







目录
过程分析
先解决VScode写python输出中文就乱码的问题
参考了这个,顺利解决。(困扰了我好久,一直忍忍忍,今天不忍了。)
库的导入
import requests# 请求
from bs4 import BeautifulSoup #解析网页
import pandas as pd #数据处理确定URL,发出HTTP请求
写好目标网页(steam促销网站)的url,伪装成浏览器发送GET请求,检查请求是否成功。
#Steam热销产品页面的URL
url = 'https://store.steampowered.com/search/?filter=topsellers'
#伪装成浏览器发送GET请求到该URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() #检查请求是否成功
#如果请求成功,继续处理响应数据
print("请求成功")
except requests.exceptions.HTTPError as e:
#如果请求失败,处理 HTTPError 异常
print(f"请求失败: {e}")解析网页内容并返回结果
#Steam热销产品页面的URL
url = 'https://store.steampowered.com/search/?filter=topsellers'
#伪装成浏览器发送GET请求到该URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.raise_for_status() #检查请求是否成功
# 解析页面的HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 输出返回的内容以检查
print(soup.prettify())寻找标签和属性,进行匹配
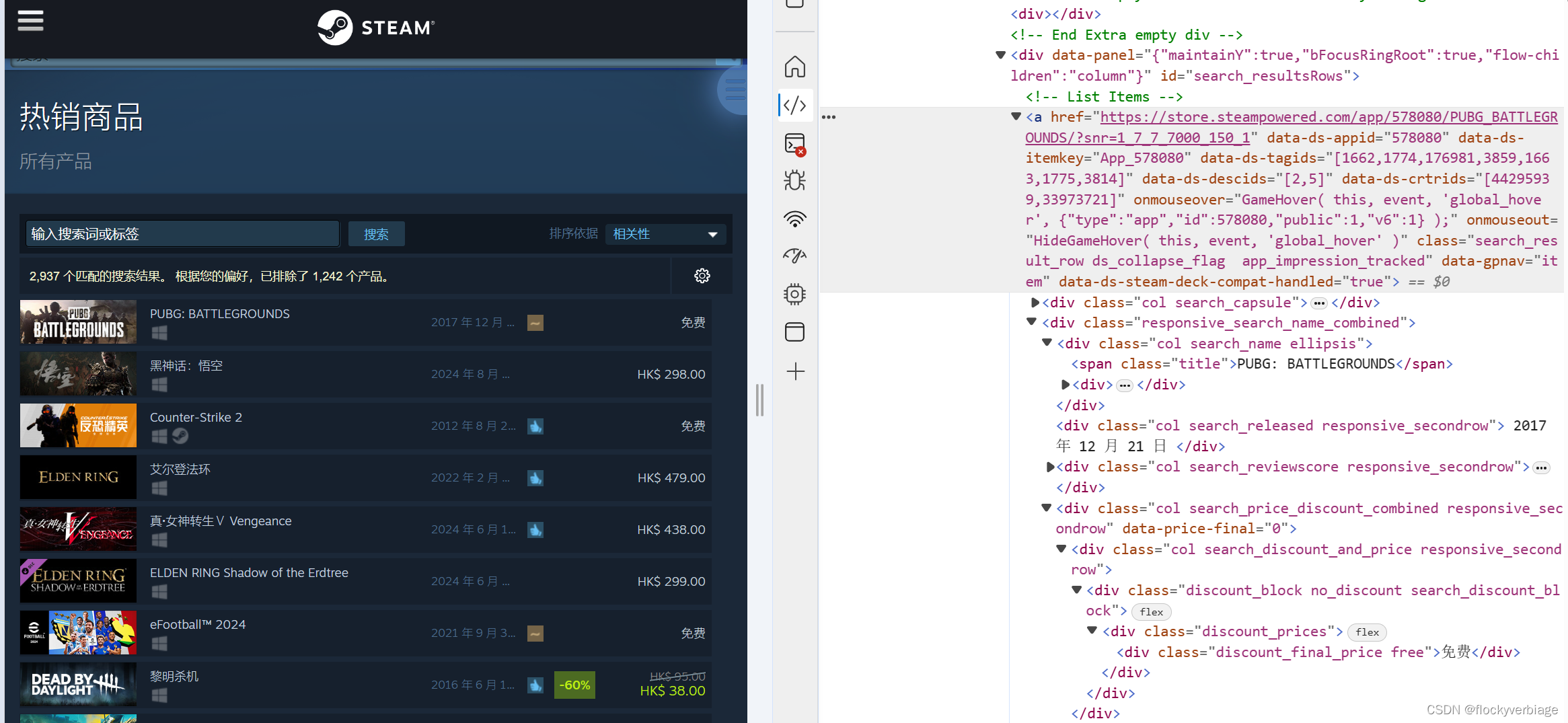
图中选中的部分就是第一款游戏对应的元素区域,然后进一步寻找游戏名称,销售价格和发行时间。利用列表嵌套将爬取的元素保存,转换为dataframe结构,并保存到本地Excel文件中。
整体代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
#Steam热销产品页面的URL
url = 'https://store.steampowered.com/search/?filter=topsellers'
#伪装成浏览器发送GET请求到该URL
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.raise_for_status() #检查请求是否成功
# 解析页面的HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 找到所有的游戏条目
games = soup.select('a[data-ds-appid][data-ds-itemkey][onmouseout][data-gpnav]')
print(f"找到的游戏条目数: {len(games)}")
game_list = []
for game in games:
title = game.find('span', class_='title').text.strip() # 游戏标题
price = game.find('div', class_='discount_final_price').text.strip() # 游戏价格
release_date = game.find('div', class_='col search_released responsive_secondrow').text.strip() # 发行日期
game_list.append({
'title': title,
'price': price,
'release_date': release_date
})
# 将游戏列表创建为一个DataFrame
df = pd.DataFrame(game_list)
# 将 DataFrame 存储到 Excel 文件
df.index = df.index + 1
excel_file = 'example.xlsx' # 文件名和路径
df.to_excel(excel_file, index=True)
print(f"DataFrame 已成功存储到 {excel_file}")
学习总结
BeautifulSoup库中查找元素的两种主要方法
- find和find_all
- select和select_one
find:find_all() 方法用来搜索当前 tag 的所有子节点,并判断这些节点是否符合过滤条件,最后以列表形式将符合条件的内容返回。find() 方法与 find_all() 类似,不同之处在于 find_all() 会将文档中所有符合条件的结果返回,而 find() 仅返回一个符合条件的结果。
select:BS4 支持大部分的 CSS 选择器,比如常见的标签选择器、类选择器、id 选择器,以及层级选择器。Beautiful Soup 提供的select() 方法,通过向该方法中添加选择器,就可以在 HTML 文档中搜索到与之对应的内容。
相对比而言,find更加普适,select语法在使用上更为便利。写代码的过程中我最初是用find查找游戏条目,但总是出问题,自己也搞不明白。用了select标了几个属性轻松找到,感觉是好使的。感觉前端真的很有意思来的,有机会学一下CSS!
下一步准备研究的问题
- 动态页面的处理(模拟翻页)进而得到全部数据
- 更多的属性爬取
- 爬取到数据的格式化处理
- ......















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









