







无监督学习得到数据特征,可以在最高层加入一个分类器并通过监督学习进行微调。
1有限波尔兹曼机(RBM)
2自动编码器(Autoencoder)
2.1结构
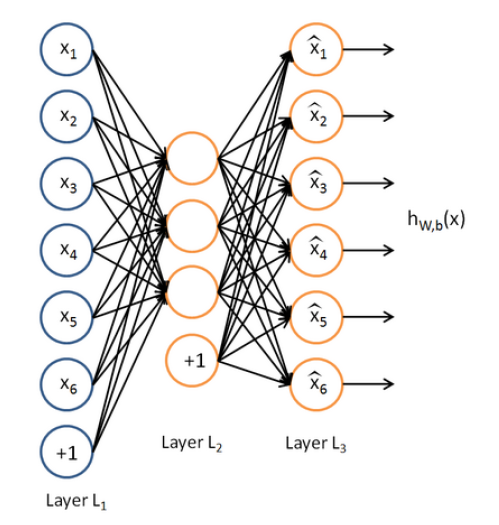
输入层神经元个数等于输出层神经元的个数。
激活函数
- 线性
- 均方差激活函数
- sigmoid
- 使用交叉熵损失函数
- 其他
2.2损失函数
以方差代价为例,单个样本的损失函数为:
J(W,b;x,y)=12||hW,b(x)−y||2
对包含
m
个样本的数据集,训练的目标函数为
上式中第一项表示所有样本的平均损失,第二项是一个规则化项(或称为权值衰减项),防止过拟合。
2.3 Sparse Autoencoder & Denoise Autoencoder
如果只有最小化重构误差这个限制,那么autoencoder可能不会抽取到最有效的特征,致使隐藏层的结点个数大于输入神经元的数目,解决这个问题有多种不同的方式。如增加稀疏性限制、增加噪声。
稀疏性
当隐藏层的神经元较多时,则希望尽可能多的隐藏神经元被抑制。如果激活函数为sigmoid,则神经元输出接近1时为激活状态,接近0时为抑制状态。
在给定输入
x
的情况下,神经元
ρ^=ρ
其中
ρ
为稀疏性系数,取接近0的值,如0.001。
可以使用相对熵(KL divergence)来表示 ρ^ 和 ρ 的接近程度,
∑j=1S2KL(ρ||ρ^j)=∑j=1S2ρlogρρ^j+(1−ρ)log1−ρ1−ρ^j(2)
其中
S2
表示隐藏层神经元的个数。将相对熵加入式(1)的目标函数中得
Jsparse=J(W,b)+β∑j=1S2KL(ρ||ρ^j)(3)
这样发展为当隐藏层的神经元的数目较少时,即少于输入神经元的数目,可以得到原始数据的压缩表示。
噪声
在特征学习过程中增加随机噪声,这就是Denoise Autoencoder,这样得到的隐藏层更具有鲁棒性。通常的做法是对输入数据进行一定的“破坏”,比如随机选取一些输入项并将其他的项置为0.(注意对比RBM的CD训练算法中对输入数据的随机破坏)















 1562
1562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









