






 PanoHead是一个创新方法,能用单视图‘野生’图像生成360度3D人像。它解决了GANs在非受控环境下的局限,提出了两阶段自适应图像对齐来处理相机参数不确定性,使用三网格神经体积表示解决镜像脸问题,并通过前景感知三鉴别器将人像从背景中解耦。实验表明,这种方法在生成质量和多视角一致性方面有显著提升。
PanoHead是一个创新方法,能用单视图‘野生’图像生成360度3D人像。它解决了GANs在非受控环境下的局限,提出了两阶段自适应图像对齐来处理相机参数不确定性,使用三网格神经体积表示解决镜像脸问题,并通过前景感知三鉴别器将人像从背景中解耦。实验表明,这种方法在生成质量和多视角一致性方面有显著提升。

总结:
- 任务:3D human head synthesis
- 现有问题:GANs无法在「in-the-wild」「single-view」的图片情况下,生成360度人像
- 解决方案:1)提出了two-stage self-adaptive image alignment,用于robust 3D GAN training;2)提出了tri-grid neural volume representation,用于解决头后镜像脸的问题;3)提出了foreground-aware tri-discriminator,用于将人像从背景中解耦出来。
目录
Foreground-Aware Tri-Discrimination
Feature Disentanglement in Tri-Grid
Self-Adaptive Camera Alignment

引言
为了生成不同形状和外观的3D heads:
- 传统方法(显示方法)使用参数化textured mesh model,可以单张出Avatar,然而渲染的图片细节较差,效果不好;
- 隐式方法效果不错,但这些方法通常需要多视角图片或3D scan supervision,同时由于采集自受控环境,生成Avatar的外观分布有限;
- 3D GAN(EG3D)可以使用「in-the-wild」「single-view」图片生成人像,然而这些方法通常只能产生near-frontal views。
- 因此,本文提出PanoHead,是第一个可以使用「in-the-wild」「single-view」图片,生成360度3D人像的方法;
拓展EG3D用于生成360度3D人像,存在下列挑战:
- 3D GANs很难将前景和背景分开,背景通常被表示为墙,阻碍了大角度的渲染。针对这个问题,本文提出了foreground-aware tri-discriminator,通过使用2D image segmentation的先验知识,将前景从3D space中分离出来;
- 对360度相机位姿来说,tri-plane引入了很强的映射歧义,导致在头后产生镜像脸(mirrored face)。针对这个问题,本文提出了tri-grid volume representation将前景特征解耦出来;
- 对3D GANs来说,获得「in-the-wild」头后图片的相机外参是很困难的。同时,由于对头后关键点检测效果较差,前脸和头后图像的image alignment也存在差异。这种alignment gap会导致显示噪声和头部形状较差。针对这个问题,本文提出了two-stage alignment scheme,使得image alignment保持视觉一致。同时,本文还提出一种相机自适应模型(camera self-adaptation module),动态调整渲染相机的位置,以缓解alignment gap的问题。
综上,本文贡献如下:
- 第一个可以使用「in-the-wild」「single-view」图片,生成360度3D人像的方法;
- 提出一种tri-grid formulation,用于解决头后的镜像脸问题;
- 提出一种tri-dricriminator:将3D前景头像从2D人造背景中解耦出来;
- 提出一种two-stage image alignment scheme,缓解不正确的camera poses和alignment gap,改善3D GAN在「in-the-wild」图片上的训练
方法
三个问题阻碍了EG3D渲染出360度人像:1)前景和背景无法解耦阻碍了大pose的渲染;2)tri-plane存在归纳偏置,导致在头后渲染出人脸;3)相机外参不准确和alignment gap问题。针对这三个问题,本文分别提出了解决方案。
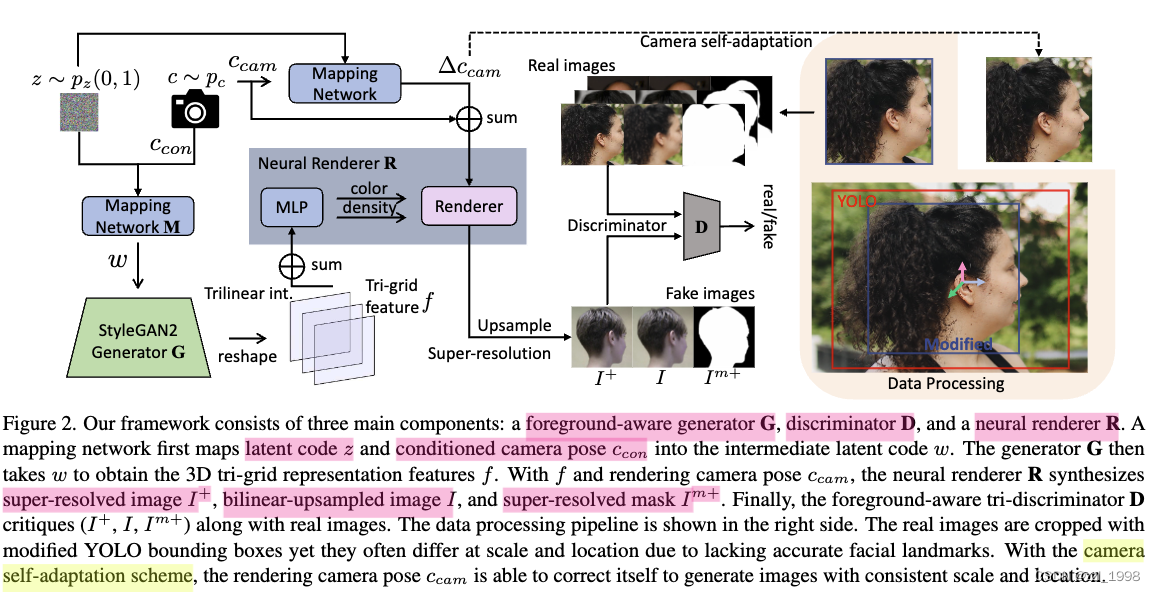
Foreground-Aware Tri-Discrimination
由于无法将前景从背景中解耦出来,会导致生成2.5D人像(下图a)。增加侧脸或头后图片可以建立完整的几何结构,提供合理的头后形状。然而,这并不能解决问题,因为tri-plane本身就不是设计用来从背景中分离前景;
因此,本文提出一中foreground-aware tri-discriminator。具体来说,tri-discriminator的输入有7个通道,包含bilinearly-upsampled RGB图片,super-resolved RGB图片和single-channel upsampled foreground mask。

Feature Disentanglement in Tri-Grid
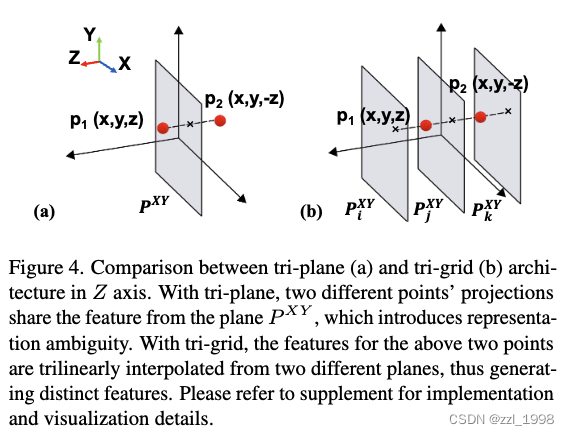
现有方法Tri-plane,使用三个互相垂直的平面,任意一个体素神经场密度和颜色是通过投影到三个平面的特征和,经过一个MLP得到;但是Tri-plane会导致头后出现人脸,这是由于tri-plane投影的归纳偏置导致的。例如:对前脸和头后的两个点,他们会投影到XY平面中的同一个点(如下图a)。
这是因为,当缺少头后监督,或头后结构较难学习时,tri-planes倾向于借助前脸的特征,这导致了镜像脸问题(mirroring-face artifacts),如下图:
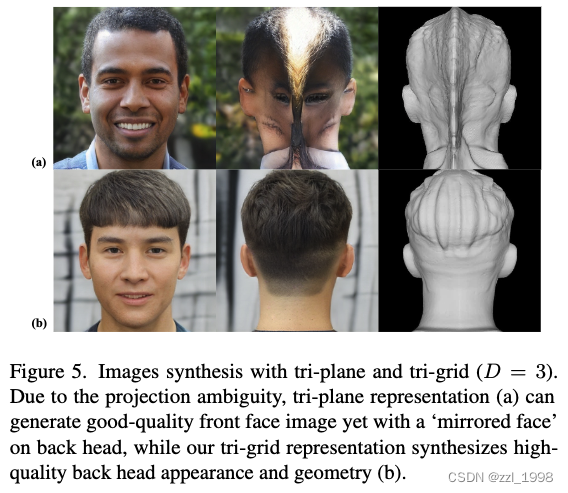
为了解决该问题,本文为tri-plane增加了额外的深度维度,并称为tri-grid。原有的tri-plane是H x W x C,增加后是D x H x W x C,其中D表示深度。具体来说,会增加D个平面,对具有相同投影坐标的脸前和头后两个点,在tri-grid中由相邻深度的平面插值得到。本文使用D = 3。
Self-Adaptive Camera Alignment
alignment gap问题
- 图像预处理通常基于人脸关键点。但对侧脸和头背,现有检测方法无法准确估计人脸关键点。
- 因此,本文提出一种两阶段处理。在第一阶段,对可见关键点,本文仍然使用3DDFA检测关键点,将人脸缩放至相似尺寸,并对齐至人脸中心。对有较大角度变化的点,本文使用WHENet检测头部位姿,并提供粗略估计的相机位姿,并使用YOLO输出以头为中心的bbox。
- 为了保证裁剪后的图片,头的大小和中心保持一致,本文同样也将YOLO和3DDFA应用在前脸图片上。
相机参数不准问题
- 本文提出一中自适应相机对齐机制(a self-adaptive camera alignment scheme)。
- 对每张图片会有一个关联的latent code z,它包含了3D物体的几何和外表信息;
- 由于相机相机位姿c_cam不准,本文考虑以(z, c_cam)作为输入,通过网络预测一个delta_c_cam。
- 在损失中,delta_c_cam通过一个L2正则进行约束,使得模型可以自适应的调整不准确的相机位姿。
实验
数据集和Baseline
- 数据集:FFHQ-F,是FFHQ、K-hairstyle dataset和in-hourse large-pose head image collection的集合。其中,FFHQ包含70K人脸图片,大部分在0-60度;K-hairstyle dataset包含4K头后图片;in-hourse large-pose head image collection包含15K大姿态图片。
- Baseline:GRAF、EG3D、StyleSDF、GIRAF-FEHD。
Qualitative Comparisons
360度图片生成

Geometry Generation
基于Marching Cubes Algorithms,提取3D几何信息。

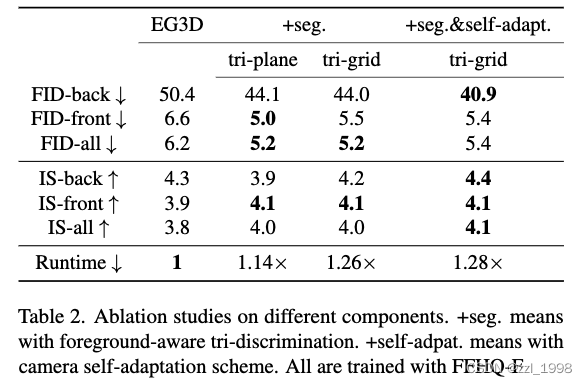
Quantitative Results
评价指标
- Frechet Inception Distance (FID): quantify the visual quality, fidelity, and diversity of the generated images;
- Identity similarity score (ID): 计算从不同相机位姿渲染人脸的平均Adaface cosins similarity score,用于量化the multi-view consistency;
- Mean Square Error (MSE):计算生成分割结果和通过DeepLabV3 ResNet101 network检测的结果;
- Inception Score (IS):评估图片质量;

Single-view GAN Inversion
- 通过优化算法(pixel-wise L2损失,image-level LPIPS loss),找到目标图片对应的latent code z。
- 为了进一步改善重建质量,使用pivotal tuning inversion (PTI),基于固定的latent code z,修改生成器参数。


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









