







一、引言
这是本人花一天时间复现出来的pytorch版本的EEG-Inception,由于pytorch卷积对通道选定的问题,有些部分代码可能和原论文不一样,稍后会说, 如本文有不妥之处,欢迎指出。
请注意:本文章所分享的代码只供参考。
原论文代码请去《EEG-Inception: A Novel Deep Convolutional Neural Network for Assistive ERP-Based Brain-Computer Interfaces》作者github开源代码上自取。
本篇文章不讲解论文,至给出实现代码,EEG-Inception论文讲解推荐博主:
 https://blog.csdn.net/mantoudamahou/article/details/137679180?spm=1001.2014.3001.5502
https://blog.csdn.net/mantoudamahou/article/details/137679180?spm=1001.2014.3001.5502本次pytorch代码已上传至本人的github上,需要请自取:
二、模型代码
我们直接上代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class DepthwiseSeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0):
super(DepthwiseSeparableConv2d, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=kernel_size, padding='valid', groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
# 进行通道压缩
return x
class EEGInception(nn.Module):
def __init__(self, input_time=1000, fs=128, ncha=8, filters_per_branch=8,
scales_time=(500, 250, 125), dropout_rate=0.25,
activation='relu', n_classes=2):
super(EEGInception, self).__init__()
# ============================= CALCULATIONS ============================= #
input_samples = int(input_time * fs / 1000)
scales_samples = [int(s * fs / 1000) for s in scales_time]
# ================================ INPUT ================================= #
self.input_layer = nn.Conv2d(1, ncha, kernel_size=(1, 1))
# ========================== BLOCK 1: INCEPTION ========================== #
b1_units = []
for i in range(len(scales_samples)):
unit = nn.Sequential(
nn.Conv2d(ncha, ncha, kernel_size=(1, scales_samples[i]), padding='same'),
nn.BatchNorm2d(ncha),
nn.ELU(inplace=True),
DepthwiseSeparableConv2d(ncha, ncha*2, kernel_size=(ncha, 1)),
nn.BatchNorm2d(ncha*2),
nn.ELU(inplace=True),
nn.Dropout(dropout_rate)
)
b1_units.append(unit)
self.b1_units = nn.ModuleList(b1_units)
# ========================== BLOCK 2: INCEPTION ========================== #
b2_units = []
for i in range(len(scales_samples)):
unit = nn.Sequential(
nn.Conv2d(filters_per_branch*6, filters_per_branch, kernel_size=(int(scales_samples[i]/4), 1), padding='same', padding_mode='zeros'),
nn.BatchNorm2d(filters_per_branch),
nn.ELU(inplace=True),
nn.Dropout(dropout_rate)
)
b2_units.append(unit)
self.b2_units = nn.ModuleList(b2_units)
# ============================ BLOCK 3: OUTPUT =========================== #
self.b3_u1 = nn.Sequential(
nn.Conv2d(filters_per_branch * len(scales_samples), int(filters_per_branch*len(scales_samples)/2), kernel_size=(8, 1),padding='same'),
nn.BatchNorm2d(int(filters_per_branch*len(scales_samples)/2)),
nn.ELU(inplace=True),
nn.AvgPool2d((2, 1)),
nn.Dropout(dropout_rate)
)
self.b3_u2 = nn.Sequential(
nn.Conv2d(int(filters_per_branch*len(scales_samples)/2), int(filters_per_branch*len(scales_samples)/4), kernel_size=(4, 1),padding='same'),
nn.BatchNorm2d(int(filters_per_branch*len(scales_samples)/4)),
nn.ELU(inplace=True),
nn.AvgPool2d((2, 1)),
nn.Dropout(dropout_rate)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(int(filters_per_branch*len(scales_samples)/4), n_classes)
def forward(self, x):
# ================================ INPUT ================================= #
x = self.input_layer(x)
# ========================== BLOCK 1: INCEPTION ========================== #
b1_outputs = [unit(x) for unit in self.b1_units]
b1_out = torch.cat(b1_outputs, dim=1)
b1_out = b1_out.permute((0, 1, 3, 2))
b1_out = F.avg_pool2d(b1_out, (4, 1))
# b1_out = b1_out.permute((0, 2, 1, 3))
# ========================== BLOCK 2: INCEPTION ========================== #
b2_outputs = [unit(b1_out) for unit in self.b2_units]
b2_out = torch.cat(b2_outputs, dim=1)
b2_out = F.avg_pool2d(b2_out, (2, 1))
# ============================ BLOCK 3: OUTPUT =========================== #
b3_u1_out = F.avg_pool2d(F.elu(self.b3_u1(b2_out)), (2, 1))
b3_u2_out = F.avg_pool2d(F.elu(self.b3_u2(b3_u1_out)), (2, 1))
b3_out = self.avgpool(b3_u2_out)
b3_out = b3_out.view(b3_out.size(0), -1)
output = self.fc(b3_out)
return output
if __name__ == '__main__':
data = torch.randn(1, 1, 8, 128).to('cuda')
model = EEGInception().to('cuda')
output = model(data)
sum_parameter = 0
for param in model.parameters():
sum_parameter += param.numel()
print(sum_parameter)
summary(model, (1, 8, 128), device='cuda', batch_size=48)讲到与原论文不同的是三个block的卷积核都不一样,因为我们输入的shape和原论文不一样,我们的输入的shape为标准的(batch_size, 1, channel, sample),是常用的EEGNet论文的输入,原论文输入请翻阅论文,可将代码与原论文进行对比。
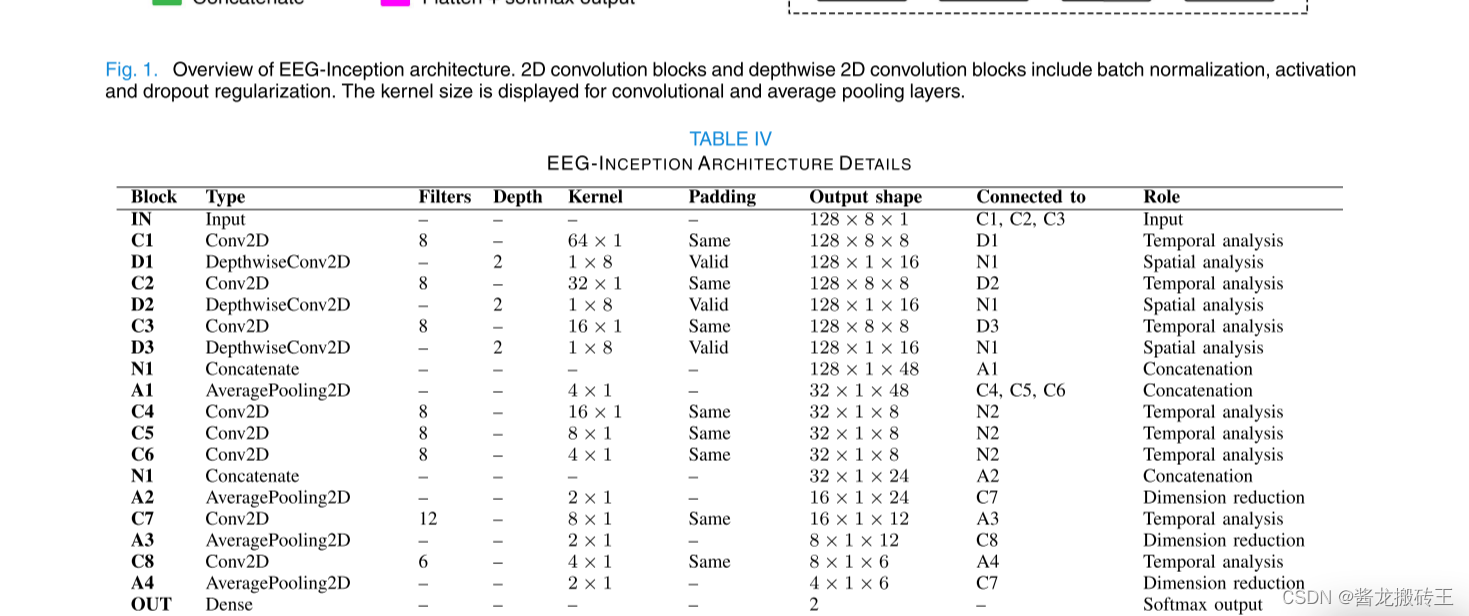
上面是原论文中各层的详细说明,原论文中的参数是15154,本篇文章的代码参数21484,因为block2中的通道数比原论文中较多的原因导致,大家可以参考代码继续修改模型。
三、总结
因时间原因,本模型只用CompetitionIVdataset2a数据集中的A01受试者进行测试,大家可以多用几个受试者对模型进行测试,并进行将近4倍的数据增强,便于模型捕获特征,进行了5-fold cross-validation,训练集与测试集划分为8:2,ave_acc在90%左右。如果本篇文章有任何错误之处,欢迎评论区指出。

















 2212
2212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









