







本文希望达到以下目标:
- 简要介绍Scarpy
- 使用Scarpy抓取豆瓣电影
我们正式讲scrapy框架爬虫,并用豆瓣来试试手,url:http://movie.douban.com/top250
首先先要回答一个问题。问:把网站装进爬虫里,总共分几步?
答案很简单,四步:
- 新建项目 (Project):新建一个新的爬虫项目
- 明确目标(Items):明确你想要抓取的目标
- 制作爬虫(Spider):制作爬虫开始爬取网页
- 存储内容(Pipeline):设计管道存储爬取内容
好的,基本流程既然确定了,那接下来就一步一步的完成就可以了。
1.新建项目(Project)
在空目录下按住Shift键右击,选择“在此处打开命令窗口”,输入一下命令:
<span style="font-size:14px;">scrapy startproject douban</span>
可以看到将会创建一个douban文件夹,目录结构如下:
douban/
scrapy.cfg
douban/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...</span>我们用pycharm打开该项目,具体看一下:
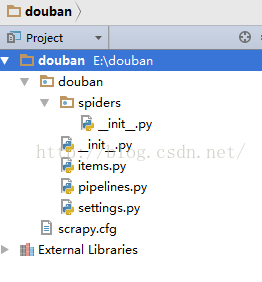
下面来简单介绍一下各个文件的作用:
- scrapy.cfg:项目的配置文件
- douban/:项目的Python模块,将会从这里引用代码
- douban/items.py:项目的items文件
- douban/pipelines.py:项目的pipelines文件
- douban/settings.py:项目的设置文件
- douban/spiders/:存储爬虫的目录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









