






 该论文提出了一种有效的方法,从单视角2D图像生成3D表示。通过结合显式和隐式3D表达,使用tri-plane表达和双鉴别训练策略,保证神经渲染的一致性。研究中还引入了姿态相关的条件,解耦与姿态相关的特性,如面部表情。此外,通过使用2DCNN特征生成器,模型能够在不同3D场景中泛化,并在多视角神经体渲染中获益。实验显示,这种方法优于传统的密集特征体积表达,并在新视角合成任务中表现出色。
该论文提出了一种有效的方法,从单视角2D图像生成3D表示。通过结合显式和隐式3D表达,使用tri-plane表达和双鉴别训练策略,保证神经渲染的一致性。研究中还引入了姿态相关的条件,解耦与姿态相关的特性,如面部表情。此外,通过使用2DCNN特征生成器,模型能够在不同3D场景中泛化,并在多视角神经体渲染中获益。实验显示,这种方法优于传统的密集特征体积表达,并在新视角合成任务中表现出色。
文章目录
概述
论文名称: Efficient Geometry-aware 3D Generative Adversarial Networks
Project page: https://github.com/NVlabs/eg3d
任务: 从一堆单视角的2D图像中生成有效的三维表达。
途径:
- 混合的显式与隐式三维表达;
- dual-discremination的训练策略,以保持神经渲染之间的一致性。
- 为生成器引入 pose-based的条件,能够解耦与pose相关的特性(比如面部表达)
其他优势:
从神经渲染过程中解耦特征生成,这使得能够直接应用SOTA的2D CNN特征生成器。可以实现在各种3D场景内的泛化,同时也可以在3D多视角一致的神经体渲染过程中受益。
【为什么2D CNN特征生成器可以实现泛化,和从多视角一致的渲染过程中收益?】
Tri-Plane 表达
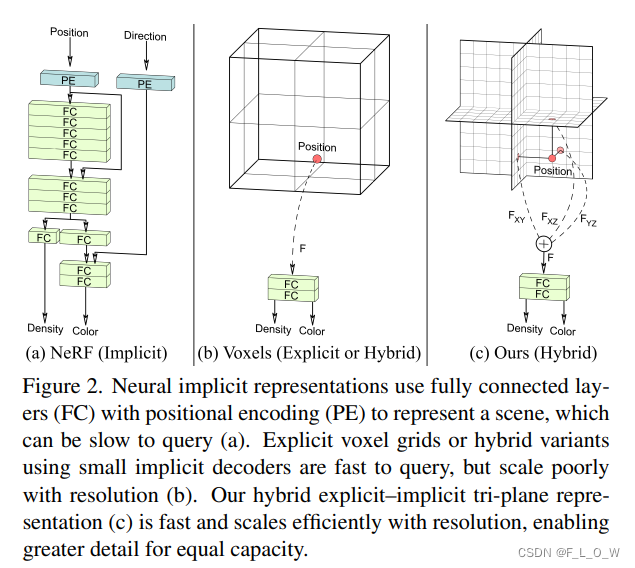
期望一种表达能力强、效率高的3D数据表达。
本节先一个 single-scene over-fitting (SSO)的实验中进行说明,而后再讨论其如何被引入到GAN框架中。
在 "tri-plane"的表达中,首先将显式的特征,归到三个轴正交的特征平面上,每一个特征平面的size都是
N
∗
N
∗
C
N * N * C
N∗N∗C,显然,
N
N
N是空间分辨率,
C
C
C是特征通道数。
进而,可以通过将任何一个三维点
x
∈
R
3
x \in \mathbb{R}^3
x∈R3投影到三个特征平面上,获取其对应的特征向量
(
F
x
y
,
F
x
z
,
F
y
z
)
(F_{xy}, F_{xz}, F_{yz} )
(Fxy,Fxz,Fyz)(可通过双线性插值的方式),而后,再将获取的三个特征向量进行累加,即得到所谓的 “aggreated 3D Features”
F
\mathbf{F}
F。
再引入一个小型的MLP,将这个
F
\mathbf{F}
F输出为颜色与密度。
这种 tri-plane的表达,最大的优势在于效率(decoder变得比较小;将大部分的表达能力都转移给了显式的特征)。
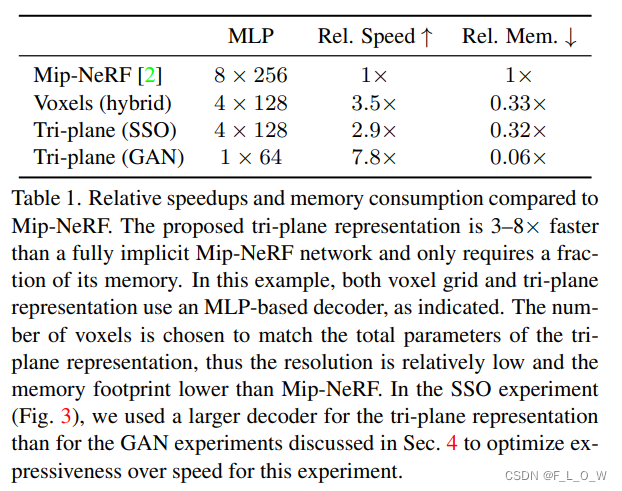
验证 tri-plane 表达
为了验证这种表达的能力,使用一种通用的新视角合成的实验设置。即,直接去优化 planes的特征以及decoder的权重,以fit 360°的视角(Tanks & Temples 数据集)。
实验设定:
- 特征平面: N = 512 N = 512 N=512, C = 48 C = 48 C=48
- decoder: 四层MLP,128个隐藏单元,一个傅里叶特征编码。
对比对象:
一个dense feature volume(具有相同的capacity),具体使用了一个SOTA的全隐式表达网络。
实验效果:

3D GAN 框架
训练一个3D GAN,但是不需要显式的3D结构或者多视图监督。
对每一张训练图片都关联上相机内外参(通过现成的pose-detectors)。
整体网络结构为: 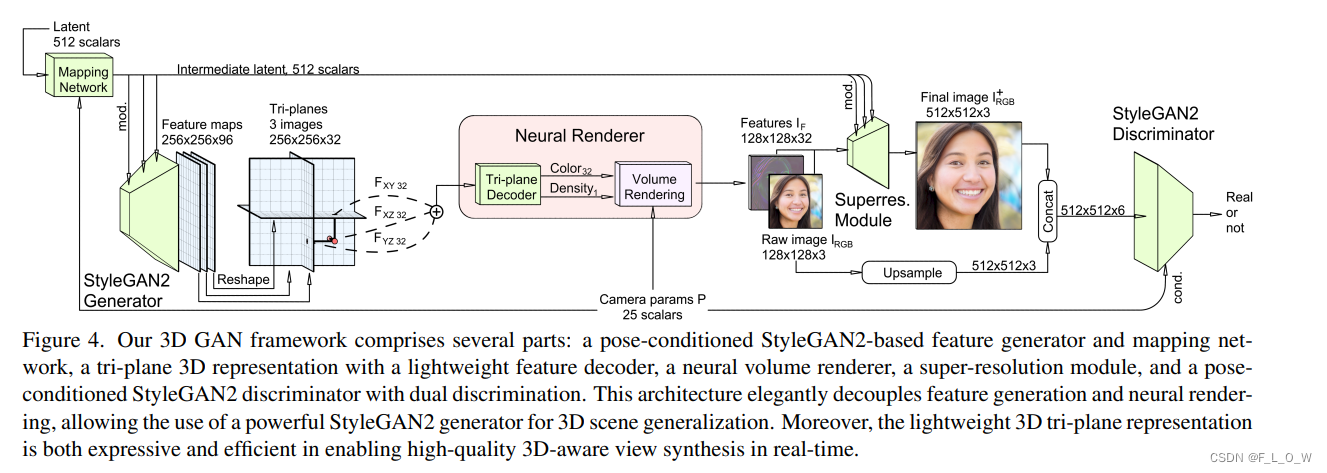
与SSO中的设定不同,planes中的feature并不是由多张输入图直接进行优化的,而是会根据GAN的设定进行了一定程度的修改 —— 基于StyleGAN2的backbone,生成了tri-plane的特征(channels = 32),且并不是生成一个RGB图,而是生成一个32通道的特征图(给定相机pose)。而后,接入一个“super-resolution”模块,以进行上采样与refine。输出的结果将被一个稍做改动的StyleGN2 discriminator进行判别。
整个网络通过一种端到端的方式进行训练(随机初始化),使用 non-saturating GAN 损失函数,以及 R1 regularization (借鉴了StyleGAN2的训练机制)。
为了加速训练,使用了两阶段的训练策略,第一阶段使用一个较低的分辨率:一个reduced ( 6 4 2 64^2 642)的神经渲染分辨率,第二阶段进行短暂微调,并以 full( 12 8 2 128^2 1282) 神经渲染分辨率进行训练。
CNN生成器backbone以及渲染
特征backbone使用的是StyleGAN2 CNN生成器。
首先,随机的潜在编码和相机参数会经过一个映射网络,生成一个中间的潜在编码。然后,这个中间的潜在编码会调制一个独立的合成网络的卷积核。
修改了StyleGAN2的CNN backbone,使得其生成 256 ∗ 256 ∗ 96 256 * 256 * 96 256∗256∗96的特征图,而不是三通道的RGB图片。这些特征图进一步地reshape成三个 32通道的planes。StyleGAN的表达给网络提供了一个well-behaved的latent space,这个latent space能够较好地达成 style-mixing以及latent-space interpolation.
decoder只使用一个隐藏层,隐藏层有64个units,以及softplus 激活函数。这个MLP没有使用位置编码,坐标输入,或者视角输入。输出为一个标量体密度 σ \sigma σ以及一个32通道的特征,名为 C o l o r Color Color。这两个输出进一步地被喂入 Volume Rendering模块(借鉴了参考文献[45]),以生成2D的feature map。
在本文的大部分实验中,渲染的特征图 I F I_{F} IF为32通道,分辨率为 12 8 2 128^2 1282,每条ray上采样 96 96 96个sample(“…with 96 total depth samples per ray.”)。
超分
尽管tri-plane的表达已经很高效,但是处理高分辨率图片仍然比较困难。
因此,引入了一个超分模块。
超分模块由两个StyleGAN2调制的卷积层块组成。
为了减少纹理粘连的问题,作者禁用了每个像素的噪声输入,并重复使用了模型的映射网络来调制这些层。
Dual discrimination
在标准的2D GAN训练过程中,渲染结果最终由一个2D卷积分辨器进行分辨。
我们主要基于StyleGAN2做了两个修改。
首先,为了避免生成图像的多视角不一致,将一张渲染的特征图
I
F
I_{F}
IF的前三个通道设计成低分辨率的RGB图
I
R
G
B
I_{RGB}
IRGB。
直觉上来看,dual discremination而后会去尽可能地确保 I R G B I_{RGB} IRGB与超分图像 I R G B + I_{RGB}^{+} IRGB+高度相似。实现方式是: 将 I R G B I_{RGB} IRGB上采样到和 I R G B + I_{RGB}^{+} IRGB+同分辨率,并将两张图像concat,得到一个六通道的图像。这个六通道的图像将会被送到判别器去。
Dual discrimination同时也鼓励了超分后的图像与神经渲染得到的图像尽可能地一致:

GAN使用条件策略来让鉴别器了解生成图像的相机姿态。具体来说,我们将**渲染相机的内部和外部矩阵(统称为P)**作为条件标签传递给鉴别器,这是从StyleGAN2-ADA中采用的条件策略。我们发现,这种条件引入了额外的信息,可以指导生成器学习正确的3D先验知识。
Modeling pose-correlated attributes
真实世界数据集(如FFHQ)中存在偏差问题,这些偏差会将相机姿态与其他属性(如面部表情)相关联,如果不做特别的处理则会导致视角不一致的结果。例如,相机角度与人脸的表情是相关联的(请参见补充材料)。
虽然完完全全地对模拟数据集中固有的属性进行建模,对于重新生成最佳图像质量非常重要,但这些不需要的属性(比如面部表情)在多视角一致的合成任务推理时,还是需要被解耦。
相关工作已经成功地实现了视角一致性[4, 58, 59]或建模相机姿态与外观一致性[47, 49],但难以同时实现两者。
为此,网络提供了backbone映射网络,不仅仅将latent code 向量 v v v作为输入,同时也将相机参数作为输入,这主要参考了条件生成策略[26]。
在训练过程中,pose conditioning允许生成器对数据中pose-independent的隐含偏差进行建模。
为了避免场景在推理的时候随着相机pose移动而移动,文章在移动相机轨迹进行渲染的时候,将生成器固定在某一个pose位置。
什么意思?
但是,如果总是这样处理的话,会导致GAN总是产生一些朝向相机的图片。为了尽可能避免这个情况,文章随机地交换 P P P中的条件pose和另外一个随机pose。
条件pose是怎么确定的,随机pose又是怎么确定的,50%是一个超参数吗?
实验
【todo】
数据
- the task of unconditioned 3D-aware generation
参考文献
- two-pass importance sampling 体渲染模块[45]:
- 条件生成策略[26]



















 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











