







一、基础学习creating, reading and writing
1. Creating
pandas有两个主要的对象:DataFrame和Series.
DataFrame:
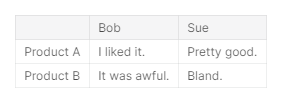
import pandas as pd
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
#行标签即为Index。如果不赋值默认为0,1,2,3,4
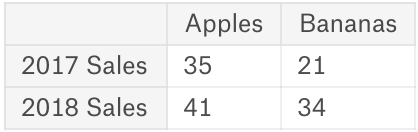
或者:
fruit_sales = pd.DataFrame([[35, 21], [41, 34]],
columns=['Apples', 'Bananas'],
index=['2017 Sales', '2018 Sales'])
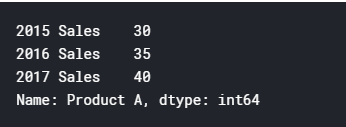
Series:
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'],
name='Product A')
#series是没有列名的,只有name
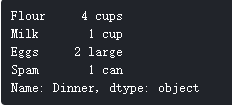
或者:
quantities = ['4 cups', '1 cup', '2 large', '1 can']
items = ['Flour', 'Milk', 'Eggs', 'Spam']
recipe = pd.Series(quantities, index=items, name='Dinner')
2. 读取
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv",
index_col=0)
#index_col=0意思是不额外创建一个index作为索引,而直接使用文本中内置的index
wine_reviews.head()
wine_reviews.shape
3.写入
animals = pd.DataFrame({'Cows': [12, 20], 'Goats': [22, 19]},
index=['Year 1', 'Year 2'])
animals.to_csv("cows_and_goats.csv")
二、索引和选择
1.python的索引操作符
python中的索引操作符是[ ]。python的索引有两种方式:
reviews.country #选取country这一列进行输出
reviews['country']
一般使用第二种方法。
2.panda中的索引
panda中的索引有两个操作符:loc 和 iloc
跟python的操作符不同的是:panda的操作符是行在前,列在后(row-first, column-second)。而python的是列在前,行在后。
2.1 index-based selection—iloc
iloc可以根据其数字位置进行索引:
第一行:reviews.iloc[0]
第一列:reviews.iloc[:, 0]
数据的最后五个元素:reviews.iloc[-5:]
2.2 Label-based selection——loc
loc根据其index值来进行索引:
第一个条目:reviews.loc[0, 'country']
指定三个列:reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
2.3 二者的区别
iloc[0:10]是不包含10的,而loc[0:10]包含10。
3.一些其他的用法
3.1 增加index
使用reviews.set_index("title")可以为数据集增加一个名为title的index。
3.2 条件选择
使用reviews.loc[reviews.country == 'Italy']可以筛选出符合条件的所有数据。
使用reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]可以筛选出同时符合两个条件的数据。(还有|表示或的关系)
更简单的,Pandas有两个内置的条件操作符:isin和isnull。
reviews.loc[reviews.country.isin(['Italy', 'France'])]#表示意大利或者法国
reviews.loc[reviews.price.isnull()]#筛选出空值
三、分析与映射
3.1 summary functions
描述一个dataframe的基本属性:reviews.points.describe()
一个column的平均值:reviews.points.mean()
一个column的所有取值:reviews.taster_name.unique()
一个column中所有值出现的次数:reviews.taster_name.value_counts()
3.2 Maps
比如将均值归一化,有两种函数:
- map():
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
- apply():
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')
- 或者直接使用运算符号:
review_points_mean = reviews.points.mean()
reviews.points - review_points_mean
**注意:以上三种方法均不改变原数值。
四、数据类型以及缺失值
4.1 Data types
reviews.dtypes#输出整个数据集每个column的类型
reviews.price.dtype#输出price这个column的类型
reviews.points.astype('float64')#将points的类型强制转化为float型
4.2 Missing values
reviews[pd.isnull(reviews.country)]#输出country中为空值的行
reviews.region_2.fillna("Unknown")#将region_2中NaN填充为Unknown
五、重命名和组合
5.1 Renaming
reviews.rename(columns={'points': 'score'})#将points这一列的列名重新命名
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})#将第一和第二行的行名重新命名
##################################或者使用另一种方法
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
5.2 Combining
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
##################################################################
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')















 3620
3620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









