






解决过拟合的方法和代码实现,已经写过Dropout层,L1 L2正则化,提前终止训练,上一篇文章写了Batch Normalization,本篇将介绍另一个Normalization,Layer Normalization.
1.Batch Normalization的缺陷(为何要使用Layer Normalization)
BN的缺陷主要有两点:
1.受到batch大小的影响
上一节通过BN的概念和代码,已经看出,BN中计算的是每个batch样本的均值和方差,再将其用到该batch中进行归一化。因此,当batch样本数过小时,无法反映全局的统计分布,造成效果很差。
2.不适用于RNN
在一个batch中,通常各个样本的长度都是不同的,当统计到比较靠后的时间片时,例如图中t>4时,这时只有一个样本还有数据,基于这个样本的统计信息不能反映全局分布,所以这时BN的效果并不好。
另外如果在测试时我们遇到了长度大于任何一个训练样本的测试样本,我们无法找到保存的归一化统计量,所以BN无法运行。
| RNN中使用BN会导致batchsize过小的问题 |
|---|
以上两点缺陷,其实都是由于batch数量过少引起的,若模型没有使用RNN,可以通过增加batch大小来解决。使用RNN时,可以截断时间步,使得各个时间步的样本数量相同,但这样抛弃了许多信息,并不建议使用。当没有截断时间步时,RNN靠后时间步样本少的问题无法解决,因此无法使用BN。
针对batch数过少引起问题,提出了Layer Normalization加以解决。
2.Layer Normalization
一张很直观的图,对比BN和LN:
| LN(左)和BN(右)对比示意图 |
|---|
LN和BN不同点是归一化的维度是互相垂直的,如图1所示。在图中 N 表示样本轴, C
表示通道轴,F是每个通道的特征数量。BN如右侧所示,它是取不同样本的同一个通道的特征做归一化;LN则是如左侧所示,它取的是同一个样本的不同通道做归一化。
BN和LN的区别只是选取的轴不同,其后续计算公式都是一样的。
3.Layer Normalization的代码实现
keras源码没有的实现,但网上有已经写好了的LN包,使用pip install keras-layer-normalization安装后,使用from keras_layer_normalization import LayerNormalization调用LayerNormalization,将其加入模型。
import keras
from keras.models import *
from keras.layers import *
from keras_layer_normalization import LayerNormalization
model = Sequential()
model.add(Dense(1024, input_shape=(10000,)))
model.add(LayerNormalization())
model.add(Activation('tanh'))
其中需要注意的是:
LN与BN一样,其输入应该是激活前的输入(已经做完线性变换,但还未激活),在上面的代码中,LN加在Dense和Activation中间。
keras_layer_normalization中LayerNormalization源码核心部分:
def call(self, inputs, training=None):
mean = K.mean(inputs, axis=-1, keepdims=True)
variance = K.mean(K.square(inputs - mean), axis=-1, keepdims=True)
std = K.sqrt(variance + self.epsilon)
outputs = (inputs - mean) / std
if self.scale:
outputs *= self.gamma
if self.center:
outputs += self.beta
return outputs
计算mean,variance(注意axis设置为-1,因为是对样本最后一个轴做均值、方差),之后按照公式:
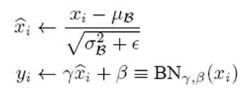
更新输入即可。
LN的实现远比BN简单的多,因为计算均值时不用考虑batch,因此直接将样本输入直接计算,不用对训练和测试采用不同的方法,也就不用更新测试时使用的mean和var。
LN的效果与BN相似,加速收敛,增加分类效果,使调参更简单,一定程度上防止过拟合。















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









