






大模型微调实验的核心目标的通过实验找到最佳的优化方法,来提升大模型的正向收益。
本文通过记录一次基于ChatGLM-6B 大模型微调实验,验证对话场景中历史对话轮次是否越长越好,来说明如何做大模型的微调实验,给大家一些参考。
如何做大模型的微调实验,其实每次实验都需要有明确的实验目的,算法的优化方法有很多,如数据样本质量优化,模型参数优化、损失函数优化、模型网络结构优化等等。但是,每次优化迭代的效果怎么样,需要设计对比实验来验证,验证实验目的是否符合预期。下面看看,一次大模型的微调实验的实验报告。
一、背景与实验目的
验证历史对话轮次是否越长越好,通过训练两个模型,控制变量max_source_length|max_target_length,对训练好之后的模型从Loss、Bleu指标、离线人工评估等角度进行对比分析。
二 、数据样本
全量数据经过降采样后,从中随机10w样本进行测试。
三、 模型优化
关注对比参数:
512-10w-模型 | 1024-10w-模型 | |
max_source_length | 512 | 1024 |
max_target_length | 128 | 256 |
lr | 1e-5 | 1e-5 |
num_train_epochs | 5 | 5 |
per_device_train_batch_size | 2 | 1 |
四、离线效果
Loss情况:
1024-10w-模型loss下降得更低,到0.5x,512-10w模型loss到0.9x。说明在训练集上1024拟合更好。
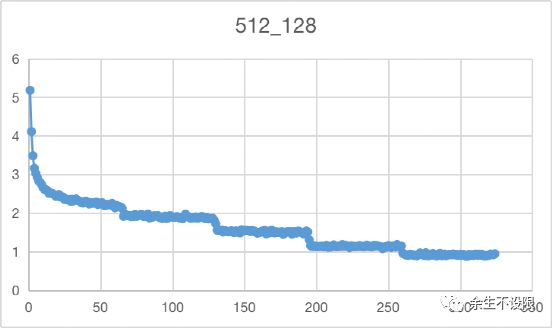
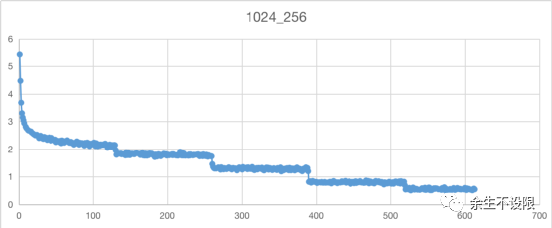
Loss指标说明:
在机器学习中,Loss是损失函数,它衡量模型的预测输出和真实目标值之间的差距,用来评估模型的预测性能。
常见的Loss函数包括:
- Mean Squared Error(MSE):均方误差,用于回归问题,计算预测值和目标值差的平方和的平均数。
- Cross Entropy:交叉熵,用于分类问题,计算预测概率分布和真实概率分布之间的距离。
- Hinge Loss:合页损失,用于分类问题,计算预测值和目标值之间的最大边界距离。
- Kullback-Leibler Divergence:KL散度,计算两个概率分布之间的距离。
Loss值越低,表示模型预测效果越好。所以训练过程中要不断通过优化算法(梯度下降等)来最小化Loss,使模型预测结果不断接近目标
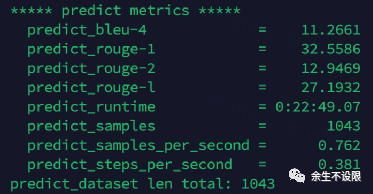
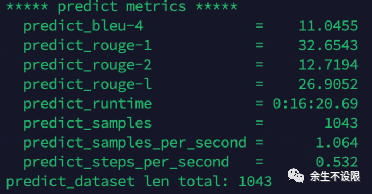
Bleu情况:
bleu指标1024比512低0.1%。
评测集:1043个样本
512-模型:
1024-模型,推理使用512-128长度:
1024-模型,推理使用1024-256长度:
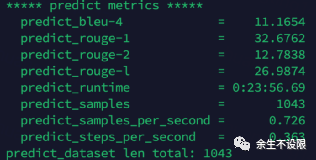
BLEU指标说明:
BLEU(Bilingual Evaluation Understudy)是一种用于评估机器翻译输出质量的自动评测算法。
BLEU的基本思想是:将机器翻译系统输出的翻译结果与人工参考翻译进行比较,计算两者的相似度,来评估机器翻译的质量。BLEU计算方法主要有:
1. n-gram精度:计算机器翻译输出中的n-gram(一串n个词)与参考译文的匹配程度。
2. 修正的精度:对长度过短的句子进行惩罚,防止只输出短小句子来获得高分。
3. BLEU得分:综合N-gram精度和修正的精度,得到0-100分的BLEU评测分数。分数越高表示翻译结果越好。
4. 对多参考译文取平均:使用多份参考译文来获得更准确的评测结果。
人工评估:
评估样本量较少。从少量样本上看1024全量是有优势的!
五、实验结论
结论:从人工评估少量样本以及loss下降来看,历史对话长度1024比512长度好,后续模型训练可以扩大到1024长度。
感谢关注“余生不设限”,陪您一起成长!

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









