






2019-1-4 更
1. 神经元Neuron:接受输入产生输出的基本单位。
2. 权重Weights:矩阵或张量,与输入相乘后与偏差相加。
3. 偏差Bias:被应用于输入的线性分量,改变权重与输入相乘的结果范围。
4. 激活函数 Activation:非线性,保留并映射神经元特征:
- sigmoid:

产生(0, 1)之间的平滑范围值;当输入稍微远离原点,函数梯度就变得很小;函数输出不是以0为中心的,这样会使权重更新效率降低;要进行指数运算,慢;
- tanh 双曲正切函数:
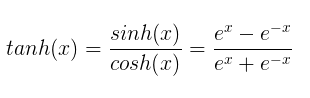
输入很大或很小时,输出平滑,梯度小,不利于权重更新;输出区间是在(-1,1)之间,函数是以0为中心,比sigmod好;
- ReLU:

ReLU函数只有线性关系,对所有大于零的输入有常量导数值,训练快;当输入是负数的时候,ReLU是完全不被激活的;
- Softmax:

用来进行最后的分类和归一化;
5. 多层感知器MLP:有多个神经元层,也叫深度神经网络。
6. 正向传播 Forward Propagation:输入通过隐藏层到输出层的运动。
7. 反向传播 Back Propagation:单词迭代输出后,计算出误差和成本函数梯度反馈给网络来更新网络权重的过程。
8. 成本函数 Cost Function / 损失函数 Loss Function:用于衡量网络输出的准确性。
- 均方差损失 MSE(欧式距离):mean_squared_error
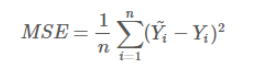
- 交叉熵损失 cross entropy (对数损失函数):
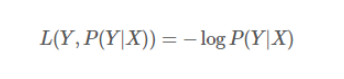
binary_cossentropy:二分类交叉熵损失
categorical_crossentropy:多分类交叉熵损失,使用多分类交叉熵损失函数时,标签使用one-hot编码
- 指数损失函数(Adboost中):
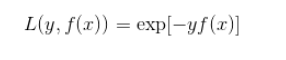
- Hinge损失函数(SVM中):
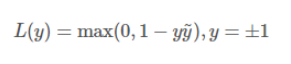
9. 梯度下降 Gradient Descent: 最小化成本的优化算法,负导数方向,下降速度最快。
10. 学习率 Learning Rate: 每次迭代中损失函数中最小化的量, 即下降到损失函数最小化的速率就是学习率。过大易震荡,过小收敛慢。
11. 梯度下降参数更新方式:
- 批梯度下降 Batch Gradient Descent: 全部数据集计算一遍后更新参数,开销大,速度慢
- 随机梯度下降 Stochastic Gradient Descent:每计算一个数据更新一次参数,易震荡,不易收敛
- 小批次梯度下降 Mini-Batch Gradient Descent: 将数据划分为若干批次,按批更新参数
12. 批次大小 batch_size: 每次SGD训练使用的样本数
13. iteration: 一个iteration等于使用batch_size个样本训练一次,即 样本总数 = iteration * batch_size
14. epoch: 使用全部样本训练一次(Forward + Bachward Propagation),每个epoch要shuffle一次
15. dropout: 一种正则化技术,防止过拟合,在训练期间随机丢弃网络部分功能,增强网络泛化功能
16. 卷积核 / 滤波器 Filter: 一种加权矩阵,与输入部分相点乘(卷积)产生一个回旋输出,维度为FxFxC (长、宽、通道)
17. 池化层 Pooling:减少参数,防止过拟合,Maxpooling(常用)、Meanpooling
18. 填充 Padding: zero padding -> 在图像四周添加零层,使图像输入输出尺寸保持一致;
valid padding -> 卷积之后图像尺寸缩小(卷积核起始中心不是图像左上角的像素点)
19. 数据增强 Data Augmentation:微调图像属性,产生更多图像,增加数据集的属性特征,提高模型泛化能力。
20. 梯度消失 / 梯度弥散 Vanishing Gradient: 激活函数梯度非常小时,权重乘以小梯度的值在反向传播时随着网络加深进一步消失,网络权重更新停滞。
RNN网络容易发生梯度弥散原因:用到sigmoid的特点,梯度过小,梯度表达式是一个连乘式,随着网络加深,只要有某些项小于1就会使得梯度逐渐变小。
解决:
- 使用ReLU(梯度恒定,不存在小梯度)
- 加入BN(Batch Normalization)层
- 使用LSTM网络
21. 梯度爆炸 Exploding Gradient:激活函数梯度过大,使得特定结点权重显著高于其他结点权重。
现象:
- 模型无法从训练数据中获得更新(如低损失)
- 模型不稳定,导致更新过程中的损失出现显著变化。
- 训练过程中,模型损失溢出变成 NaN。
解决:
- 使用ReLU激活函数
- 使用梯度截断(Gradient Clipping):在训练过程中检查和限制梯度的大小
- 使用权重正则化(Weight Regularization):检查网络权重的大小,并惩罚产生较大权重值的损失函数,通常使用的是 L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。
22. 超参数 Hyper Parameters: 根据经验确定的变量(与网络中自动更新的变量相对),如 learning rate, iteration, batch_size...
23. 批标准化 Batch Normalization: 在过程中使每一层神经网络的输入保持相同分布的,通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布
24. 全连接 Fully Connected:全连接层在平坦输入上操作(所以一般最后的FC层前都会有个Flatten层),将每个输入都连接到所有神经元,FC层基本在卷积网络的最后部分。
25. stride:卷积和池化操作中每次窗口移动的像素数。
26. 感受野:卷积神经网络特征所能看到输入图像的区域,换句话说特征输出受感受野区域内的像素点的影响。第K层的感受野区域记为Rk x Rk,即为第K次激活映射可以看见的输入像素。若层j上的过滤器大小为Fj,层i上的Stride值为Si,且S0=1,则层k上的感受野可以由下式计算出:
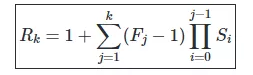
27. 目标检测中三类主要识别算法:
传统CNN:整张图像分类+概率预测
简易YOLO,R-CNN:图像中检测物体+预测概率和定位
YOLO,R-CNN: 图像中检测多个物体+预测概率和定位
28. 目标检测方法:
边框检测 Bounding Box Detection:检测图像中物体所在部分,Box中心: (Bx, By) Box长宽: (Bh, Bw)
特征点检测 Landmark Detection:检测物体形状或特征(更精细 more granular), 返回点集
29. 交并比 Intersection over Union (IoU): 量化预测边框Bp在实际边框Ba上正确定位的函数:
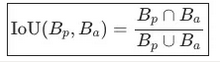
30. Anchor Box:为了解决同一个网格中有多个目标对象,用于多目标检测。网络可以同时预测多个box,其中每个box的预测被约束具有给定的一组几何特性。例如,第一个预测可能是给定形状的矩形框,而第二个预测可能是另一个形状不同的矩形框。
图像来自:https://blog.csdn.net/zkq_1986/article/details/78975379 ,侵删

31. 端到端 目标检测 End-to-End:不用事先定义候选框region proposal,算法分为两部分,一是确定目标所在位置及大小,二是判断目标的类别。
31. 候选框(region proposal):非end-to-end目标检测算法中在图像中提取可能含有目标的box。
32. 非极大值抑制 Non-max Suppression (NMS): 通过选择最具代表性的对象来删除同一对象的重叠边界框。
步骤1:选择具有最大预测概率的框。
步骤2:删除任何与前一个框的IoU⩾0.5的框。
33. YOLO - You Only Look Once

34. R-CNN (Region with Convolutional Neural Networks): 首先对图像进行分割以找到潜在的相关边界框,然后运行检测算法,在那些边界框中找到最可能的对象。

35. 生成对抗网络(Generative Adversarial Network, GAN): 由生成模型和判别模型组成,其中生成模型旨在生成最真实的输出,这些输出将被用于区分生成图像和真实图像。

36. 残差网络(Residual Network, ResNet):使用具有大量层的residual blocks来减少训练误差。 residual blocks 具有以下特征:

37. Inception Network: 该架构使用 inception modules,目的是尝试不同的卷积,以通过特征的多样化来提高其性能。具体来说,它使用1×1卷积技巧来限制计算负担。
38. TP, FP, TN, FN, Recall, Precision
TP(True Positive)
FP(False Positive)
TN(True Negative)
FN(False Negative)
Precision = TP / (TP+FP) 准确率
Recall = TP / (TP+FN) 召回率

39. TPR, TFR, FPR, FNR
TPR: True Positive Rate 正真率 / 灵敏度
TFR: True False Rate 真负率 / 特指度
FNR: Fasle Negative Rate 假负率 / 虚警率
FPR: False Positive Rate 假正率

40. AP, mAP, P-R曲线

P-R曲线(准确-召回曲线)
AP(Average Precision): P-R曲线下的面积;
mAP(mean Average Precision):多个类别AP的均值;
41. ROC曲线、AUC
ROC曲线:用不同的阀值,统计出一组不同阀值下的TPR(真阳率)和FPR(假阳率)的关系。
AUC(Area under Curve): ROC曲线下的面积;
ROC曲线的优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
IOU(Intersection Over Union): 交并比
42. Fps、FLOPS
Fps(frames per second):每秒处理图像的帧数;
FLOPS:每秒浮点运算次数、每秒峰值速度;
43. GOPS: 10亿次/每秒,衡量处理器计算能力的指标单位;
44. 上采样 : upsampling的主要目的是放大图像,几乎都是采用内插值法,即在原有图像像素的基础上,在像素点值之间采用合适的插值算法插入新的元素。

45. 线性插值法:利用原图像中两个点计算像素值进行插值,
双线性插值法:利用原图像中四个点计算目标像素值进行插值。
46. 反池化 Unpooling: 在池化过程中,记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0 ;

47. 反卷积(Deconvolution): https://blog.csdn.net/francislucien2017/article/details/85772003

48. LRN(Local Response Normolization)局部响应归一化:
对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力;
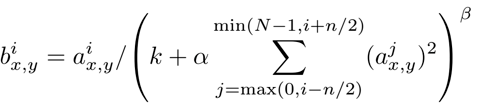
ai(x,y)表示在这个输出结构中的一个位置[a,b,c,d],第a张图的第d个通道下的高度为b宽度为c的点;a,n/2,k,α,β分别表示函数中的input, depth_radius, bias, alpha, beta,其中n, k, alpha, belta 都是超参数,一般设置k=2, n=5, alpha=1e-4, beta=0.75;














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









