







目录
数据来源
https://www.kaggle.com/datasets/rabieelkharoua/students-performance-dataset/data
数据简介
该数据集包含2392名高中生的全面信息,详细介绍了他们的人口统计、学习习惯、父母参与、课外活动和学习成绩。成绩类别将学生的成绩分为不同的类别,为教育研究、预测建模和统计分析提供了一个强大的数据集。
变量目录
| 变量 | 变量说明 | 编码 |
| 学生ID | 分配给每个学生(1001至3392)的唯一标识符 | |
| 年龄 | 学生的年龄,从15岁到18岁不等 | |
| 性别 | 学生的性别 | 0代表男性,1代表女性 |
| 种族 | 学生的种族 | 0:高加索 1:非裔美国人 2:亚洲人 3:其他 |
| 父母教育 | 父母的教育水平 | 0:无 1:高中 2:一些大学 3:学士 4:更高 |
| 每周学习时间 | 学生每周的学习时间 | |
| 缺席次数 | 一学年中的缺席次数,从0到30不等 | |
| 辅导 | 辅导状态 | 0表示否,1表示是 |
| 父母支持 | 父母支持的级别 | 0:无 1:低 2:中等 3:高 4:非常高 |
| 课外活动 | 参加课外活动 | 0表示否,1表示是 |
| 运动 | 参与运动 | 0表示否,1表示是 |
| 音乐 | 参与音乐活动 | 0表示否,1表示是 |
| 志愿服务 | 参与志愿服务 | 0表示否,1表示是 |
| GPA | 平均成绩为2.0至4.0 | |
| 成绩类别 | 根据平均成绩对学生的成绩进行分类 | 0:“A”(GPA>=3.5) 1:'B'(3.0<=GPA<3.5) 2:'C'(2.5<=GPA<3.0) 3:“D”(2.0<=GPA<2.5) 4:“F”(GPA<2.0) |
初步拟合
数据处理和可视化
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import statsmodels.api as sm
#数据处理与预览
df = pd.read_csv('Student_performance_data _.csv')
df = df.drop(columns=['StudentID','GradeClass'])
df.head() #查看前五行数据
# 检查缺失值
#print(df.isnull().sum())
#print(df.shape) #数据维度
#print(df.isnull().sum()) #统计数据空值
#df.info() #每列的数据类型非空值的数量和占用的内存
#df.describe() #数值列的描述性统计信息
# 假设 X 包含所有特征列,y 是目标变量列(
X = df.drop(columns=['GPA']) # 替换为实际的特征列名称
y = df['GPA'] # 替换为实际的目标变量列名称
# 拆分数据集为训练集和测试集,test_size 指定测试集的比例
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将 X_train 和 y_train 合并成一个数据框
train_df = pd.concat([X_train, y_train], axis=1)
# 计算相关系数矩阵
correlation_matrix_train = train_df.corr()
# 可视化相关性矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix_train, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Correlation Matrix')
plt.show()得到热力图如下
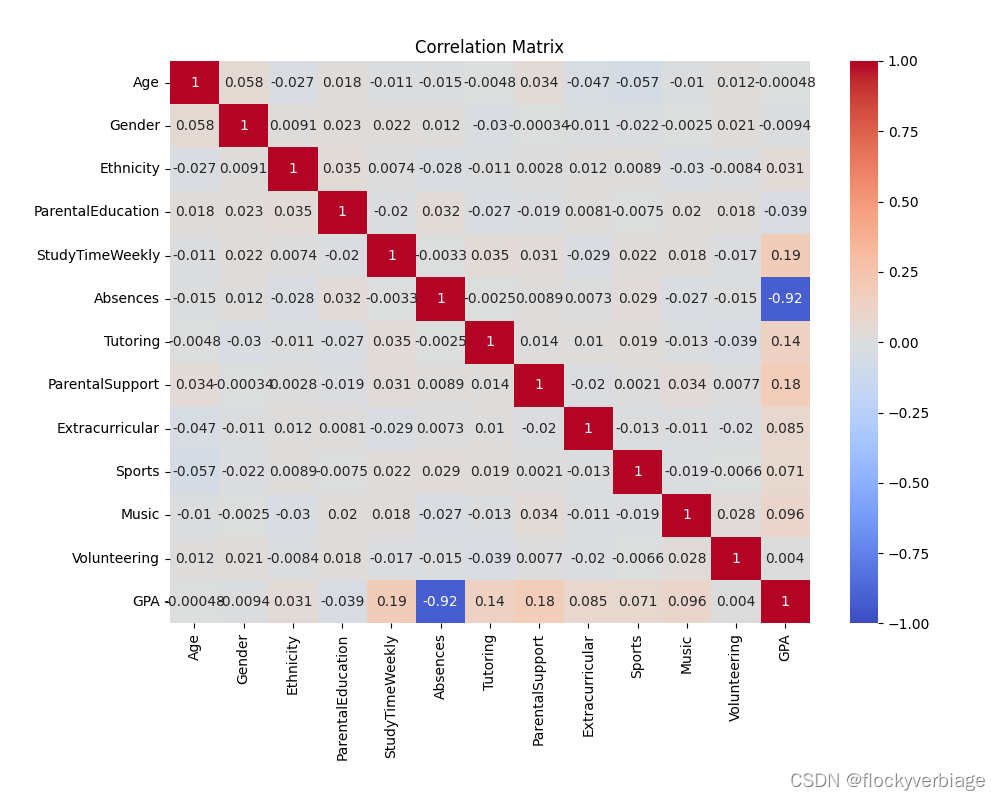
最明显的就是GPA和课堂缺席率有负相关性。
建立最小二乘回归模型,显著性检验
# 向 X_train 添加常数项
X_train = sm.add_constant(X_train)
# 拟合普通最小二乘回归模型
model = sm.OLS(y_train, X_train)
results = model.fit()
# 输出系数的显著性检验结果
print(results.summary())
结果
OLS Regression Results
==============================================================================
Dep. Variable: GPA R-squared: 0.954
Model: OLS Adj. R-squared: 0.954
Method: Least Squares F-statistic: 3295.
Date: Sat, 15 Jun 2024 Prob (F-statistic): 0.00
Time: 17:33:50 Log-Likelihood: 401.06
No. Observations: 1913 AIC: -776.1
Df Residuals: 1900 BIC: -703.9
Df Model: 12
Covariance Type: nonrobust
=====================================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------------
const 2.6051 0.069 37.883 0.000 2.470 2.740
Age -0.0057 0.004 -1.424 0.155 -0.014 0.002
Gender 0.0105 0.009 1.164 0.245 -0.007 0.028
Ethnicity 0.0047 0.004 1.085 0.278 -0.004 0.013
ParentalEducation 0.0001 0.005 0.027 0.978 -0.009 0.009
StudyTimeWeekly 0.0290 0.001 36.687 0.000 0.027 0.031
Absences -0.0995 0.001 -187.141 0.000 -0.101 -0.098
Tutoring 0.2583 0.010 26.279 0.000 0.239 0.278
ParentalSupport 0.1478 0.004 36.640 0.000 0.140 0.156
Extracurricular 0.1895 0.009 20.394 0.000 0.171 0.208
Sports 0.1850 0.010 18.861 0.000 0.166 0.204
Music 0.1525 0.011 13.467 0.000 0.130 0.175
Volunteering -0.0053 0.012 -0.425 0.671 -0.030 0.019
==============================================================================
Omnibus: 6.677 Durbin-Watson: 2.004
Prob(Omnibus): 0.035 Jarque-Bera (JB): 6.161
Skew: -0.095 Prob(JB): 0.0459
Kurtosis: 2.797 Cond. No. 382.
==============================================================================
结论就是 年龄、性别、种族和志愿时长并不显著,考虑剔除。
预测集对比
# 评估预测效果
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
# 绘制预测值与真实值的散点图
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--')
plt.title('Actual vs Predicted')
plt.xlabel('Actual GPA')
plt.ylabel('Predicted GPA')
plt.grid(True)
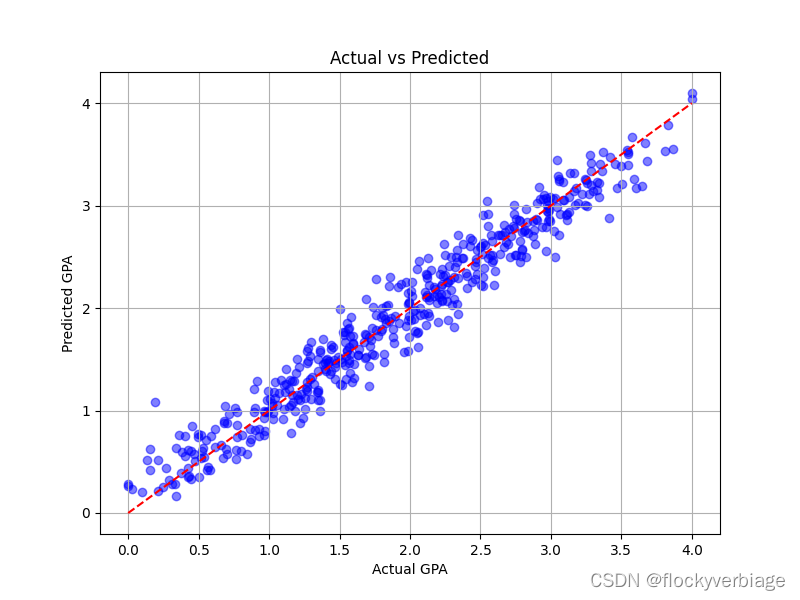
plt.show()结果
Mean Squared Error (MSE): 0.03866144149454248
R-squared (R2): 0.9532471681022929
均方误差0.0386,决定系数0.95
假设验证
自相关
Durbin-Watson: 2.004 不显著
多重共线性
计算方差膨胀因子
# 计算VIF
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X_train, i) for i in range(X_train.shape[1])]
vif["features"] = X_train.columns
print(vif)
VIF Factor features
0 233.395154 const
1 1.011536 Age
2 1.006364 Gender
3 1.004411 Ethnicity
4 1.005537 ParentalEducation
5 1.005112 StudyTimeWeekly
6 1.004375 Absences
7 1.005094 Tutoring
8 1.004379 ParentalSupport
9 1.004479 Extracurricular
10 1.005959 Sports
11 1.005235 Music
12 1.003999 Volunteering
计算条件数(才发现results已经给了:Cond. No.)
# 计算条件数
condition_number = np.linalg.cond(X_train)
print("Condition Number:", condition_number)Condition Number: 382.07966625340686
方差膨胀因子都很小,但是条件数还是挺大的。
二次数据处理
考虑移除一些变量:年龄、性别、种族和志愿时长
回归结果发现此时除了父母的教育水平其他变量都显著。决定也予以剔除。
剔除变量后绘制热力图如下:
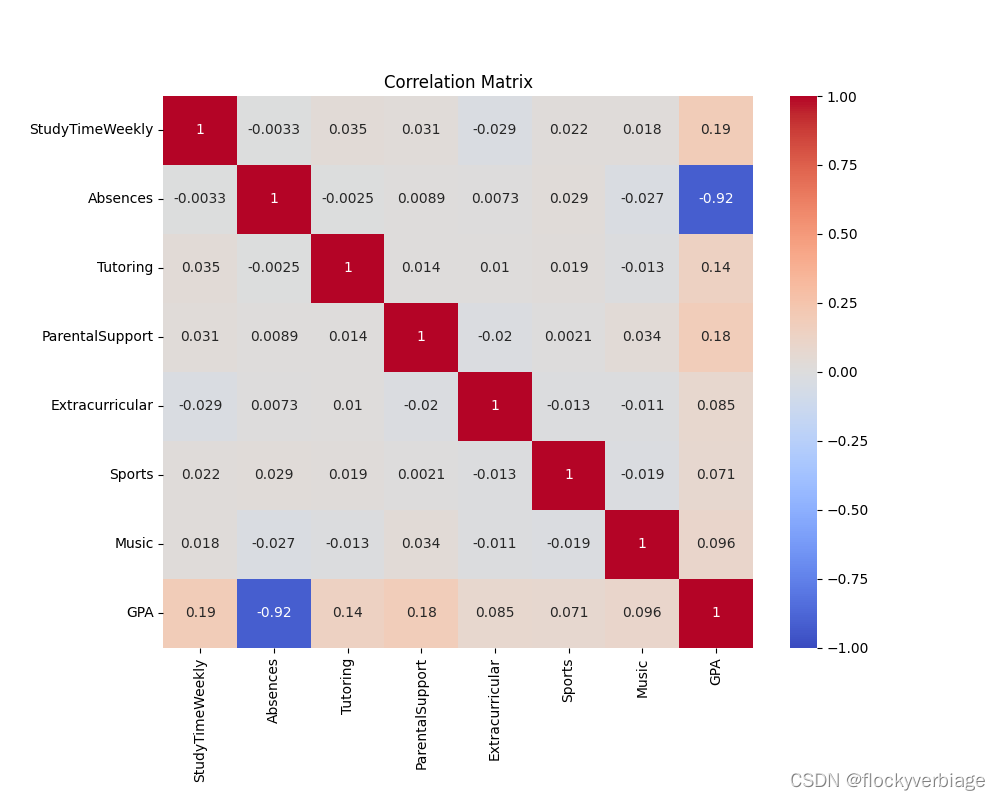
条件数Condition Number: 70.08037681208553
对数据标准化后计算条件数:
# 标准化数据
X_train_standardized = (X_train - X_train.mean()) / X_train.std()
X_train_standardized['const'].fillna(1, inplace=True)
print(X_train_standardized)
# 重新计算条件数
condition_number_standardized = np.linalg.cond(X_train_standardized)
print("Condition Number (Standardized):", condition_number_standardized)条件数(标准化):Condition Number (Standardized): 1.0726682104201564
这样验证了多重共线性假设,同时各变量系数都是显著的。预测集均方误差和决定系数基本没变。
对标准化后的变量重新建立模型
在尝试取对数后模型拟合失败后,最终决定以标准化后的自变量为新变量拟合方程。同时剔除了相关性较低的变量,剩下每周学习时间、缺席次数和父母支持级别三个自变量。
完整代码如下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
#数据处理与预览
df = pd.read_csv('Student_performance_data _.csv')
df = df.drop(columns=['StudentID','GradeClass'])
df.head() #查看前五行数据
# 检查缺失值
#print(df.isnull().sum())
#print(df.shape) #数据维度
#print(df.isnull().sum()) #统计数据空值
#df.info() #每列的数据类型非空值的数量和占用的内存
#df.describe() #数值列的描述性统计信息
# 假设 X 包含所有特征列,y 是目标变量列
X = df[['StudyTimeWeekly','Absences','ParentalSupport']]
y = df['GPA']
# 标准化数据
X = (X - X.mean()) / X.std()
print(X)
# 拆分数据集为训练集和测试集,test_size 指定测试集的比例
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将 X_train 和 y_train 合并成一个数据框
train_df = pd.concat([X_train, y_train], axis=1)
# 计算相关系数矩阵
correlation_matrix_train = train_df.corr()
# 可视化相关性矩阵
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix_train, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Correlation Matrix')
plt.show()
# 向 X_train 添加常数项
X_train = sm.add_constant(X_train)
print(X_train)
# 拟合普通最小二乘回归模型
model = sm.OLS(y_train, X_train)
results = model.fit()
# 输出系数的显著性检验结果
print(results.summary())
# 在测试集上进行预测
X_test = sm.add_constant(X_test) # 添加常数项到测试集
y_pred = results.predict(X_test)
# 评估预测效果
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
# 计算VIF
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X_train, i) for i in range(X_train.shape[1])]
vif["features"] = X_train.columns
print(vif)
# 绘制预测值与真实值的散点图
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, color='blue', alpha=0.5)
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linestyle='--')
plt.title('Actual vs Predicted')
plt.xlabel('Actual GPA')
plt.ylabel('Predicted GPA')
plt.grid(True)
plt.show()
输出结果:
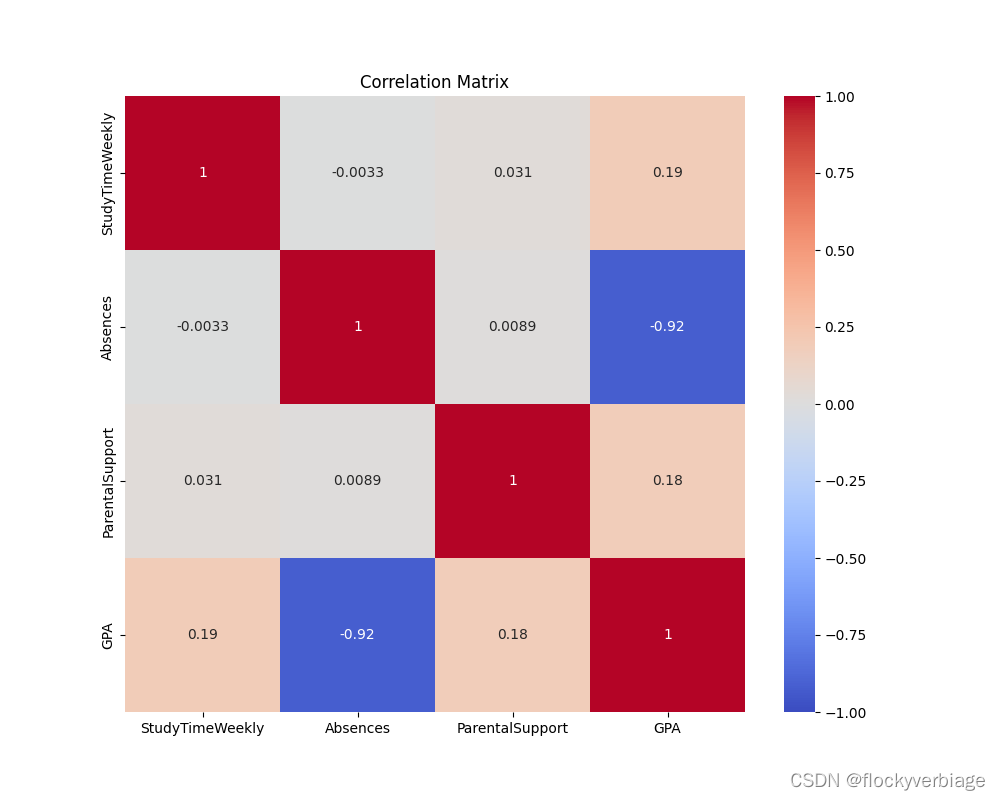
OLS Regression Results
==============================================================================
Dep. Variable: GPA R-squared: 0.914
Model: OLS Adj. R-squared: 0.914
Method: Least Squares F-statistic: 6782.
Date: Sun, 16 Jun 2024 Prob (F-statistic): 0.00
Time: 11:42:52 Log-Likelihood: -198.07
No. Observations: 1913 AIC: 404.1
Df Residuals: 1909 BIC: 426.4
Df Model: 3
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
const 1.9067 0.006 310.367 0.000 1.895 1.919
StudyTimeWeekly 0.1688 0.006 27.702 0.000 0.157 0.181
Absences -0.8414 0.006 -137.228 0.000 -0.853 -0.829
ParentalSupport 0.1676 0.006 27.159 0.000 0.156 0.180
==============================================================================
Omnibus: 8.563 Durbin-Watson: 2.043
Prob(Omnibus): 0.014 Jarque-Bera (JB): 7.808
Skew: 0.110 Prob(JB): 0.0202
Kurtosis: 2.777 Cond. No. 1.04
==============================================================================
尽管决定系数降低为0.914,但是全模型检验Prob(Omnibus):0.014更加显著,各变量系数检验显著,VIF方差膨胀因子都在1附近,条件值也为1,表明无多重共线性。
杠杆值与cook距离
图形绘制
# 计算杠杆值
leverage = results.get_influence().hat_matrix_diag
# 计算Cook's 距离(强影响点度量)
cook_distance = results.get_influence().cooks_distance[0]
# 绘制杠杆值 vs. 残差平方的图
plot_leverage_resid2(results)
plt.title('Leverage vs. Squared Residuals')
plt.xlabel('Leverage')
plt.ylabel('Standardized Residuals Squared')
plt.show()
# 绘制强影响点图
influence_plot(results, criterion="cooks", size=15)
plt.title('Influence Plot (Cook\'s distance)')
plt.xlabel('Leverage')
plt.ylabel('Cook\'s Distance')
plt.show()输出并剔除强影响点和高杠杆值的点,重新拟合,输出预测效果
# 找出强影响点和高杠杆值的观测点索引
outliers = (leverage > leverage_threshold) | (cook_distance > cook_threshold)
outlier_indices = np.where(outliers)[0]
# 输出具有强影响点和高杠杆值的观测点
print("强影响点和高杠杆值的观测点索引:", outlier_indices)
# 剔除强影响点和高杠杆值的观测点
cleaned_y_train = y_train.drop(y_train.index[outlier_indices])
cleaned_X_train = X_train.drop(X_train.index[outlier_indices])
# 向 cleaned_X_train 添加常数项
X_train = sm.add_constant(cleaned_X_train)
print(X_train)
# 拟合普通最小二乘回归模型
model = sm.OLS(cleaned_y_train, cleaned_X_train)
results = model.fit()
# 输出系数的显著性检验结果
print(results.summary())
# 在测试集上进行预测
X_test = sm.add_constant(X_test) # 添加常数项到测试集
y_pred = results.predict(X_test)
# 评估预测效果
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
强影响点和高杠杆值的观测点索引:
[ 0 7 27 35 41 83 133 141 166 205 213 236 243 253
270 287 288 356 370 405 413 419 433 478 500 556 695 696
701 719 722 750 760 766 770 771 795 798 818 821 853 855
875 878 899 969 990 1007 1011 1047 1125 1146 1194 1216 1255 1297
1300 1323 1331 1345 1351 1367 1373 1376 1421 1494 1534 1535 1558 1560
1569 1599 1682 1687 1706 1710 1743 1759 1798 1802 1814 1845 1889 1891
1892 1896]
OLS Regression Results
==============================================================================
Dep. Variable: GPA R-squared: 0.927
Model: OLS Adj. R-squared: 0.927
Method: Least Squares F-statistic: 7766.
Date: Sun, 16 Jun 2024 Prob (F-statistic): 0.00
Time: 13:36:13 Log-Likelihood: -14.194
No. Observations: 1827 AIC: 36.39
Df Residuals: 1823 BIC: 58.43
Df Model: 3
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
const 1.9016 0.006 332.807 0.000 1.890 1.913
StudyTimeWeekly 0.1697 0.006 29.568 0.000 0.158 0.181
Absences -0.8452 0.006 -146.889 0.000 -0.857 -0.834
ParentalSupport 0.1682 0.006 28.705 0.000 0.157 0.180
==============================================================================
Omnibus: 83.930 Durbin-Watson: 2.060
Prob(Omnibus): 0.000 Jarque-Bera (JB): 34.759
Skew: -0.001 Prob(JB): 2.83e-08
Kurtosis: 2.324 Cond. No. 1.06
==============================================================================
改善效果:
Prob(Omnibus)< 0.001,R-squared: 0.927
预测集:
Mean Squared Error (MSE): 0.0674975557059648
R-squared (R2): 0.9183759903036064
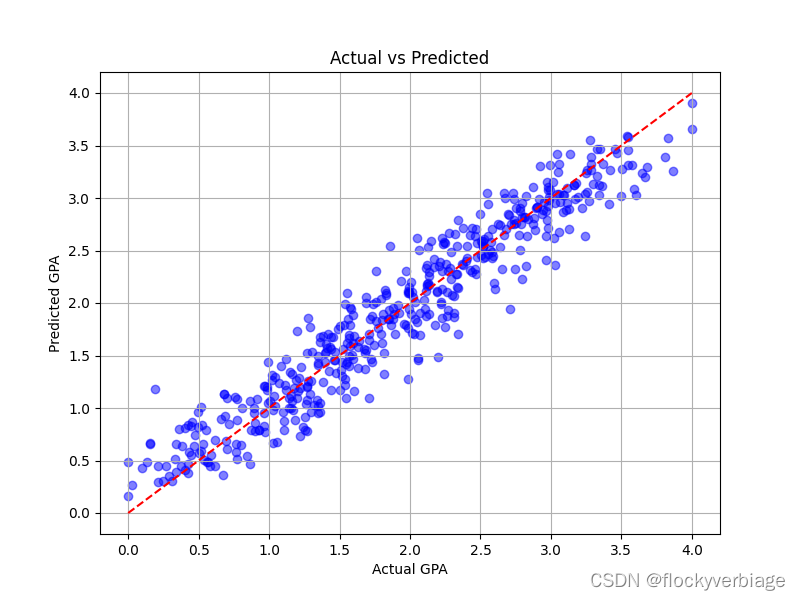
结论
数据集本身是很规整的,因此通过标准化数据、剔除相关性低的变量、剔除强影响点和高杠杆值的观测点,使得整体数据的线性回归有初步成效。但想要精准预测还需要进一步努力和尝试。
接下来以考虑对数据进行分类,比如说按照不同的变量划分为不同集合,减少样本数量,做分别的回归;又或者选择更加合适的模型。















 9985
9985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









