






查看GPU版本和使用情况
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
There are 1 GPU(s) available.
We will use the GPU: GeForce GTX 1070
导入评论信息
import pandas as pd
path = './中文文本情感分类/'
comments = pd.read_csv(path + '酒店评论.csv')
moods = {0: '正面', 1: '负面'}
print('文本数量(总体):%d' % comments.shape[0])
for label, mood in moods.items():
print('文本数量({}):{}'.format(mood, comments[comments.label==label].shape[0]))
文本数量(总体):7766
文本数量(正面):2444
文本数量(负面):5322
简单查看一下数据集
comments[0:5]
| label | review | |
|---|---|---|
| 0 | 1 | 距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较... |
| 1 | 1 | 商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错! |
| 2 | 1 | 早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。 |
| 3 | 1 | 宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小... |
| 4 | 1 | CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风 |
由于数据实在太多,我们在这里每一种情感 选择1000个例子
# 标签为 0 的数据
df0 = comments.loc[comments.label == 0].sample(1000)[['review', 'label']]
# 标签为 1 的数据
df1 = comments.loc[comments.label == 1].sample(1000)[['review', 'label']]
由于数据集太大,组成新的数据集并且打乱顺序
df0 = df0.append(df1)
df0 = df0.sample(frac=1)
len(df0)
2000
简单查看一下数据
df0[0:5]
| review | label | |
|---|---|---|
| 6346 | 先说优点:装修是新的,房间很大,房间灯光、家具都不错,达到3星水平。山庄所处位置风景优美,整... | 0 |
| 2180 | 酒店位置不错!服务可以!只是楼下是酒家,油烟味太重!晚上夜宵人声稍大! | 1 |
| 6378 | 房间小的可怜,同样的价格,其他地方条件好多了. | 0 |
| 4928 | 帮朋友订过,大家反映还不错,住宿条件满好的.房价不贵,早餐品种还算丰富,中午自助相当便宜,建... | 1 |
| 4839 | 房间非常大,我住的大床房,床有1.8米宽,热水很大,洗澡舒服,洗脸盆也大,可洗衣服了.早晨没... | 1 |
把数据集中的句子和标签取出来
# 句子和标签
df0 = df0.fillna(" ")
sentences = df0.review.values
labels = df0.label.values
下载 BERT tokenizer.
from transformers import BertTokenizer
print('下载 BERT tokenizer...')
#tokenizer = BertTokenizer.from_pretrained('chinese_L-12_H-768_A-12', do_lower_case=True)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', do_lower_case=True)
下载 BERT tokenizer...
简单查看一下 tokenizer
print(' 原句: ', sentences[0])
print('Tokenizen 后的句子: ', tokenizer.tokenize(sentences[0]))
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
原句: 先说优点:装修是新的,房间很大,房间灯光、家具都不错,达到3星水平。山庄所处位置风景优美,整体布局设计体现了一定的水平。再说缺点:管理水平跟农村招待所差不多。一大早空调就没电了,原来是服务员在外面关了房间的开关,打电话之后服务员才把开关打开。早上9点不到,有客人退房,服务员持对讲机在楼道里用能吵醒整个楼层任何甜梦的声音在跟前台对讲,把整个山庄最可贵的宁静搅扰得荡然无存。最后是最要命的:温泉的水根本看不出是温泉,脏的简直就是山脚下湖里头抽上来的湖水。虽说可以随时调温,可是任你泡你看着那一池你专用的浑浊的温泉水,谅你也不敢泡久!宾馆反馈2006年12月29日:感谢您选择颐和温泉度假山庄,享受美好的假期。我们很重视您提的宝贵意见,同时做了相应的调查。关于房间空调电源一事是由于当天早上有一位客人在温泉区泡温泉的时候将路边的灯泡不小心打烂,造成电路湿水而自动断电保护的,这也是对客人安全的一个保障。酒店客房区内采用现代最新的电路技术,由电房总控制,所以在酒店房间及门口是没有电源开关设施的。酒店是不会,而且不允许任何人,在正常情况下关闭已有客人入住的房间的所有设施。颐和温泉度假山庄的温泉是属于极热型的氡温泉,氡温泉为无味,颜色相对淡黄,为了更好的配合按摩效果,我们在每个温泉池都采用浅棕色,浅黄色等的鹅卵石为铺垫,故此经过光线的折射会给客人“不干净”的错觉。您可以放心的使用,体会温泉带来的美好享受。服务员不正确使用对讲机的行为属于个别偶尔现象,当然,也是我们管理的一个疏忽,就该事情,我们已经对其进行相关教育。再次感谢您对我们提出的宝贵意见和建议,我们会努力改进每一个细节,让大家度过一个美好而难忘的假期。
Tokenizen 后的句子: ['先', '说', '优', '点', ':', '装', '修', '是', '新', '的', ',', '房', '间', '很', '大', ',', '房', '间', '灯', '光', '、', '家', '具', '都', '不', '错', ',', '达', '到', '3', '星', '水', '平', '。', '山', '庄', '所', '处', '位', '置', '风', '景', '优', '美', ',', '整', '体', '布', '局', '设', '计', '体', '现', '了', '一', '定', '的', '水', '平', '。', '再', '说', '缺', '点', ':', '管', '理', '水', '平', '跟', '农', '村', '招', '待', '所', '差', '不', '多', '。', '一', '大', '早', '空', '调', '就', '没', '电', '了', ',', '原', '来', '是', '服', '务', '员', '在', '外', '面', '关', '了', '房', '间', '的', '开', '关', ',', '打', '电', '话', '之', '后', '服', '务', '员', '才', '把', '开', '关', '打', '开', '。', '早', '上', '9', '点', '不', '到', ',', '有', '客', '人', '退', '房', ',', '服', '务', '员', '持', '对', '讲', '机', '在', '楼', '道', '里', '用', '能', '吵', '醒', '整', '个', '楼', '层', '任', '何', '甜', '梦', '的', '声', '音', '在', '跟', '前', '台', '对', '讲', ',', '把', '整', '个', '山', '庄', '最', '可', '贵', '的', '宁', '静', '搅', '扰', '得', '荡', '然', '无', '存', '。', '最', '后', '是', '最', '要', '命', '的', ':', '温', '泉', '的', '水', '根', '本', '看', '不', '出', '是', '温', '泉', ',', '脏', '的', '简', '直', '就', '是', '山', '脚', '下', '湖', '里', '头', '抽', '上', '来', '的', '湖', '水', '。', '虽', '说', '可', '以', '随', '时', '调', '温', ',', '可', '是', '任', '你', '泡', '你', '看', '着', '那', '一', '池', '你', '专', '用', '的', '浑', '浊', '的', '温', '泉', '水', ',', '谅', '你', '也', '不', '敢', '泡', '久', '!', '宾', '馆', '反', '馈', '2006', '年', '12', '月', '29', '日', ':', '感', '谢', '您', '选', '择', '颐', '和', '温', '泉', '度', '假', '山', '庄', ',', '享', '受', '美', '好', '的', '假', '期', '。', '我', '们', '很', '重', '视', '您', '提', '的', '宝', '贵', '意', '见', ',', '同', '时', '做', '了', '相', '应', '的', '调', '查', '。', '关', '于', '房', '间', '空', '调', '电', '源', '一', '事', '是', '由', '于', '当', '天', '早', '上', '有', '一', '位', '客', '人', '在', '温', '泉', '区', '泡', '温', '泉', '的', '时', '候', '将', '路', '边', '的', '灯', '泡', '不', '小', '心', '打', '烂', ',', '造', '成', '电', '路', '湿', '水', '而', '自', '动', '断', '电', '保', '护', '的', ',', '这', '也', '是', '对', '客', '人', '安', '全', '的', '一', '个', '保', '障', '。', '酒', '店', '客', '房', '区', '内', '采', '用', '现', '代', '最', '新', '的', '电', '路', '技', '术', ',', '由', '电', '房', '总', '控', '制', ',', '所', '以', '在', '酒', '店', '房', '间', '及', '门', '口', '是', '没', '有', '电', '源', '开', '关', '设', '施', '的', '。', '酒', '店', '是', '不', '会', ',', '而', '且', '不', '允', '许', '任', '何', '人', ',', '在', '正', '常', '情', '况', '下', '关', '闭', '已', '有', '客', '人', '入', '住', '的', '房', '间', '的', '所', '有', '设', '施', '。', '颐', '和', '温', '泉', '度', '假', '山', '庄', '的', '温', '泉', '是', '属', '于', '极', '热', '型', '的', '氡', '温', '泉', ',', '氡', '温', '泉', '为', '无', '味', ',', '颜', '色', '相', '对', '淡', '黄', ',', '为', '了', '更', '好', '的', '配', '合', '按', '摩', '效', '果', ',', '我', '们', '在', '每', '个', '温', '泉', '池', '都', '采', '用', '浅', '棕', '色', ',', '浅', '黄', '色', '等', '的', '鹅', '卵', '石', '为', '铺', '垫', ',', '故', '此', '经', '过', '光', '线', '的', '折', '射', '会', '给', '客', '人', '[UNK]', '不', '干', '净', '[UNK]', '的', '错', '觉', '。', '您', '可', '以', '放', '心', '的', '使', '用', ',', '体', '会', '温', '泉', '带', '来', '的', '美', '好', '享', '受', '。', '服', '务', '员', '不', '正', '确', '使', '用', '对', '讲', '机', '的', '行', '为', '属', '于', '个', '别', '偶', '尔', '现', '象', ',', '当', '然', ',', '也', '是', '我', '们', '管', '理', '的', '一', '个', '疏', '忽', ',', '就', '该', '事', '情', ',', '我', '们', '已', '经', '对', '其', '进', '行', '相', '关', '教', '育', '。', '再', '次', '感', '谢', '您', '对', '我', '们', '提', '出', '的', '宝', '贵', '意', '见', '和', '建', '议', ',', '我', '们', '会', '努', '力', '改', '进', '每', '一', '个', '细', '节', ',', '让', '大', '家', '度', '过', '一', '个', '美', '好', '而', '难', '忘', '的', '假', '期', '。']
Token IDs: [1044, 6432, 831, 4157, 8038, 6163, 934, 3221, 3173, 4638, 8024, 2791, 7313, 2523, 1920, 8024, 2791, 7313, 4128, 1045, 510, 2157, 1072, 6963, 679, 7231, 8024, 6809, 1168, 124, 3215, 3717, 2398, 511, 2255, 2411, 2792, 1905, 855, 5390, 7599, 3250, 831, 5401, 8024, 3146, 860, 2357, 2229, 6392, 6369, 860, 4385, 749, 671, 2137, 4638, 3717, 2398, 511, 1086, 6432, 5375, 4157, 8038, 5052, 4415, 3717, 2398, 6656, 1093, 3333, 2875, 2521, 2792, 2345, 679, 1914, 511, 671, 1920, 3193, 4958, 6444, 2218, 3766, 4510, 749, 8024, 1333, 3341, 3221, 3302, 1218, 1447, 1762, 1912, 7481, 1068, 749, 2791, 7313, 4638, 2458, 1068, 8024, 2802, 4510, 6413, 722, 1400, 3302, 1218, 1447, 2798, 2828, 2458, 1068, 2802, 2458, 511, 3193, 677, 130, 4157, 679, 1168, 8024, 3300, 2145, 782, 6842, 2791, 8024, 3302, 1218, 1447, 2898, 2190, 6382, 3322, 1762, 3517, 6887, 7027, 4500, 5543, 1427, 7008, 3146, 702, 3517, 2231, 818, 862, 4494, 3457, 4638, 1898, 7509, 1762, 6656, 1184, 1378, 2190, 6382, 8024, 2828, 3146, 702, 2255, 2411, 3297, 1377, 6586, 4638, 2123, 7474, 3009, 2817, 2533, 5782, 4197, 3187, 2100, 511, 3297, 1400, 3221, 3297, 6206, 1462, 4638, 8038, 3946, 3787, 4638, 3717, 3418, 3315, 4692, 679, 1139, 3221, 3946, 3787, 8024, 5552, 4638, 5042, 4684, 2218, 3221, 2255, 5558, 678, 3959, 7027, 1928, 2853, 677, 3341, 4638, 3959, 3717, 511, 6006, 6432, 1377, 809, 7390, 3198, 6444, 3946, 8024, 1377, 3221, 818, 872, 3796, 872, 4692, 4708, 6929, 671, 3737, 872, 683, 4500, 4638, 3847, 3843, 4638, 3946, 3787, 3717, 8024, 6446, 872, 738, 679, 3140, 3796, 719, 8013, 2161, 7667, 1353, 7668, 8213, 2399, 8110, 3299, 8162, 3189, 8038, 2697, 6468, 2644, 6848, 2885, 7573, 1469, 3946, 3787, 2428, 969, 2255, 2411, 8024, 775, 1358, 5401, 1962, 4638, 969, 3309, 511, 2769, 812, 2523, 7028, 6228, 2644, 2990, 4638, 2140, 6586, 2692, 6224, 8024, 1398, 3198, 976, 749, 4685, 2418, 4638, 6444, 3389, 511, 1068, 754, 2791, 7313, 4958, 6444, 4510, 3975, 671, 752, 3221, 4507, 754, 2496, 1921, 3193, 677, 3300, 671, 855, 2145, 782, 1762, 3946, 3787, 1277, 3796, 3946, 3787, 4638, 3198, 952, 2199, 6662, 6804, 4638, 4128, 3796, 679, 2207, 2552, 2802, 4162, 8024, 6863, 2768, 4510, 6662, 3969, 3717, 5445, 5632, 1220, 3171, 4510, 924, 2844, 4638, 8024, 6821, 738, 3221, 2190, 2145, 782, 2128, 1059, 4638, 671, 702, 924, 7397, 511, 6983, 2421, 2145, 2791, 1277, 1079, 7023, 4500, 4385, 807, 3297, 3173, 4638, 4510, 6662, 2825, 3318, 8024, 4507, 4510, 2791, 2600, 2971, 1169, 8024, 2792, 809, 1762, 6983, 2421, 2791, 7313, 1350, 7305, 1366, 3221, 3766, 3300, 4510, 3975, 2458, 1068, 6392, 3177, 4638, 511, 6983, 2421, 3221, 679, 833, 8024, 5445, 684, 679, 1038, 6387, 818, 862, 782, 8024, 1762, 3633, 2382, 2658, 1105, 678, 1068, 7308, 2347, 3300, 2145, 782, 1057, 857, 4638, 2791, 7313, 4638, 2792, 3300, 6392, 3177, 511, 7573, 1469, 3946, 3787, 2428, 969, 2255, 2411, 4638, 3946, 3787, 3221, 2247, 754, 3353, 4178, 1798, 4638, 3704, 3946, 3787, 8024, 3704, 3946, 3787, 711, 3187, 1456, 8024, 7582, 5682, 4685, 2190, 3909, 7942, 8024, 711, 749, 3291, 1962, 4638, 6981, 1394, 2902, 3040, 3126, 3362, 8024, 2769, 812, 1762, 3680, 702, 3946, 3787, 3737, 6963, 7023, 4500, 3840, 3473, 5682, 8024, 3840, 7942, 5682, 5023, 4638, 7900, 1317, 4767, 711, 7215, 1807, 8024, 3125, 3634, 5307, 6814, 1045, 5296, 4638, 2835, 2198, 833, 5314, 2145, 782, 100, 679, 2397, 1112, 100, 4638, 7231, 6230, 511, 2644, 1377, 809, 3123, 2552, 4638, 886, 4500, 8024, 860, 833, 3946, 3787, 2372, 3341, 4638, 5401, 1962, 775, 1358, 511, 3302, 1218, 1447, 679, 3633, 4802, 886, 4500, 2190, 6382, 3322, 4638, 6121, 711, 2247, 754, 702, 1166, 981, 2209, 4385, 6496, 8024, 2496, 4197, 8024, 738, 3221, 2769, 812, 5052, 4415, 4638, 671, 702, 4541, 2575, 8024, 2218, 6421, 752, 2658, 8024, 2769, 812, 2347, 5307, 2190, 1071, 6822, 6121, 4685, 1068, 3136, 5509, 511, 1086, 3613, 2697, 6468, 2644, 2190, 2769, 812, 2990, 1139, 4638, 2140, 6586, 2692, 6224, 1469, 2456, 6379, 8024, 2769, 812, 833, 1222, 1213, 3121, 6822, 3680, 671, 702, 5301, 5688, 8024, 6375, 1920, 2157, 2428, 6814, 671, 702, 5401, 1962, 5445, 7410, 2563, 4638, 969, 3309, 511]
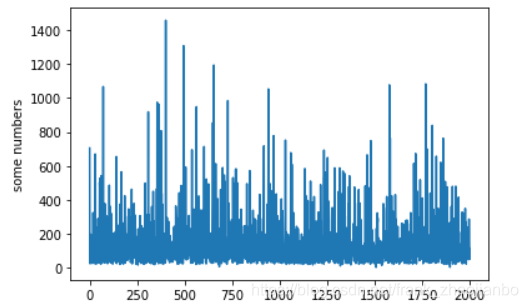
最长句子的长度为 2924
max_len = 0
lengthOfsentence = []
# 循环每一个句子...
for sent in sentences:
lengthOfsentence.append(len(sent))
# 找到句子最大长度
max_len = max(max_len, len(sent))
print('最长的句子长度为: ', max_len)
最长的句子长度为: 1459
根据观察,大多数句子长度在400 到600,实在是GPU内存太小,padding 时候的max_length 我们取256
import matplotlib.pyplot as plt
plt.plot(lengthOfsentence)
plt.ylabel('some numbers')
plt.show()
input_ids = []
attention_masks = []
for sent in sentences:
# `encode_plus` will:
# (1) Tokenize the sentence.
# (2) Prepend the `[CLS]` token to the start.
# (3) Append the `[SEP]` token to the end.
# (4) Map tokens to their IDs.
# (5) Pad or truncate the sentence to `max_length`
# (6) Create attention masks for [PAD] tokens.
encoded_dict = tokenizer.encode_plus(
sent, # Sentence to encode.
add_special_tokens = True, # Add '[CLS]' and '[SEP]'
max_length = 256, # Pad & truncate all sentences.
pad_to_max_length = True,
return_attention_mask = True, # Construct attn. masks.
return_tensors = 'pt', # Return pytorch tensors.
)
# 把编码的句子加入list.
input_ids.append(encoded_dict['input_ids'])
# 加上 attention mask (simply differentiates padding from non-padding).
attention_masks.append(encoded_dict['attention_mask'])
# 把lists 转为 tensors.
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)
简单查看一下第一句的Token IDs 和 attention_masks
print('原句: ', sentences[0])
print('Token IDs:', input_ids[0])
print('attention_masks:', attention_masks[0])
原句: 先说优点:装修是新的,房间很大,房间灯光、家具都不错,达到3星水平。山庄所处位置风景优美,整体布局设计体现了一定的水平。再说缺点:管理水平跟农村招待所差不多。一大早空调就没电了,原来是服务员在外面关了房间的开关,打电话之后服务员才把开关打开。早上9点不到,有客人退房,服务员持对讲机在楼道里用能吵醒整个楼层任何甜梦的声音在跟前台对讲,把整个山庄最可贵的宁静搅扰得荡然无存。最后是最要命的:温泉的水根本看不出是温泉,脏的简直就是山脚下湖里头抽上来的湖水。虽说可以随时调温,可是任你泡你看着那一池你专用的浑浊的温泉水,谅你也不敢泡久!宾馆反馈2006年12月29日:感谢您选择颐和温泉度假山庄,享受美好的假期。我们很重视您提的宝贵意见,同时做了相应的调查。关于房间空调电源一事是由于当天早上有一位客人在温泉区泡温泉的时候将路边的灯泡不小心打烂,造成电路湿水而自动断电保护的,这也是对客人安全的一个保障。酒店客房区内采用现代最新的电路技术,由电房总控制,所以在酒店房间及门口是没有电源开关设施的。酒店是不会,而且不允许任何人,在正常情况下关闭已有客人入住的房间的所有设施。颐和温泉度假山庄的温泉是属于极热型的氡温泉,氡温泉为无味,颜色相对淡黄,为了更好的配合按摩效果,我们在每个温泉池都采用浅棕色,浅黄色等的鹅卵石为铺垫,故此经过光线的折射会给客人“不干净”的错觉。您可以放心的使用,体会温泉带来的美好享受。服务员不正确使用对讲机的行为属于个别偶尔现象,当然,也是我们管理的一个疏忽,就该事情,我们已经对其进行相关教育。再次感谢您对我们提出的宝贵意见和建议,我们会努力改进每一个细节,让大家度过一个美好而难忘的假期。
Token IDs: tensor([ 101, 1044, 6432, 831, 4157, 8038, 6163, 934, 3221, 3173, 4638, 8024,
2791, 7313, 2523, 1920, 8024, 2791, 7313, 4128, 1045, 510, 2157, 1072,
6963, 679, 7231, 8024, 6809, 1168, 124, 3215, 3717, 2398, 511, 2255,
2411, 2792, 1905, 855, 5390, 7599, 3250, 831, 5401, 8024, 3146, 860,
2357, 2229, 6392, 6369, 860, 4385, 749, 671, 2137, 4638, 3717, 2398,
511, 1086, 6432, 5375, 4157, 8038, 5052, 4415, 3717, 2398, 6656, 1093,
3333, 2875, 2521, 2792, 2345, 679, 1914, 511, 671, 1920, 3193, 4958,
6444, 2218, 3766, 4510, 749, 8024, 1333, 3341, 3221, 3302, 1218, 1447,
1762, 1912, 7481, 1068, 749, 2791, 7313, 4638, 2458, 1068, 8024, 2802,
4510, 6413, 722, 1400, 3302, 1218, 1447, 2798, 2828, 2458, 1068, 2802,
2458, 511, 3193, 677, 130, 4157, 679, 1168, 8024, 3300, 2145, 782,
6842, 2791, 8024, 3302, 1218, 1447, 2898, 2190, 6382, 3322, 1762, 3517,
6887, 7027, 4500, 5543, 1427, 7008, 3146, 702, 3517, 2231, 818, 862,
4494, 3457, 4638, 1898, 7509, 1762, 6656, 1184, 1378, 2190, 6382, 8024,
2828, 3146, 702, 2255, 2411, 3297, 1377, 6586, 4638, 2123, 7474, 3009,
2817, 2533, 5782, 4197, 3187, 2100, 511, 3297, 1400, 3221, 3297, 6206,
1462, 4638, 8038, 3946, 3787, 4638, 3717, 3418, 3315, 4692, 679, 1139,
3221, 3946, 3787, 8024, 5552, 4638, 5042, 4684, 2218, 3221, 2255, 5558,
678, 3959, 7027, 1928, 2853, 677, 3341, 4638, 3959, 3717, 511, 6006,
6432, 1377, 809, 7390, 3198, 6444, 3946, 8024, 1377, 3221, 818, 872,
3796, 872, 4692, 4708, 6929, 671, 3737, 872, 683, 4500, 4638, 3847,
3843, 4638, 3946, 102])
attention_masks: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
设计 training,validation 和 test dataset
from torch.utils.data import TensorDataset, random_split
# 把input 放入 TensorDataset。
dataset = TensorDataset(input_ids, attention_masks, labels)
# 计算 train_size 和 val_size 的长度.
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# 90% 的dataset 为train_dataset, 10% 的的dataset 为val_dataset.
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('{:>5,} 训练数据'.format(train_size))
print('{:>5,} 验证数据'.format(val_size))
1,800 训练数据
200 验证数据
制作dataload
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# 推荐batch_size 为 16 或者 32
batch_size = 16
# 为训练数据集和验证数据集设计DataLoaders.
train_dataloader = DataLoader(
train_dataset, # 训练数据.
sampler = RandomSampler(train_dataset), # 打乱顺序
batch_size = batch_size
)
validation_dataloader = DataLoader(
val_dataset, # 验证数据.
sampler = RandomSampler(val_dataset), # 打乱顺序
batch_size = batch_size
)
导入 bert 文本多分类模型 BertForSequenceClassification
from transformers import BertForSequenceClassification, AdamW, BertConfig
model = BertForSequenceClassification.from_pretrained(
"bert-base-chinese", # 使用 12-layer 的 BERT 模型.
num_labels = 2, # 二分类任务的输出标签为 2个.
output_attentions = False, # 不返回 attentions weights.
output_hidden_states = False, # 不返回 all hidden-states.
)
model.cuda()
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
# Get all of the model's parameters as a list of tuples.
params = list(model.named_parameters())
print('The BERT model has {:} different named parameters.\n'.format(len(params)))
print('==== Embedding Layer ====\n')
for p in params[0:5]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== First Transformer ====\n')
for p in params[5:21]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
print('\n==== Output Layer ====\n')
for p in params[-4:]:
print("{:<55} {:>12}".format(p[0], str(tuple(p[1].size()))))
The BERT model has 201 different named parameters.
==== Embedding Layer ====
bert.embeddings.word_embeddings.weight (21128, 768)
bert.embeddings.position_embeddings.weight (512, 768)
bert.embeddings.token_type_embeddings.weight (2, 768)
bert.embeddings.LayerNorm.weight (768,)
bert.embeddings.LayerNorm.bias (768,)
==== First Transformer ====
bert.encoder.layer.0.attention.self.query.weight (768, 768)
bert.encoder.layer.0.attention.self.query.bias (768,)
bert.encoder.layer.0.attention.self.key.weight (768, 768)
bert.encoder.layer.0.attention.self.key.bias (768,)
bert.encoder.layer.0.attention.self.value.weight (768, 768)
bert.encoder.layer.0.attention.self.value.bias (768,)
bert.encoder.layer.0.attention.output.dense.weight (768, 768)
bert.encoder.layer.0.attention.output.dense.bias (768,)
bert.encoder.layer.0.attention.output.LayerNorm.weight (768,)
bert.encoder.layer.0.attention.output.LayerNorm.bias (768,)
bert.encoder.layer.0.intermediate.dense.weight (3072, 768)
bert.encoder.layer.0.intermediate.dense.bias (3072,)
bert.encoder.layer.0.output.dense.weight (768, 3072)
bert.encoder.layer.0.output.dense.bias (768,)
bert.encoder.layer.0.output.LayerNorm.weight (768,)
bert.encoder.layer.0.output.LayerNorm.bias (768,)
==== Output Layer ====
bert.pooler.dense.weight (768, 768)
bert.pooler.dense.bias (768,)
classifier.weight (2, 768)
classifier.bias (2,)
选择优化器
# AdamW 是一个 huggingface library 的类,'W' 是'Weight Decay fix"的意思。
optimizer = AdamW(model.parameters(),
lr = 2e-5, # args.learning_rate - 默认是 5e-5
eps = 1e-8 # args.adam_epsilon - 默认是 1e-8, 是为了防止衰减率分母除到0
)
设计learning rate scheduler, 调整learning rate.
from transformers import get_linear_schedule_with_warmup
# bert 推荐 epochs 在2到4之间为好。
epochs = 4
# training steps 的数量: [number of batches] x [number of epochs].
total_steps = len(train_dataloader) * epochs
# 设计 learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0, # Default value in run_glue.py
num_training_steps = total_steps)
flat_accuracy 计算模型准确率
import numpy as np
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
format_time 计算所用时间
import time
import datetime
def format_time(elapsed):
elapsed_rounded = int(round((elapsed)))
# 返回 hh:mm:ss 形式的时间
return str(datetime.timedelta(seconds=elapsed_rounded))
训练数据
import os
import random
import numpy as np
from transformers import WEIGHTS_NAME, CONFIG_NAME
output_dir = "./binary_models/"
output_model_file = os.path.join(output_dir, WEIGHTS_NAME)
output_config_file = os.path.join(output_dir, CONFIG_NAME)
# 代码参考 https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/examples/run_glue.py#L128
# 设置随机种子.
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
# 记录training ,validation loss ,validation accuracy and timings.
training_stats = []
# 设置总时间.
total_t0 = time.time()
best_val_accuracy = 0
for epoch_i in range(0, epochs):
print('Epoch {:} / {:}'.format(epoch_i + 1, epochs))
# 记录每个 epoch 所用的时间
t0 = time.time()
total_train_loss = 0
total_train_accuracy = 0
model.train()
for step, batch in enumerate(train_dataloader):
# 每隔40个batch 输出一下所用时间.
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# `batch` 包括3个 tensors:
# [0]: input ids
# [1]: attention masks
# [2]: labels
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 清空梯度
model.zero_grad()
# forward
# 参考 https://huggingface.co/transformers/v2.2.0/model_doc/bert.html#transformers.BertForSequenceClassification
loss, logits = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
total_train_loss += loss.item()
# backward 更新 gradients.
loss.backward()
# 减去大于1 的梯度,将其设为 1.0, 以防梯度爆炸.
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 更新模型参数
optimizer.step()
# 更新 learning rate.
scheduler.step()
logit = logits.detach().cpu().numpy()
label_id = b_labels.to('cpu').numpy()
# 计算training 句子的准确度.
total_train_accuracy += flat_accuracy(logit, label_id)
# 计算batches的平均损失.
avg_train_loss = total_train_loss / len(train_dataloader)
# 计算训练时间.
training_time = format_time(time.time() - t0)
# 训练集的准确率.
avg_train_accuracy = total_train_accuracy / len(train_dataloader)
print(" 训练准确率: {0:.2f}".format(avg_train_accuracy))
print(" 平均训练损失 loss: {0:.2f}".format(avg_train_loss))
print(" 训练时间: {:}".format(training_time))
# ========================================
# Validation
# ========================================
t0 = time.time()
# 设置 model 为valuation 状态,在valuation状态 dropout layers 的dropout rate会不同
model.eval()
# 设置参数
total_eval_accuracy = 0
total_eval_loss = 0
nb_eval_steps = 0
for batch in validation_dataloader:
# `batch` 包括3个 tensors:
# [0]: input ids
# [1]: attention masks
# [2]: labels
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 在valuation 状态,不更新权值,不改变计算图
with torch.no_grad():
# 参考 https://huggingface.co/transformers/v2.2.0/model_doc/bert.html#transformers.BertForSequenceClassification
(loss, logits) = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
# 计算 validation loss.
total_eval_loss += loss.item()
logit = logits.detach().cpu().numpy()
label_id = b_labels.to('cpu').numpy()
# 计算 validation 句子的准确度.
total_eval_accuracy += flat_accuracy(logit, label_id)
# 计算 validation 的准确率.
avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
print("")
print(" 测试准确率: {0:.2f}".format(avg_val_accuracy))
if avg_val_accuracy > best_val_accuracy:
best_val_accuracy = avg_val_accuracy
torch.save(model.state_dict(),output_model_file)
model.config.to_json_file(output_config_file)
tokenizer.save_vocabulary(output_dir)
# 计算batches的平均损失.
avg_val_loss = total_eval_loss / len(validation_dataloader)
# 计算validation 时间.
validation_time = format_time(time.time() - t0)
print(" 平均测试损失 Loss: {0:.2f}".format(avg_val_loss))
print(" 测试时间: {:}".format(validation_time))
# 记录模型参数
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Valid. Accur.': avg_val_accuracy,
'Training Time': training_time,
'Validation Time': validation_time
}
)
print("训练一共用了 {:} (h:mm:ss)".format(format_time(time.time()-total_t0)))
Epoch 1 / 4
Batch 40 of 113. Elapsed: 0:00:30.
Batch 80 of 113. Elapsed: 0:01:01.
训练准确率: 0.84
平均训练损失 loss: 0.38
训练时间: 0:01:25
测试准确率: 0.84
平均测试损失 Loss: 0.35
测试时间: 0:00:04
Epoch 2 / 4
Batch 40 of 113. Elapsed: 0:00:30.
Batch 80 of 113. Elapsed: 0:01:01.
训练准确率: 0.93
平均训练损失 loss: 0.20
训练时间: 0:01:26
测试准确率: 0.87
平均测试损失 Loss: 0.44
测试时间: 0:00:04
Epoch 3 / 4
Batch 40 of 113. Elapsed: 0:00:30.
Batch 80 of 113. Elapsed: 0:01:00.
训练准确率: 0.96
平均训练损失 loss: 0.14
训练时间: 0:01:25
测试准确率: 0.85
平均测试损失 Loss: 0.67
测试时间: 0:00:03
Epoch 4 / 4
Batch 40 of 113. Elapsed: 0:00:30.
Batch 80 of 113. Elapsed: 0:01:00.
训练准确率: 0.98
平均训练损失 loss: 0.08
训练时间: 0:01:25
测试准确率: 0.85
平均测试损失 Loss: 0.71
测试时间: 0:00:03
训练一共用了 0:05:53 (h:mm:ss)
简单测试一下
(_, logits) = model(input_ids[-20:].to(device),
token_type_ids=None,
attention_mask=attention_masks[-20:].to(device),
labels=labels[-20:].to(device))
logits = logits.detach().cpu().numpy()
label_ids = labels[-20:].to('cpu').numpy()
acc = flat_accuracy(logits, label_ids)
acc
1.0
pred_flat = np.argmax(logits, axis=1).flatten()
pred_flat
array([0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0],
dtype=int64)
label_ids
array([0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0],
dtype=int64)
Batch 40 of 113. Elapsed: 0:00:30.
Batch 80 of 113. Elapsed: 0:01:00.
训练准确率: 0.98
平均训练损失 loss: 0.08
训练时间: 0:01:25
测试准确率: 0.85
平均测试损失 Loss: 0.71
测试时间: 0:00:03
训练一共用了 0:05:53 (h:mm:ss)
简单测试一下
(_, logits) = model(input_ids[-20:].to(device),
token_type_ids=None,
attention_mask=attention_masks[-20:].to(device),
labels=labels[-20:].to(device))
logits = logits.detach().cpu().numpy()
label_ids = labels[-20:].to('cpu').numpy()
acc = flat_accuracy(logits, label_ids)
acc
1.0
pred_flat = np.argmax(logits, axis=1).flatten()
pred_flat
array([0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0],
dtype=int64)
label_ids
array([0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0],
dtype=int64)

















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









