







文章目录
1 - Creating, Reading and Writing
import pandas as pd
Creating data(创建数据)
pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])
pd.Series([1, 2, 3, 4, 5])
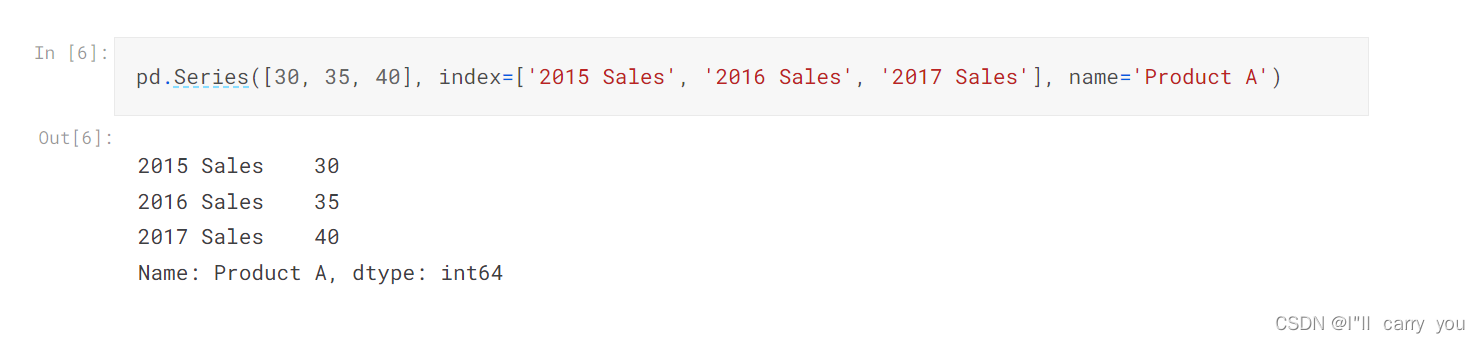
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')

Reading data files (读取数据)
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")
wine_reviews.shape
wine_reviews.head()
2- Indexing, Selecting & Assigning
reviews
reviews.country # 某一列
reviews['country']
reviews['country'][0]
索引:都是行优先
iloc : i 表示index
reviews.iloc[0] # 第0行
reviews.iloc[:, 0] # 第0列
reviews.iloc[:3, 0] # 前3行的 第0列
reviews.iloc[[0, 1, 2], 0] # 数组索引
reviews.iloc[-5:] # 支持负数索引
loc: 索引 值
reviews.loc[0, 'country'] # 第0行,country列
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']] # 所有行,[]这些列
设置索引
reviews.set_index("title")
条件选择
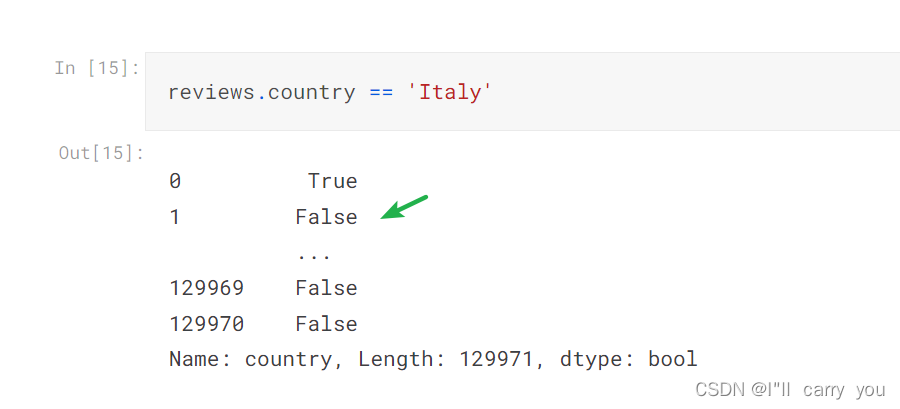
reviews.country == 'Italy'
reviews.loc[reviews.country == 'Italy'] # 选择country == 'Italy' 的 数据
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]
reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]
reviews.loc[reviews.country.isin(['Italy', 'France'])]
reviews.loc[reviews.price.notnull()]
3- Summary Functions and Maps
Summary functions
reviews.points.describe()
reviews.points.mean()
reviews.taster_name.unique()
reviews.taster_name.value_counts()
Maps
review_points_mean = reviews.points.mean()
reviews.points.map(lambda p: p - review_points_mean)
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')
review_points_mean = reviews.points.mean()
reviews.points - review_points_mean
reviews.country + " - " + reviews.region_1
Exercise: Summary Functions and Maps
median_points = reviews.points.median()
countries = reviews.country.unique()
reviews_per_country = reviews.country.value_counts()
centered_price = reviews.price - reviews.price.mean()
bargain_idx = (reviews.points / reviews.price).idxmax()
bargain_wine = reviews.loc[bargain_idx, 'title']
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()
n_fruity = reviews.description.map(lambda desc: "fruity" in desc).sum()
descriptor_counts = pd.Series([n_trop, n_fruity], index=['tropical', 'fruity'])
def stars(row):
if row.country == 'Canada':
return 3
elif row.points >= 95:
return 3
elif row.points >= 85:
return 2
else:
return 1
star_ratings = reviews.apply(stars, axis='columns')
5 - Exercise: Data Types and Missing Values
读取数据
index_col 在默认为None的时候,pandas会自动将第一列作为索引,并额外添加一列。所以大多我们会使用index_col=0,直接将第一列作为索引,不额外添加列。
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0) # 读取数据
reviews.head()
查看数据类型
# Your code here
dtype = reviews.points.dtype
print(dtype)
print(reviews.dtypes) # 所有数据
转 数据类型
point_strings = reviews.points.astype(str)
统计 缺失数量
n_missing_prices = reviews.price.isnull().sum() # 某一列
print(reviews.price.isnull())
reviews.isnull().sum() # 每一列
填充某一列缺失值 为Unknown, 并统计每类数量降序排序
reviews_per_region = reviews.region_1.fillna('Unknown').value_counts().sort_values(ascending=False)
print(reviews_per_region)
6 - Renaming and Combining
reviews.rename(columns={'points': 'score'}) # 将points列索引修改为 score
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'}) # 将0,1行索引 修改
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')
Exercise: Renaming and Combining
renamed = reviews.rename(columns=dict(region_1='region', region_2='locale')) # 修改列索引
reindexed = reviews.rename_axis('wines', axis='rows') # ?
combined_products = pd.concat([gaming_products, movie_products])
powerlifting_combined = powerlifting_meets.set_index("MeetID").join(powerlifting_competitors.set_index("MeetID"))
















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









