







本系列文章会优先发布于微信公众号和知乎专栏,欢迎大家关注
微信公众号:小飞怪兽屋
目录
前言
如果有人问我刚开始接触PyTorch该从何处学起时,我的回答一定不会是举世瞩目,让人惊叹不已的神经网络(NN, Neural Network),也不会是不明觉厉,精巧设计的梯度自动求导系统(Autograd),反而恰恰是平淡无奇,却无处不在的张量(Tensor)。正如所有人学习编程所做的第一件事情就是在控制台输出“Hello World”一样,Tensor就是PyTorch的“Hello World” ,每一位初学者在接触PyTorch时所做的第一件事就是用torch.tensor函数创建一个属于自己的Tensor。
import torch
torch.tensor([1,2,3])当我们写下上面这段代码的时候,我们就已经开始走进PyTorch的宏观世界,我们利用PyTorch提供的函数创建了一个Tensor对象。但是,不知你们是否曾好奇过Tensor是如何创建的,是否曾想过Tesnor是如何存储的,是否曾探究过Tensor是如何设计的 ?今天,就让我们深入研究上面这段代码,一起走入Tensor的微观世界。
Tensor是什么?
在深入研究之前让我们先来简单回顾下Tensor是什么?从数学角度上来说,Tensor本质上是一个多维向量。在数学里,一个数我们称之为标量,一维数据我们称之为向量,二维数据我们称之为矩阵,到三维及更高维度的时候,我们并没有为每一个维度数据都提供一个专有名称,我们将这些包含维度信息的数据统称为张量(Tensor)。
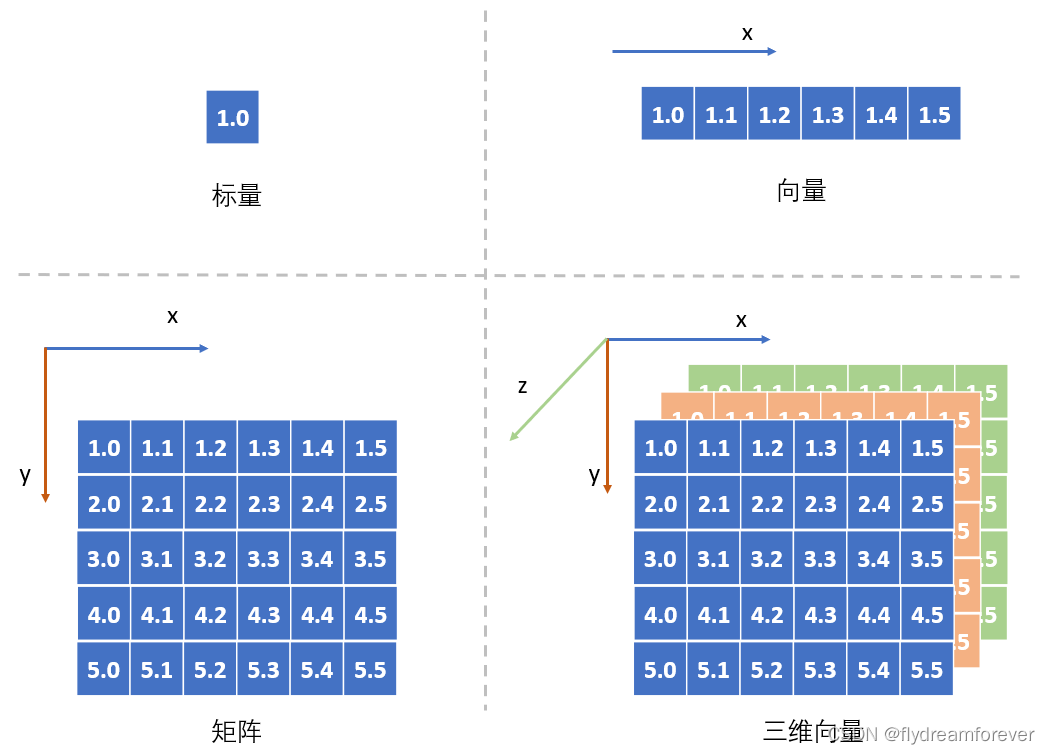
从图上可以看出,标量就是0维的Tensor,向量是1维的Tesnor,矩阵是二维的Tensor。在介绍Tensor的时候我们引入一个叫做维度的抽象概念,维度本质上是衡量事物的一种方式。比如时间就是一种维度,假如我们在网上卖东西,每天晚上都要汇总今天的销售额,我们就可以得到销售额相对于时间的关系,这里销售额就是基于时间的一维Tensor。当我们觉得销售额不仅仅和时间有关系,可能还和当天的客户访问量有关系,我们就又引入了一种维度,可以得到销售额与(时间,访问量)之间的关系,我们就建立一个二维的Tensor。Tensor就是用来表示这种多维数据的一种抽象概念,在不同的场景下具有不同的物理含义。在空间上,它是表示长宽高的三维tensor;在RGB颜色上,它是表示红绿蓝的三维Tensor;在语音通话中,它是表示时间与语音信息的二维Tensor。
Tensor如何存储?
当我们了解了Tensor的概念后,那该如何在计算机中存储包含多维信息的Tensor呢?当程序在计算机中运行时,我们需要将程序代码,程序运行需要的数据以及程序运行过程中生成的数据加载到内存中,所以我们可以得出一个结论,存储Tensor的物理媒介是内存(GPU上是显存),内存是一块可供寻址的存储单元。在我们设计Tensor的存储方案时,我们需要先弄清Tensor的特性:
- Tensor需要支持随机访问。这很重要,因为在Python中Tensor是支持索引(index)和切片(slice)操作的,支持随机访问可以让我们快速的找到需要的数据,提高我们数据访问效率
- Tensor的大小是固定的。当我们创建了一个Tensor的时候,它的大小就已经确定了,我们可以修改其上的任意元素,就是不能增加元素来修改它的大小。如果要修改其大小,我们必须根据其大小创建一个新的Tensor,将旧的Tensor上的数据复制过去
说到这里大家是不是觉得很熟悉?没错,就是在数据结构课上学到的第一个数据结构,数组。当我们创建一个数组的时候,我们会向内存申请一块指定大小的连续存储空间,而这恰恰就是PyTorch中Strided Tensor的存储方式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









