






【昨日内容复习】
进行监督学习时,第一个步骤是提取数据集的文本特征和对应的标签。
提取文本特征的具体步骤如下:
STEP1. 构造词袋模型,提取数据集中的文本特征
STEP2. 使用toarray()函数,将X转换为一个NumPy数组,方便后续调用
# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer()
# 将word中的数据传递给vect
X = vect.fit_transform(word)
# 使用toarray()函数,将x转换为数组
X = X.toarray()
# 输出X进行查看
print(X)
考虑到初学的宝宝理解有困难,在简单分析一下代码
使用CountVectorizer来转换文本数据word。CountVectorizer是scikit-learn库中用于文本分析的工具,能够将文本数据转换为词频矩阵。
word它应该是一个包含文本字符串的列表。
下面是一个完整的例子,包括必要的导入和定义:
from sklearn.feature_extraction.text import CountVectorizer
# 假设我们有一个文本列表
words = ["the cat sat on the mat", "the dog sat on the log", "the cat and the dog"]
# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer()
# 将words中的数据传递给vect
X = vect.fit_transform(words)
# 使用toarray()函数,将X转换为数组
X_array = X.toarray()
# 输出X_array进行查看
print(X_array)
这段代码会输出一个二维数组,其中每一行代表words列表中的一个文本,每一列代表一个单词的词频。例如,如果words中的第一个文本包含单词"the"2次,那么在对应的数组行中,"the"所对应的列的值将会是2。
【昨日内容复习】
提取标签的具体步骤如下:
1. 创建一个空列表y用于存储标签数据
2. 使用for循环来遍历data中的每一行数据
3. 只从中提取标签部分,即每行的第二个数据,allInfo[1]
4. 将每行的标签数据逐一添加到列表y中
代码示例:
# 创建一个空列表y,用于存储标签
y = []
# 使用for循环遍历data,将遍历的数据存储到allInfo变量中
for allInfo in data:
# 提取allInfo中的标签数据
label = allInfo[1]
# 将标签逐一添加到列表y中
y.append(label)
# 输出列表y进行查看
print(y)
【昨日内容复习】
完成了第一步提取数据集的文本特征和标签后,我们就可以进行监督学习的第二个步骤:划分数据集。
具体步骤如下:
STEP1. 使用from...import... 从sklearn.model_selection中导入train_test_split;
STEP2. 使用train_test_split()将数据集划分为训练集和测试集,并将结果赋值给result
# 从sklearn.model_selection中导入train_test_split
from sklearn.model_selection import train_test_split
# 划分数据集,将数据分为训练集和测试集
result = train_test_split(X, y, train_size=0.8, random_state=1)
# 输出result进行查看
print(result)
【昨日内容复习】
为了方便后续调用,我们通过索引依次提取出了列表result中:训练集的文本特征、测试集的文本特征、训练集的标签和测试集的标签。
把它们分别赋值给了变量train_feature、test_feature、train_label和test_label。
# 依次提取result中训练集和测试集数据
train_feature = result[0]
test_feature = result[1]
train_label = result[2]
test_label = result[3]
在这种情况下,它们代表了一个包含训练和测试数据的结果集合。让我们来看看为什么这些数字被选择,并解释它们的含义:
result[0]:通常是训练数据集的特征。这是因为在机器学习中,通常首先会处理训练数据集,因此索引为0的位置用于存储训练数据的特征。result[1]:通常是测试数据集的特征。与训练数据集类似,测试数据集的特征被放置在索引为1的位置。result[2]:通常是训练数据集的标签。在监督学习任务中,训练数据集需要有相应的标签,因此在索引为2的位置存储了训练数据的标签。result[3]:通常是测试数据集的标签。与训练数据集类似,测试数据集的标签被放置在索引为3的位置。
这个顺序的选择主要是为了清晰和一致性,使得在使用这些数据时更加直观和方便。同时,这种约定也使得代码更易读和易于理解。
复习结束~
昨天我们完成了前两个步骤,接下来就到了第三步:选择一个合适的监督学习算法。
本例中,我们选择了一种应用最广泛的人工神经网络:多层感知器(Multilayer Perceptron)。

人工神经网络的名称和结构受到人类大脑的启发,模仿了节点(也称神经元)相互发送信号的方式。它至少由3个节点层组成:一个输入层、一个或多个隐藏层和一个输出层。
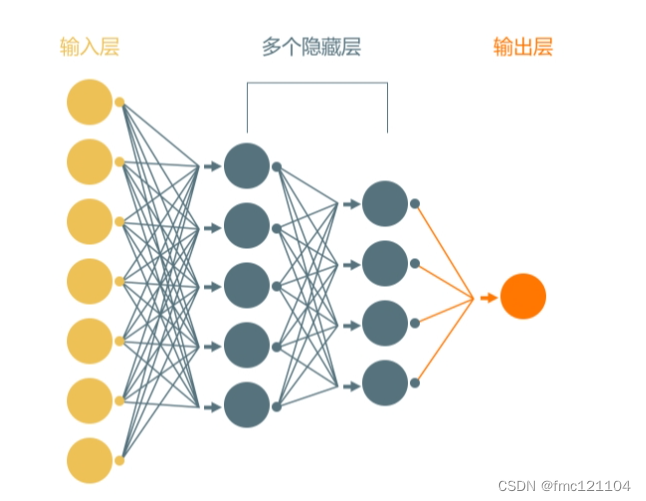
输入层:接收数据,如特征、字母、概念;
隐藏层:处在输入层和输出层之间,会对输入层的数据进行计算,并将信息传递到输出层;
输出层:输出分类或预测的处理结果。
神经网络的强大之处在于它们能够学习训练集中特征与标签之间的关系,完成高速分类的预测任务。像谷歌现在就是由神经网络算法进行机器翻译和搜索任务。这就是为什么会选择人工神经网络里应用最广泛的多层感知器作为我们的监督学习算法。
多层感知器(Multilayer Perceptron,简称MLP)是最基础、最简单的一种人工神经网络。它通常应用于监督学习问题。是自然语言处理、计算机视觉和其他神经网络的基础。
原理:
我们举个简单的例子来看看MLP是如何处理数据的:当原始数据传入到第一个隐藏层时,这些节点会返回对应的预测结果,而第二层的感知器会根据第一层返回的结果来进行二次处理。通过这样的方式,第二层的感知器就能处理更复杂和更抽象的数据。以此类推,多层感知器这样的层级结构,增强了信息的表示和处理能力,可以更加快速解决复杂问题。因此,选择了它作为本案例的算法。
选择完一个合适的监督学习算法后,我们就来到了下一步:
在训练集上使用多层感知器这个算法构造一个分类器模型~
sklearn.neural_network是sklearn中的神经网络模块,我们可以使用其中的MLPClassifier类。
它为我们提供了多层感知器算法,能直接搭建和训练一个分类器模型。

1. 导入模块
首先,我们需使用
from...import...,从 sklearn.neural_network 模块中导入 MLPClassifier 类。
# 从sklearn.neural_network中导入MLPClassifier
from sklearn.neural_network import MLPClassifier
2. 创建分类器
导入模块后,直接使用MLPClassifier(),创建一个MLPClassifier对象,也就是我们的分类器模型。
我们将返回的对象存储在变量mlp中。
# 创建MLPClassifier对象,并存储在mlp变量中
mlp = MLPClassifier()
3. 训练分类器
接下来,就可以对mlp对象使用fit()函数,来完成模型的训练。
只需将训练集的数据,也就是文本特征train_feature和标签train_label,依次传入该函数中即可。
我们的分类器会学习传入的文本特征和标签之间的关系。
# 通过train_feature和train_label,训练分类器
mlp.fit(train_feature, train_label)
我们再来自己操作一下搭建和训练一个多层分类器模型吧~~~
我们已经完成了监督学习的前四个步骤,成功通过训练集建立了分类器模型,现在可以进行第五步啦:
使用测试集来预测并评估模型的准确率。
如何使用测试集评估模型的准确率呢?
回忆一下,测试集和训练集都既有文本特征又有标签。
那么我们可以先把测试集的文本特征传入到训练好的模型中,该模型会预测出对应的标签数据。然后将预测结果和测试集原本的标签进行对比,就可以评估该模型的准确率啦。

1. 对测试集的文本特征进行预测
MLPClassifier类中提供了predict()函数,它会通过刚刚创建的多层感知器对测试集的数据进行预测。
只需对创建的分类器对象使用predict()函数,再将测试集的文本特征作为参数传入该函数中即可。
该函数会返回预测的标签数据。
本例中,我们对mlp使用了predict()函数,并将测试集的文本特征test_feature传入到该函数里。我们将模型预测的标签结果存储在变量test_pred中,并输出进行查看。
# 对测试集数据进行预测
test_pred = mlp.predict(test_feature)
# 输出test_pred
print(test_pred)

2. 计算准确率
有了预测结果后,我们就可以通过对比【依靠模型生成的测试集标签数据test_pred】和【测试集原本的标签数据test_label】,来检验模型的准确率。
sklearn.metrics模块中的accuracy_score类,为我们提供了一个可以计算准确率的函数:accuracy_score()。
2.1 导入模块
首先,我们还是需要使用from...import...,从sklearn.metrics模块中导入accuracy_score类,用于评估分类模型的准确率。
# 从sklearn.metrics中导入accuracy_score
from sklearn.metrics import accuracy_score
2.2 计算模型准确率
接下来,就可以使用accuracy_score()函数,只需依次传入test_pred和test_label即可。
该函数会对比这两个数据,返回一个模型的预测准确率得分。
# 计算预测准确率,并将结果赋值给score
score = accuracy_score(test_pred,test_label)
# 输出score进行查看
print(score)

我们将score输出,结果为0.825,即预测准确率为82.5%。每次运行时,该准确率都会有小幅度的波动,属于正常现象~
现在,我们来自己尝试一下:使用测试集来评估模型的准确率吧~
STEP1. 使用predict()函数,对测试集的文本特征进行预测
STEP2. 导入sklearn.metrics模块中的accuracy_score类,并使用accuracy_score()函数计算模型准确率得分
# 对测试集数据进行预测
test_pred = mlp.predict(test_feature)
# 从sklearn.metrics中导入accuracy_score
from sklearn.metrics import accuracy_score
# 计算预测准确率,并将结果赋值给score
score = accuracy_score(test_pred,test_label)
# 输出score进行查看
print(score)
最终我们训练出的模型准确率大概在80%左右,不算是一个完美的模型,还有一些改进的空间。
比如:
可以尝试添加更多的训练数据;
在创建分类器,也就是使用MLPClassifier()时,传入不同的参数并进行调整等。
这里我们就不做更多的探索啦~
用于做情感分析的分类器模型就算搭建完成啦!我们来到了最后一个步骤:对“没有标签”的评价进行预测。
我们只需定义一条评价,然后剩余的步骤和之前一样。最后我们将预测结果输出,根据输出就可以检验搭建的模型效果如何啦~
# 自定义一条评价,并存储在变量comment中
comment = "太差了,新电视买回家不到十多天,底座支架因质量问题断裂,电视直接从桌子上摔坏!"
# 使用jieba.lcut()对comment进行分词
comment = jieba.lcut(comment)
# 使用join()函数处理分词结果
comment = [' '.join(comment)]
# 构造词袋模型
try_feature = vect.transform(comment)
# 使用toarray()函数把结果转换为NumPy数组
try_feature = try_feature.toarray()
# 使用predict()函数预测结果
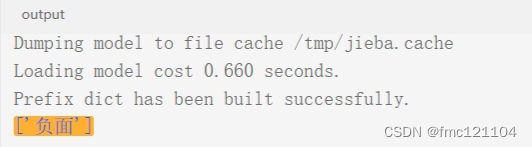
try_pred = mlp.predict(try_feature)
# 输出预测结果
print(try_pred)
小科普(会涉及到一点数学概念哦)
细心的同学可能已经发现,我们在处理数据集时使用的是fit_transform()函数,但在处理没有标签的预测数据时使用的是transform()函数,为什么呢?
fit_transform()其实是fit()和transform()的组合,多用于在训练数据时使用。
在调用fit_transform()时,会先通过fit(),计算和学习数据中每个特征的均值和方差;再通过transform(),使用各自的均值和方差来变换所有特征。
小科普
那么对于没有标签的数据,如果使用fit()函数,则会重新计算一份新的特征均值和方差,这样的话我们的模型就会又学习一遍没有标签数据的特征。
因此,我们只需要使用transform(),这样就可以使用相同的均值和方差来对没有标签的数据进行转换,同时又避免了我们的模型学习预测数据的特征。
这里,就不做更深入地解释啦~














 2942
2942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









