









本章小结
让我们假设观测服从
D
D
D维空间的某个未知的概率密度分布
p
(
x
)
p(x)
p(x)。把这个
D
D
D维空间选择成欧⼏⾥得空间,考虑包含
x
x
x的某个⼩区域
R
R
R,则这个区域的概率质量为
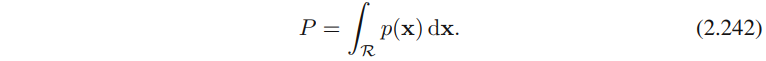
假设收集了服从
p
(
x
)
p(x)
p(x)分布的
N
N
N次观测,很容易得出位于区域
R
R
R内部的数据点总数
K
K
K满足
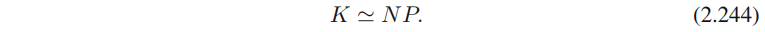
如果假定区域
R
R
R⾜够⼩,使得在这个区域内的概率密度
p
(
x
)
p(x)
p(x)⼤致为常数,那么有

其中
V
V
V是区域
R
R
R的体积。把公式(2.244)和公式(2.245)结合,得到概率密度的估计为
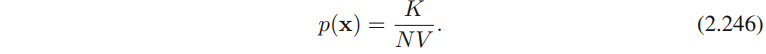
有两种⽅式利⽤(2.246)的结果。可以固定
K
K
K然后从数据中确定
V
V
V 的值,这就是
K
K
K近邻⽅法。还可以固定
V
V
V然后从数据中确定
K
K
K,这就是核⽅法。在极限
N
→
∞
N\rightarrow\infty
N→∞的情况下,如果
V
V
V随着
N
N
N⽽合适地收缩,那么可以证明
K
K
K近邻概率密度估计会收敛到真实的概率密度。同样的,在极限
N
→
∞
N\rightarrow\infty
N→∞的情况下,如果
K
K
K随着
N
N
N增⼤,那么可以证明核⽅法概率密度估计也会收敛到真实的概率密度。
先详细讨论核⽅法。把区域
R
R
R取成以
x
\textbf{x}
x为中⼼的⼩超⽴⽅体,定义下⾯的函数
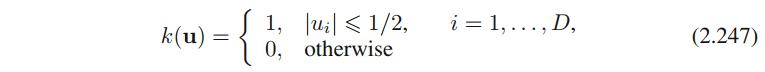
这表⽰⼀个以原点为中⼼的单位⽴⽅体。函数
k
(
u
)
k(u)
k(u)是核函数的⼀个例⼦,在这个问题中也被称为Parzen窗。如果数据点
x
n
x_n
xn位于以
x
x
x为中⼼的边长为
h
h
h的⽴⽅体中,那么量
k
(
x
−
x
n
h
)
k(\frac{x-x_n}{h})
k(hx−xn)的值等于1,否则它的值为0。于是,位于这个⽴⽅体内的数据点的总数为

把这个表达式代⼊公式(2.246),得
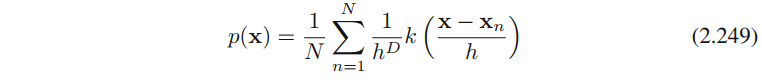
核密度估计(2.249)有⼀个问题,就是⼈为带来的⾮连续性,是由⽴⽅体的边界引起得。如果我们选择⼀个平滑的核函数,就可以得到⼀个更加光滑的模型,⼀个常见的选择是⾼斯核函数,于是可得
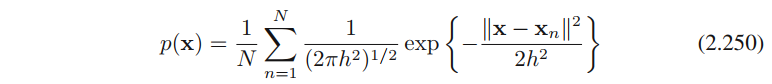
公式2.250中的概率密度模型可以通过这种⽅式获得:令每个数据点
x
\textbf{x}
x都服从⾼斯分布,然后把数据集⾥的每个数据点的贡献相加,之后除以
N
N
N,使得概率密度正确地被归⼀化。在图2.25中,我们把模型(公式2.250)应⽤于之前⽤来说明直⽅图⽅法的数据集上。我们看到,参数
h
h
h对平滑参数起着重要的作⽤。⼩的
h
h
h会造成模型对噪声过于敏感,⽽⼤的
h
h
h会造成过度平滑,因此要进⾏⼀个折中。与之前⼀样,对
h
h
h的优化是⼀个模型复杂度的问题,类似于直⽅图概率密度估计中对于箱⼦宽度的选择,也类似于曲线拟合问题中的多项式阶数。

我们可以任意选择公式(2.249)中的核函数,只要满⾜下⾯的条件

这确保了最终求得的概率分布在处处都是⾮负的,并且积分等于1。公式(2.249)给出的概率密度模型被称为核密度估计,或者Parzen估计。它有⼀个很⼤的优点,即不需要进⾏“训练”阶段的计算,因为“训练”阶段只需要存储训练集即可。然⽽,这也是⼀个巨⼤的缺点,因为估计概率密度的计算代价随着数据集的规模线性增长。
互动话题
- 2.5节曾经提到,与简单的直⽅图⽅法相⽐,核密度方法对于维度的放⼤有着更好的适应性。如何理解?
如果核函数选的是公式2.247,依然没有彻底解决维度灾难,公式2.250的高斯平滑核函数倒是更多的缓解了维度灾难。















 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









