本中,某些变量确实存在共线性,但是当扩大样本量后,共线性的关系消失了,那么原先保留共线性建模所得到的规律,在扩大样本量后就不再适用了。这种现象,笔者称之为“数据偶然造成的共线性”。这种共线性会导致模型变得不准确,此时需要对变量进行取舍。比如在某个小样本中,变量A和B存在共线性,且这种共线性时偶然造成的,那么我们需要考虑仅保留A或B(在当前数据上看,保留A或B似乎是差不多的),假定我们保留了A,并且系数有统计学意义。当换一批数据,AB的共线性关系消失时,AB中有一个和结局变量的关系有可能变得不显著。如果此时A变得不显著了,说明我们保留变量时没选对,人为造成了假阳性和假阴性。因此,在共线性时,挑选变量这一过程又变得没那么轻而易举,不是一个LASSO或者逐步回归能简单处理的。似乎,更明智的做法是,将所有变量保留下来,等待其他数据进行验证,经得起考验的变量就可以考虑纳入模型了。
解释变量的意义解读
相比非线性模型,线性模型有一个好处,就是得到的模型参数(也就是变量的系数;非线性模型中的模型参数就不一定是系数了)是有实际意义的,模型本身也是基于概率和正态分布而推导的。因此,笔者习惯于优先使用广义线性模型拟合数据,如果效果不好,再使用非线性模型(如SVM、XGBoost、神经网络等)。
那么对于线性模型的解释变量的系数,究竟有怎样的意义呢?在没有共线性存在时,变量的系数的意义是确定的。在线性回归模型中,系数 的意义是:该变量每增加一个单位数值都会使结局变量增加
。而在 Logistic 回归中,系数的意义可以从OR的角度来解释(此处不赘述,Logistic 回归中十分重要的基本知识)。在理想状态下(完全不存在任何共线性时),单变量建模所得的系数与多变量建模所得的系数是一致的(可以程序模拟验证这一结论),因此其解释意义是不变的。
然而,当存在共线性时,情况就不一样了。若直接包含共线性建模,则所得系数无法收敛(系数取值有无数种可能),无法解释。若只保留共线性变量中的一个变量进行建模,则得到的系数的解释意义,就不再应该是该系数原本的解释意义了,严格来说应该是共线性变量群体的综合意义。或者说,保留的变量是一群变量的“代表”。因此在选择性保留变量时,我们实际上已经赋予这个变量新的含义了,这一点值得注意。这一点有点像主成分分析(PCA)的哲学,保留的变量其实是一个复合含义的变量(虽然表明上没有做成分映射、就只是单纯保留了这个变量)。比如,上述 model_A。仅保留了月收入和当地经济水平这两个变量,但是此时对于月收入的系数(w1=24)的解读,应该是:由月收入和存款构成新的变量(我们称之为“个人经济能力”),该变量采用的数据暂时仍然是月收入的数据,该变量带来的效应可以用 w1来衡量的。
我们常说,变量的系数代表着变量的重要性或者贡献。但其实这个说法是有问题的。第一,变量的系数会受到数据方差和尺度的影响,不同方差和尺度的变量,比较其系数大小是不公平的。第二,变量的系数并非就反应了这个变量的真实意义(存在共线性时,其代表的是共线性变量群体的综合意义)。
基于此,我们需要更好的办法去评估各个变量的重要性。在线性回归中,我们可以评估各个变量的 贡献,在 Logistic 回归中我们可以使用似然比检验中的卡方值(或Wald检验近似替代的卡方值,Wald检验的卡方值就等于“系数/系数标准差”。Frank Harrell 教授很推荐使用Wald检验的卡方值来表示变量的重要性。不过个人对Wald检验的卡方值仍然持保守态度)。
进行多变量建模,我们一般会先对变量进行标准化处理(normalization,先中心化再尺度化),这样应该也是可以让各个变量在比较系数时变得公平。此外,标准化处理还有个好处,就是可以加快梯度下降的效率(当各个变量方差差别较大时,各个变量对应的系数的收敛速度差别很大,在CNN训练时也有这个问题,可以采用不同的学习率对各个参数更新迭代,也可以采用标准化的策略)。大概,BatchNormalization有助于训练深度模型,是有这个原因在里面的吧。
既然存在共线性(无论逻辑上还是数据集中都存在相关性),那么共线性变量的真实系数无法估计,是不是就真的没办法求解了呢?其实还有一个办法——分层匹配法。分层匹配法的目的是,针对共线性的变量,人为选择一个数据子集,使得共线性变量在这个数据子集中的相关性变弱,然后在这个数据子集中评估共线性变量的真实系数。比如,我们选择“刚毕业的高收入程序员”这个数据子集,则存款与收入之间的共线性关系就消失了,在这个数据子集中可以估计消费水平这个模型中各个变量的真实系数。这种思想就是“控制混杂因素”,当然在这里我们将“协变量”当作混杂因素来处理了。其缺陷在于,分层匹配法得到的数据子集的样本量往往严重缩水(匹配较为严格时),此时可以放宽匹配标准或采用倾向性评分匹配法来构建这个数据子集(可参考:辩证看待倾向性评分法)。
更广泛的场景
实际建模中,情况要比刚刚的讨论复杂很多,我们甚至不考虑“因果关系”,甚至试图建立“表型与表型之间关系”的模型,这将很可能引入更多的共线性变量!典型的案例是代谢组学研究,比如探索代谢物与疾病疗效之间的关系(代谢物是表型、疗效也是表型)的问题中,因变量(各个代谢物)之间存在高度的共线性。
因此,我们甚至会发现,共线性的情况变得更加普遍了。我们可以找到很多存在线性关系的特征,这就使得建模更加费劲了。当然,如果没有“因果关系”,建模时也就不那么关注系数的解释意义了(机器学习的黑箱也是如此,各个变量的解释意义被忽视)。那么,既然如此,参数是否收敛也就变得不那么重要,只要预测能力强且泛化能力强(外推性好),那就行啦。具体参数是啥不重要了,当作“黑箱模型”啦。
规律的简单性与复杂性
规律(模型)是简单的。我们可以利用少量关键的信息建立模型,能保证模型相对稳定。因为使用的特征是极其关键的特征,甚至是整个研究群体的普遍特征(比如模拟情景中的“当地经济水平与消费水平存在普遍的相关规律”),所以模型能保证稳定性、广泛适用性。
规律(模型)是复杂的。我们常常对简单的模型表示不满足(总是希望追求完美),因为预测结果相对粗糙,不够精准,我们希望能更精准地实现预测。那么就需要找出更多有用的信息,加入更多的特征进行建模。理想状态下,当我们找到所有有用的信息,建立因果作用网络模型,那么预测能力可以接近完美。但是我们找到的规律总是不全面的,由于规律的不全面,导致某些规律只适用于部分亚群体。尤其是存在共线性关系时,这将使得建立的模型变得不可靠(我们很难反推出各个共线性变量的真实系数);这时大家往往宁愿舍弃共线性的变量,来谋得模型的稳定。但是,如果我们能够挖掘到更多有用的信息(比如建立更复杂的理论或者加入更多的先验知识,推导出各个共线性变量的真实系数,甚至建立各种非线性关系、网络关系等),有可能可以模拟出真实的规律。
不同的规律,复杂性是不同的。有的规律本身就很简单,那么就很容易模拟得很接近真实(比如根据身高体重来预测合适的衣服尺寸)。而有的规律本身就很复杂(比如预测任意一个人得癌症的风险),则模型是复杂的(当然我们常常会根据少数关键信息建立简单的模型)。


















 5314
5314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











