









很多情况下我们需要从数据对象集合中快速而准确地找出与给定数据相似的那些数据对象,这一过程我们称之为相似性搜索。
传统的相似性搜索算法大多是分支界限算法,创建的索引结构一般表现为树形。当数据的维度提高时,算法的复杂度呈指数级上升,算法性能会急剧下降。
数据之间的相似性需要通过某种相似性度量方法进行度量,常用的几种相似性度量方法例如余弦相似度、海明距离。
位置敏感哈希是近似最近邻搜索算法,是一种概率型算法。对于查询点q,给定查询距离阈值r以及一个概率值成功概率δ,查询会以不小于的δ概率返回与q距离小于等于r的点:
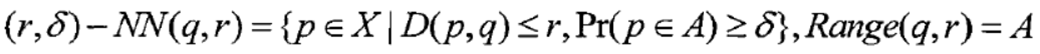
LSH要花费十分巨大的内存容量用于创建索引结构,通常会大到消耗掉所有可用内存。因此在LSH的基础上提出FBLSH,以优化时间、空间。
基本思想如下:
对数据集中的点进行哈希,使得距离近的点冲突的概率远大于距离远的点冲突的概率。在查询时,将查询点按照相同的哈希函数哈希到桶中,然后取出桶中的所有点作为候选近似最近邻点,最后计算查询点与每个候选近似最近邻点的距离,通过该距离判断是否符合查询条件。
距离近的点冲突的概率越大,同时距离远的点冲突的概率越小,的查询质量和查询效率也就会越高。

通用LSH索引创建算法:
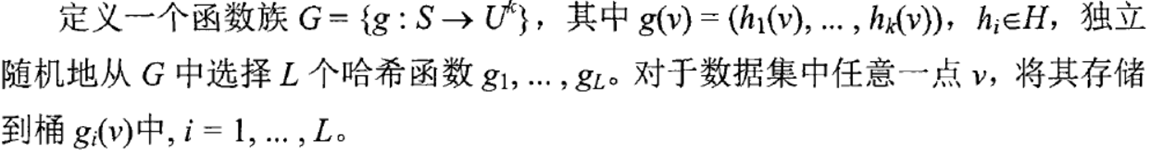
通用LSH搜索算法:

LSH本身依然存在不少问题,比如为了获得较好的查询效果,需要大量的哈希表,进而消耗大量的内存空间;此外,哈希函数的选择采用的是随机方式,并没有根据数据的分布选取更加适合的函数。















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









