






作者处于新手修炼期,在今天学习pandas遇到了点小问题给大家分享一下
今天在学习cov和corr求协方差和相关性函数时查询相关函数资料,资料上说cov函数以及corr函数会忽略非数字的列,但是在实操TiTans训练数据时发现并不会忽略含有字符串的那一列数据,结果导致代码进行了报错
数据来源
kaggle入门竞赛Titans
下面是参考的网页资料
开始代码如下
df = pd.read_csv('C:\\Users\\24242\\Desktop\\AI_Reference\\data_bag\\titanic\\train.csv')
df.cov()
Titans训练集含有的数据如下图所示
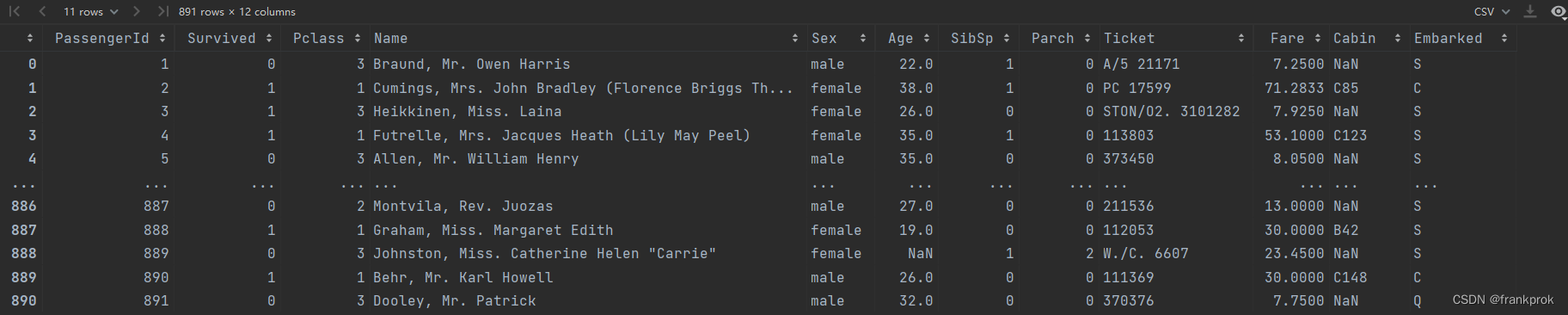
发现cov函数无法对Name列进行协方差的求解,同时也并不会忽略Name这一列以及图中其他非数字的列
代码报错情况如下


解决方案如下
由于字符串无法参加计算,会导致程序报错,所以我们更加希望忽略包含字符串的列
使用DataFrame的select_dtypes方式选择只包含数值类型的类(include或者用exclude),然后再计算协同方差和相关性
numeric_columns = df.select_dtypes(include=['int','float']).columns
cov_true = df[numeric_columns].cov()
corr_true = df[numeric_columns].corr()
corr_trueinclude传入一个列表,包含需要进行计算的类型(此处我选择了只int和float类型)
下面是运行结果
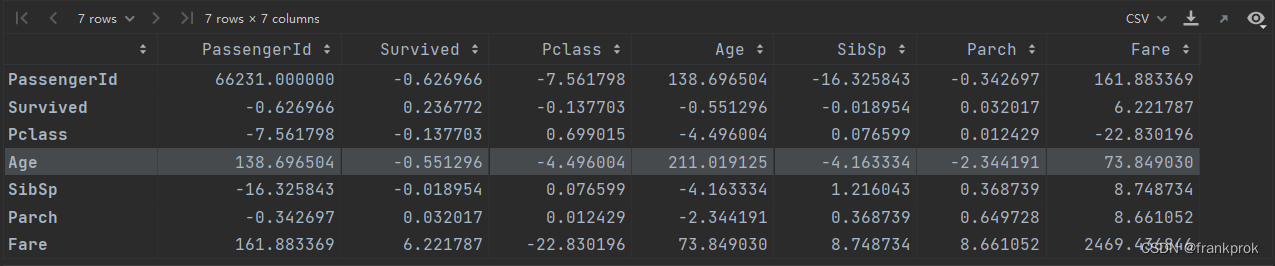
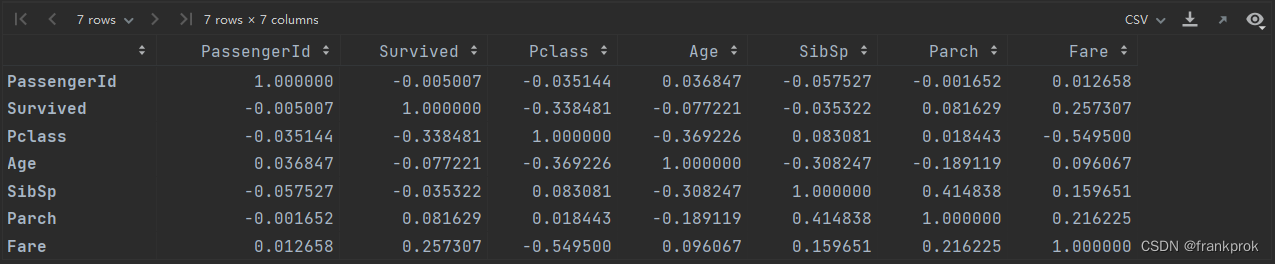
运行成功,问题基本得到了解决,但是没有包含Ticket字段。
不足的是并不知道为什么cov和corr为什么不能忽略非数字的列,作者猜测可能是因为版本问题,希望大佬们能给出一些建议。
再次更新于2023年11月30日星期四。
感谢网友的答疑,可是试试一下解决方案:
pandas2.0版本后,原来corr函数自动忽略字符串等非浮点数的特性被修改了,可以用.corr(method='pearson',numeric_only=True)忽略字符串。














 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









