







简介
仅使用单视图 2D 照片集合无监督生成高质量的多视图一致图像和 3D 形状一直是一项长期存在的挑战。现有的3D GAN要么是计算密集型的,要么是进行不3D一致的近似;前者限制了生成图像的质量和分辨率,后者会对多视图一致性和形状质量产生不利影响。在这项工作中,提高了3D GAN的计算效率和图像质量,而不会过度依赖这些近似值。为此,引入了一种富有表现力的混合显式-隐式网络架构,该架构与其他设计选择一起,不仅可以实时合成高分辨率多视图一致的图像,还可以生成高质量的3D几何体。通过分离特征生成和神经渲染,框架能够利用最先进的2D CNN生成器,如StyleGAN2,并继承它们的效率和表现力。
主页:https://nvlabs.github.io/eg3d/

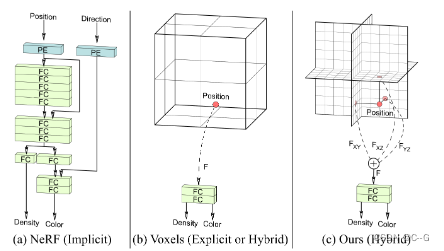
神经隐式表示使用全连接层(FC)和位置编码(PE)来表示场景,这可能会很慢(a)。显式体素网格或混合变体使用小型隐式解码器,查询速度很快,但分辨率较低(b)。我们的混合显式-隐式三平面表示©速度快,分辨率高,可以有效缩放,在同等容量下实现更详细的内容。
论文贡献点

网络架构
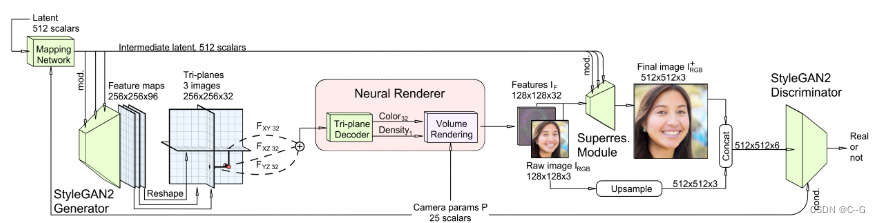
实现流程
CNN generator backbone and rendering
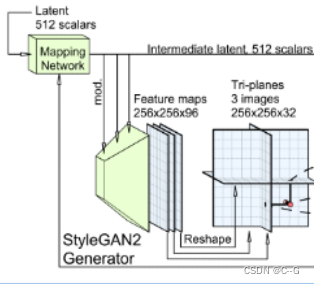
这里对StyleGAN2 Generator的输出进行修改,输出的不再是RGB图像,而是 256 x 256 x 96 的特征图,然后再划分为三个32通道的平面,组合为一个轻量级特征解码器的三平面3D表示
StyleGAN2是一个易于理解的高效架构,可以实现2D图像合成的最先进结果,其次,模型可以继承StyleGAN的许多理想属性:一个表现良好的潜在空间,它支持样式混合和潜在空间插值
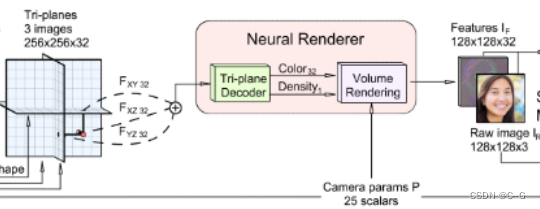
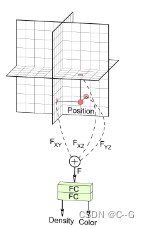
紧接着从三平面中采样特征,通过总和进行聚合,并使用轻量级解码器处理聚合特征,上图中,解码器是一个多层感知器,有一个64个单元的单个隐藏层和软加激活函数。MLP不使用位置编码、坐标输入或视图方向输入。该混合表示可以查询连续坐标,输出标量密度σ和32通道特征,然后通过神经体渲染器处理,将3D特征体投影到2D特征图像中
体渲染器采用双通道重要采样实现,产生特征图像,而不是RGB图像,因为特征图像包含更多的信息,可以有效地用于下面描述的图像空间细化。最后产生128 x 128 x 32的特征图IF,并且每条射线有96个总深度样本。
Super resolution
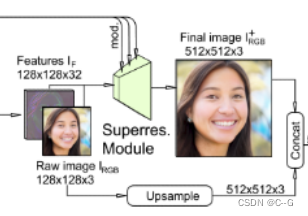
虽然三平面表示比之前的方法在计算效率上有了显著提高,但在保持交互帧率的同时,它在本地训练或呈现高分辨率时仍然太慢。因此,在中等分辨率(如128x128)下进行体积渲染,并依靠图像空间卷积对神经渲染进行上采样,使其最终图像大小为256x256或512x512
超分辨率模块由两块stylegan2调制的卷积层组成,对32通道特征图像IF进行上采样和细化,最终得到RGB图像I+ RGB。我们禁用逐像素噪声输入来减少纹理粘着,并重用骨干的映射网络来调制这些层。
Dual discrimination
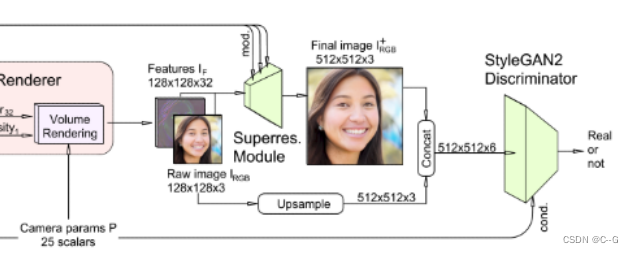
判别器使用Dual discrimination避免多视图不一致问题,将Volume Rendering处理后的特征图的前三个特征通道理解为低分辨率的RGB图像——IRGB,dual discrimination通过双线性上采样IRGB到与I+ RGB相同的分辨率,并将结果拼接形成一个六通道图像来实现,IRGB和超分辨率图像I+ RGB之间的一致性。输入鉴别器的真实图像也通过将它们与自身适当模糊的副本进行拼接作同样处理。
双重判别鼓励最终输出匹配真实图像的分布,鼓励神经渲染匹配下采样的真实图像的分布,鼓励超分辨率图像与神经渲染保持一致,允许我们利用有效的图像空间超分辨率层,而不引入视图不一致的工件
遵循StyleGAN2-ADA的条件策略,将呈现摄像机intrinsic和extrinsics矩阵(集合P)作为条件标签传递给鉴别器,使鉴别器意识到相机的姿态,由此生成的图像被渲染。这种条件反射引入了额外的信息,指导生成器学习正确的3D先验
Modeling pose-correlated attributes
引入生成器位姿条件反射作为一种方法来建模和解耦在训练图像中观察到的位姿和其他属性之间的相关性。为此,遵循条件生成策略,为骨干映射网络提供一个潜在的代码向量z,并将摄像机参数P作为输入。通过给出渲染相机位置的主干知识,我们允许目标视图影响场景合成。
在训练过程中,姿态条件反射允许生成器建模隐式到数据集的姿态依赖偏差,允许模型忠实地再现数据集中的图像分布。为了防止场景在推断过程中随着相机姿势的改变而改变,在从移动的相机轨迹进行渲染时将生成器设置为固定的相机姿势。我们注意到,总是用渲染相机姿势调节生成器会导致退化的解决方案,即GAN产生的2D广告牌朝着相机的角度(见补充)。为了避免这种情况,在训练过程中以50%的概率将P中的条件反射姿势与另一个随机姿势随机交换

















 6456
6456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









