









基于物品的协同过滤算法(Item-Based Collaborative Filtering)是目前业界应用最多的算法,亚马逊、Netflix、Hulu、YouTube都采用该算法作为其基础推荐算法。
基于用户的协同过滤算法有一些缺点:随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似平方关心。并且,基于用户的协同过滤算法很难对推荐结果做出解释。因此亚马逊提出了基于物品的协同过滤算法。
基于物品的协同过滤算法给用户推荐那些和他们之前喜欢的物品相似的物品。不过ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算用户之间的相似度,也就是说物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B(这一点也是基于物品的协同过滤算法和基于内容的推荐算法最主要的区别)。同时,基于物品的协同过滤算法可以利用用户的历史行为给推荐结果提供推荐解释,用于解释的物品都是用户之前喜欢的或者购买的物品。
ItemCF的公式可参考网上。
1、数据集:https://grouplens.org/datasets/movielens/ 下载ratings.csv
格式如下:
| userId | movieId | rating |
| 1 | 31 | 2.5 |
| 1 | 1029 | 3 |
| 1 | 1061 | 3 |
| 1 | 1129 | 2 |
| 1 | 1172 | 4 |
| 1 | 1263 | 2 |
| 1 | 1287 | 2 |
| 1 | 1293 | 2 |
| 1 | 1339 | 3.5 |
| 1 | 1343 | 2 |
| 1 | 1371 | 2.5 |
2、参考代码:
# -*- coding: utf-8 -*-
'''
Created on 2017年9月18日
@author: Jason.F
'''
import math
import random
import os
from itertools import islice
class ItemBasedCF:
def __init__(self, datafile = None):
self.datafile = datafile
self.readData()
self.splitData()
def readData(self,datafile = None):
self.datafile = datafile or self.datafile
self.data = []
file = open(self.datafile,'r')
for line in islice(file, 1, None): #file.readlines():
userid, itemid, record = line.split(',')
self.data.append((userid,itemid,float(record)))
def splitData(self,data=None,k=3,M=10,seed=10):
self.testdata = {}
self.traindata = {}
data = data or self.data
random.seed(seed)#生成随机数
for user,item,record in self.data:
self.traindata.setdefault(user,{})
self.traindata[user][item] = record #全量训练
if random.randint(0,M) == k:#测试集
self.testdata.setdefault(user,{})
self.testdata[user][item] = record
def ItemSimilarity(self, train = None):
train = train or self.traindata
self.itemSim = dict()
item_user_count = dict() #item_user_count{item: likeCount} the number of users who like the item
count = dict() #count{i:{j:value}} the number of users who both like item i and j
for user,item in train.items(): #initialize the user_items{user: items}
for i in item.keys():
item_user_count.setdefault(i,0)
item_user_count[i] += 1
for j in item.keys():
if i == j:
continue
count.setdefault(i,{})
count[i].setdefault(j,0)
count[i][j] += 1
for i, related_items in count.items():
self.itemSim.setdefault(i,dict())
for j, cuv in related_items.items():
self.itemSim[i].setdefault(j,0)
self.itemSim[i][j] = cuv / math.sqrt(item_user_count[i] * item_user_count[j] * 1.0)
def recommend(self,user,train = None, k = 10,nitem = 5):
train = train or self.traindata
rank = dict()
ru = train.get(user,{})
for i,pi in ru.items():
for j,wj in sorted(self.itemSim[i].items(), key = lambda x:x[1], reverse = True)[0:k]:
if j in ru:
continue
rank.setdefault(j,0)
rank[j] += pi*wj
return dict(sorted(rank.items(), key = lambda x:x[1], reverse = True)[0:nitem])
def recallAndPrecision(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
hit = 0
recall = 0
precision = 0
for user in test.keys():
tu = test.get(user,{})
rank = self.recommend(user,train = train,k = k,nitem = nitem)
for item,_ in rank.items():
if item in tu:
hit += 1
recall += len(tu)
precision += nitem
return (hit / (recall * 1.0),hit / (precision * 1.0))
def coverage(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
recommend_items = set()
all_items = set()
for user in test.keys():
for item in test[user].keys():
all_items.add(item)
rank = self.recommend(user, train, k = k, nitem = nitem)
for item,_ in rank.items():
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
def popularity(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
item_popularity = dict()
for user ,items in train.items():
for item in items.keys():
item_popularity.setdefault(item,0)
item_popularity[item] += 1
ret = 0
n = 0
for user in test.keys():
rank = self.recommend(user, train, k = k, nitem = nitem)
for item ,_ in rank.items():
ret += math.log(1+item_popularity[item])
n += 1
return ret / (n * 1.0)
def testRecommend(self,user):
rank = self.recommend(user,k = 10,nitem = 5)
for i,rvi in rank.items():
items = self.traindata.get(user,{})
record = items.get(i,0)
print ("%5s: %.4f--%.4f" %(i,rvi,record))
if __name__ == "__main__":
ibc=ItemBasedCF(os.getcwd()+'\\ratings.csv')#初始化数据
ibc.ItemSimilarity()#计算物品相似度矩阵
ibc.testRecommend(user = "345") #单用户推荐
print ("%3s%20s%20s%20s%20s" % ('K',"recall",'precision','coverage','popularity'))
for k in [5,10,15,20]:
recall,precision = ibc.recallAndPrecision( k = k)
coverage =ibc.coverage(k = k)
popularity =ibc.popularity(k = k)
print ("%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k,recall * 100,precision * 100,coverage * 100,popularity))问题:python循环太慢,要想办法在pandas的dataframe内完成。
补充:在ItemSimilarity函数中,会出现物品只有一次的行为,所以代码更改为:
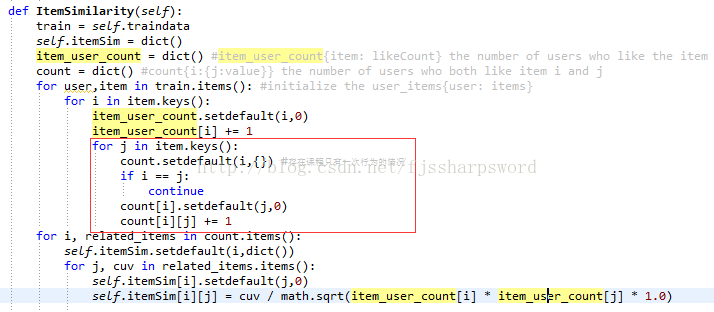
再补充:在recommend函数中,如果排除原物品,则会出现准确率和召回率为零的情况,修正如下:

发现项亮的《推荐系统实践》中代码也是如此,可见是一个大的问题,没有人发现和提出。















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









