






十六、生成网络
说明:本部分内容也是参考北京邮电大学鲁鹏老师的课程,而鲁鹏老师的课件又是参考的斯坦福大学CS231N以及台湾大学机器学习课件。感谢、致敬这些老师们……
(一)相关概念和原理
1、无监督学习
无监督学习就是训练数据没有标签,也就是前面我们一直说的标答。我们前面学习的模型都是有监督学习,就是模型在训练的时候一定是要有标签的。因为没标签你就没法计算损失,没有损失就没法反向计算梯度,就没法训练模型了,所以一定得要标签才能训练的模型都是有监督学习。但是还有一些算法是无监督的。比如,生成模型就是一种无监督学习模型,还比如机器学习中的聚类算法、降维算法等也都是无监督学习模型。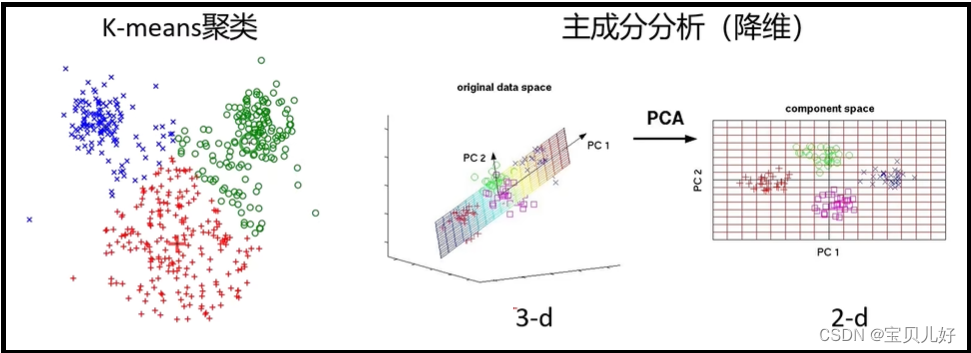
上图的两种算法就是机器学习算法。机器学习算法我的博客中也上传有几个算法,比如https://blog.csdn.net/friday1203/article/details/136643577?spm=1001.2014.3001.5501 这个就是聚类算法中的其中一个,感兴趣的可以看看。机器学习算法和深度学习算法是有本质上的不同的,个人认为机器学习算法更难一些,也更精巧一些,都是人类智慧的精华,非常巧妙,当然其中牵扯到的数学就比深度学习上难得多。
2、生成模型
什么是生成模型?就是给定训练集,产生与训练集同分布的新样本:
意思就是要先学习训练数据中的样本的分布,然后在这个分布中随机采样出一个点,通过这个点就可以生成我们想要的、可以以假乱真的假样本。这就是生成模型做的事情。
而如何学习训练数据中的样本的分布?这就是一个概率密度估计问题了。 如果我们能准确的写出训练样本的分布函数,就是显式密度估计。意思就是我这个训练数据集中的样本分布是可以用数学公式显示地表示出来,这样我就可以准确的知道某个点生产哪种图像的概率有多大了。意思就是我可以定量的计算出一个点生成一张猫的概率是90%,而生成一张狗图的概率是5%,生成一张牛的概率是2%等等。
但是现实情况是,我们一般很难显式地写出一个,比如有10万张图片样本的分布函数!所以我们一般让模型去学习这10万张图片的概率密度,此时就是隐式密度估计。隐式密度估计是说,模型model学习到的样本分布,我们人类是不知道的,不知道它的显式数学表达式的,但模型会大概率给你生成你想要的样本。比如你训练model的时候,输入1就对应的是猫,输入2对应的就是狗,,等等,所以当model训练完毕后,人类是不知道model学了啥分布的,但也会生成人类想要的(就是我想要狗你别给我生成一张猫)以假乱真的图片。
3、生成网络分类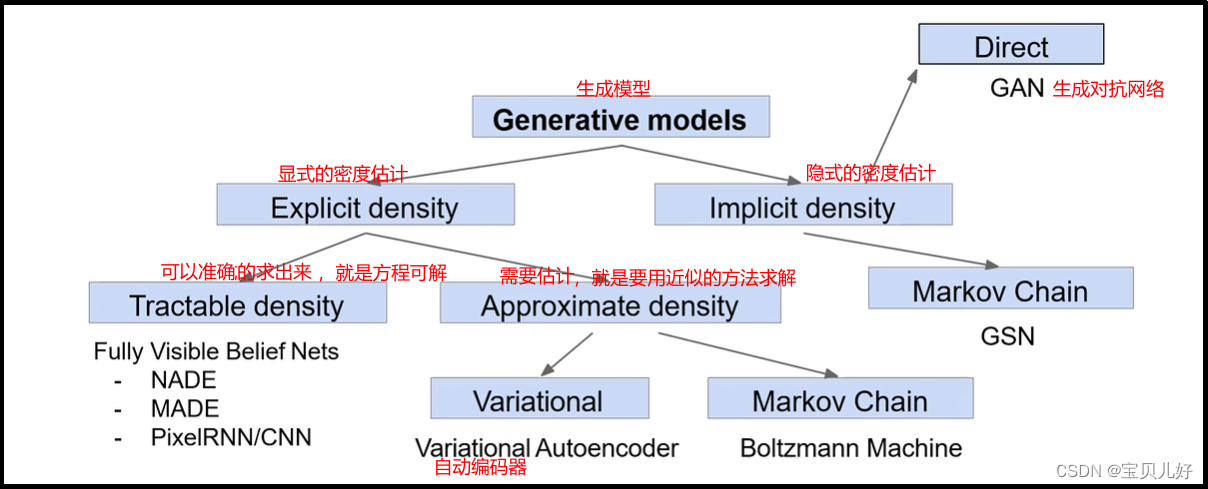
所以,生成模型中的经典网络是:
PixelRNN and PixelCNN,密度函数是确定的,是可解的
Variational Autoencoders(VAE),密度函数能定义出来,但不可解
Generative Adversarial Networks(GAN),也许这个网络学到了样本的密度函数,但我们人类从模型中得不到……也许网络压根就没学密度函数,anyway……
本部分重点讲解这三个架构。
4、生成模型的应用
(二)PixelRNN 与 PixelCNN
PixelRNN和PixelCNN又称显式的密度模型:
所以上图的公式就是最大概率的表示我这批样本图像各个像素点之间的条件概率。但这个公式我们是手写不出来的,所以我们要用神经网络来拟合这个公式,就是要训练一个神经网络,让这个网络去最大化的拟合这个公式。
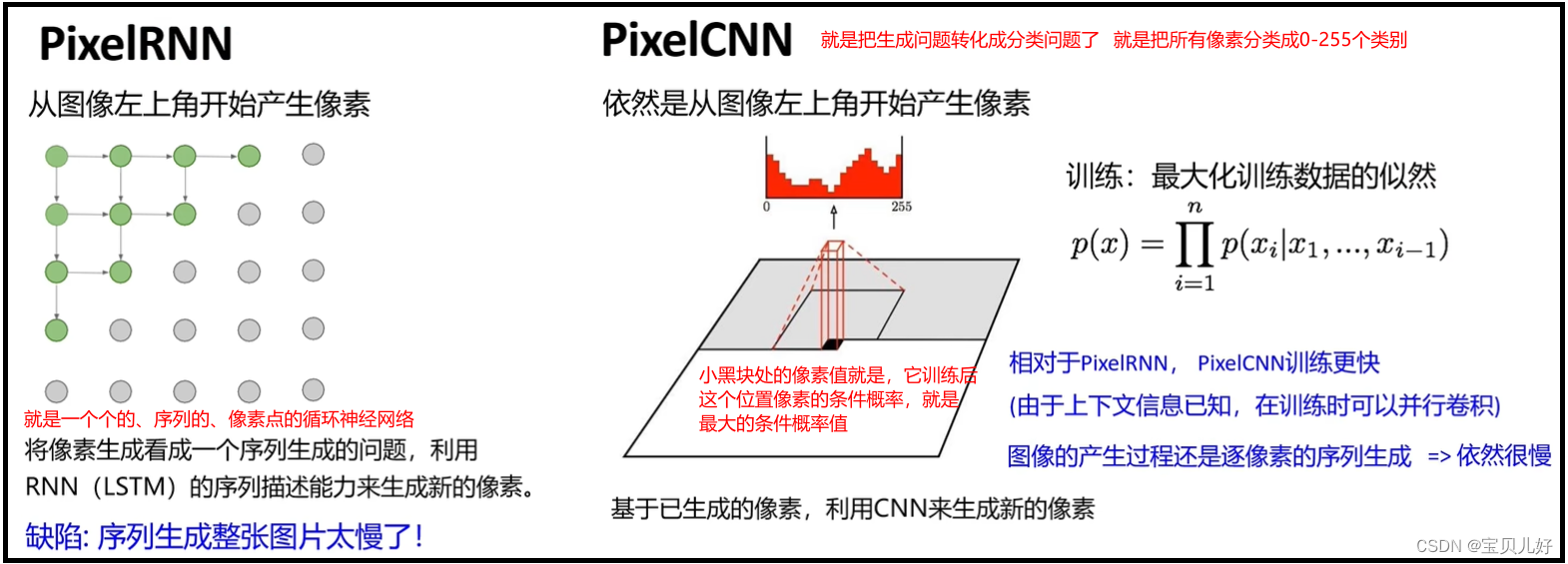
PixelRNN和PixelCNN的似然函数都可以精确计算;我们也可以利用似然函数的值有效地评估模型性能。但缺点就是:这两个模型都是逐个像素点进行预测地,速度慢,不适合生成大图像。
(三)VAE,variational autoencoders, 变分自编码模型
在图像生成领域,除了生成对抗网络外,另一个主流方向就是自动编码器家族Autoencoders了,其中,变分自动编码器Variational Autoencoders, VAE最为著名。 既然VAE是诞生于从自动编码器,那我们先从自动编码器聊起:
1、自动编码器(auto encoder, AE)
自动编码器有的地方也称“自编码器”。自编码器产生的背景又是为了实现各种目的的“数据表示”(Data Representation),就是使用另一种形式呈现原始数据的学习(representation learning)。比如我们想给数据降维。那要降维,肯定是原始数据维度太大,我希望有一个小维度的数据来表示这个大数据。那这个小数据在数值和维度上肯定不等于原始的大数据,但这个小数据携带了大数据的重点特征,那这个小数据就可以表示那个大数据。我就可以把这个小数据送入算法训练,不是就可以在不损失或少损失的基础上,大大提高了训练效率么?节省了计算资源么?
再比如,图像压缩技术。比如谷歌云盘的轻量存储,当我们将图像上传到云盘时,编码器会瞬间对图像进行压缩,并只保存原始图像1/4的像素量,当我们在本地获取云盘图像时,解码器又会瞬间将图像还原成原来的像素量,以此来节约云盘的存储空间。相似的技术还可以用于查看原图功能。当我们在社交软件上收到图像时,用户只会收到经过编码器压缩后的1/8或者1/10的缩略图,只有当用户要求查看原图时,才会使用解码器将图像复原。
下图是自编码器的架构图: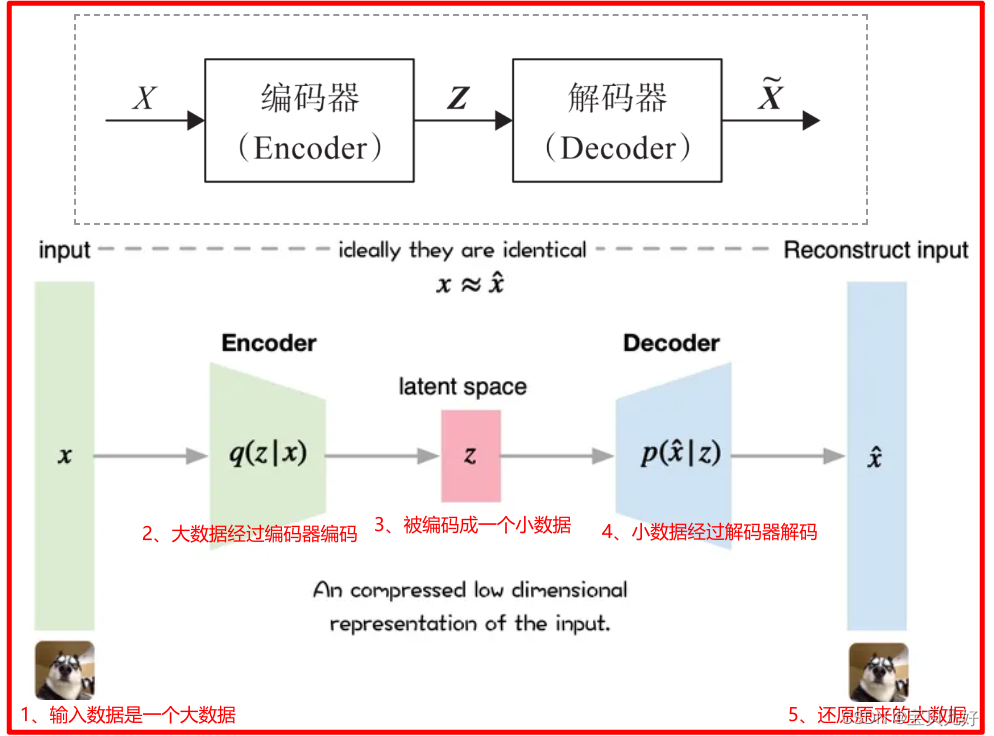
当上图的架构训练完毕后,我就可以扔掉编码器,只要解码器。当我给解码器输入一个在数A,解码器就可以帮我生成一张狗1的图像了;当我给解码器输入一个数B,解码器就帮我生成一张狗2的图像了:
此时的AE根本就称不上是一个生成模型!因为我必须要输入A或者输入B,才能生成狗1或者狗2。即使我们训练100万张狗,也只是确定的这100万个数字,只能生成对应的100万只狗!也就是latent space永远是一个有限的、离散的空间。假如我们给解码器输入C,而C不在latent space上,此时我们会发现解码器给我们返回的图片不仅模糊而且还是乱码的。呜呜呜。。。 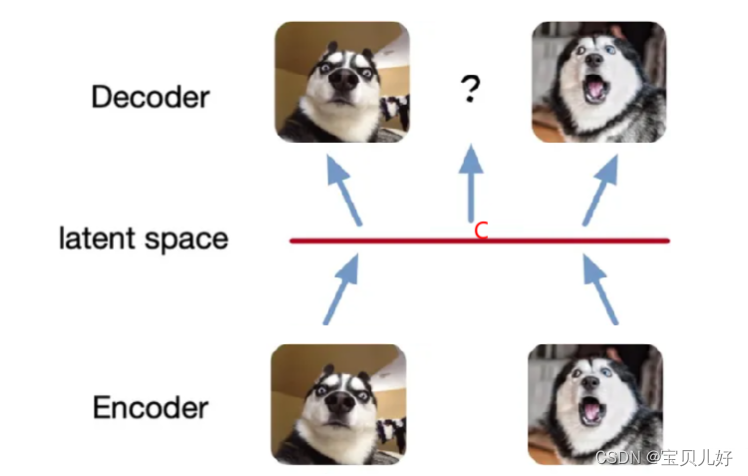
我要生成一张图片,只能在这个有限的离散空间选点,并且也只能生成对应的图片!这不是真正意义上的生成模型!
我期望的生成模型应该是我输入C点能给我生成一张既像狗1又像狗2的狗图啊。或者我输入一个任意的随机数,解码器能给我生成一只狗,至于这只狗长啥样,anyway,我不care了,反正都是狗就可以了。这才是真正的生成模型!
于是,人们转向研究如何让latent space变成一个连续的、无限的空间。这样我在这个空间里任意选一个数输入解码器,就可以生成一张狗图了。也于是,自编码器开启了各种各样的变异和变种,形成了自编码器一族!其中有些架构越来越像生成模型了,以至于今天在生成领域,自动编码器是可以和GAN分庭抗礼的一族。GAN和AE在原理上完全不一样,后面针对GAN我会单独写一个章节。
2、自编码器家族介绍
也就是自编码器的变异历程。但是不管自编码器如何变异,它变异的方向都是朝着:如何让latent space更连续、更无限。。。
(1)变异1:给输入图像引入噪声
这样就可以扩大图片的编码区域,从而能够覆盖到失真的空白编码区。其实说白了就是通过增加输入的多样性从而增强输出的鲁棒性。当给输入图片进行编码之前引入一点噪声,那么就可以让每张图片的编码空间出现在绿色箭头范围内,这样一来所得到的 latent space 就能覆盖到更多的编码范围。此时再从中间点抽取去还原便可以得到一个比较理想的输出啦: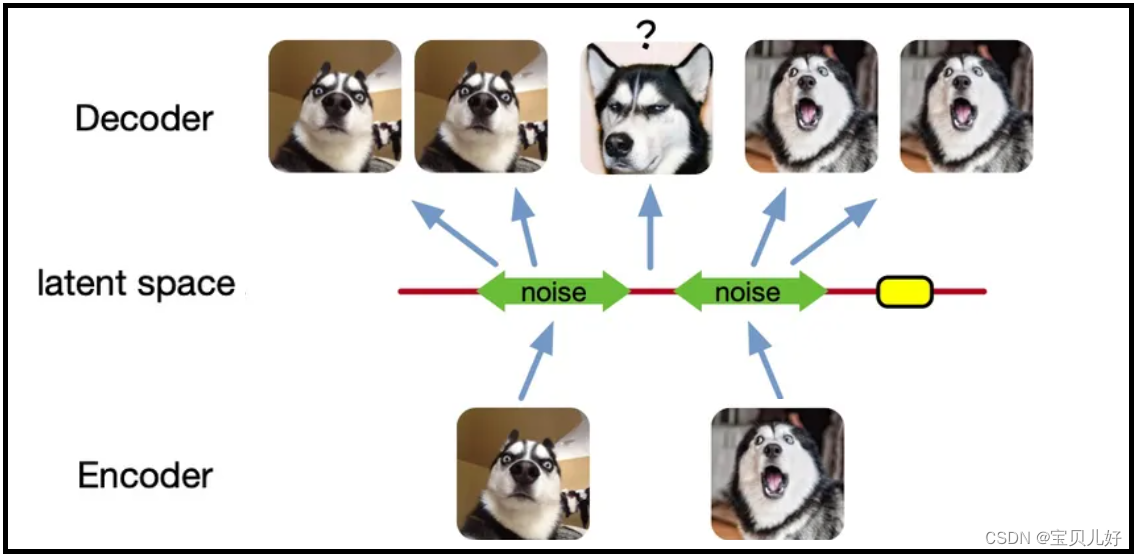
虽然在AE的基础上为输入数据增添了一些噪声使得 latent space 能够覆盖到比较多的区域,但是还是有不少地方没有被覆盖到,比如上图右边黄色的部分因为离得比较远所以就没编码到。
这也是降噪自动编码器的思路。下面我们看看降噪自动编码器的操作流程:
上图第一行是原始图片,下面一行是我们故意给第一行的图片里面加一些噪音,然后作为input喂入AE,让AE去训练。但是训练时的损失函数是:AE的输出和原始图片(上图第一行图片)之间的均方误差或者KL散度,作为损失函数的。这样AE的输入是带噪声的图片,但是在损失函数的牵引下,模型输出是往原图上迭代的!这样训练出来的模型,当我们给解码器输入一个噪音很大的数据(甚至一个随机的数据),解码器就会给我们返回一个和原始图片真假难辨的数字图片!至于具体是数字几,那就看你输入的随机数分布,更偏向原始图像中的数字几的分布了。
(2)变异2:给损失函数添加一些惩罚项,逼迫网络输出朝着我们想要的分布去迭代
意思就是:我们设置损失函数的时候,除了重构损失外,我们还要添加一些其他惩罚项逼迫网络往我们想要的结果去迭代。或者是我们采取一些其他手段让模型向着我们想要的方向迭代。比如稀疏自动编码器(Sparse Autoencoder),就是我们在编码的时候,在编码器网络中加一些dropout,强制沉默一些神经元,只留少数神经元将信息传递下去,就是一个稀疏自动编码器。或者在损失函数中添加L1损失,让输出更集中在少数神经元上。
变异3、直接让网络迭代概率分布
这就是VAE的策略。下面开始详讲VAE:
3、VAE原理部分
VAE的整体架构和AE一样,只是中间的Z(latent space)有了很多的戏码,而且都是数学推导,数学底子不好的理解起来就比较困难,本人也是想了好几天才有所感悟,现在梳理出来。
如果说GAN是神经网络深度学习模型,那VAE一定是一个数学中的概率模型。
下面这个系列的博主写的数学推导非常详细易懂,我也是仔细看了一遍这个博主的文章才有感悟的,下面是链接,感谢博主!
VAE - 程序员大本营
VAE(2)——基本思想
VAE(3)——公式与实现
VAE(4)——实现 - 程序员大本营
下面我总结几个VAE的关键点:
(1)编码器和解码器的整体架构选择
一是,编码器的架构一定要和解码器的架构对称。就是要在形状上对称。比如你的编码器是几个FC层,那你的解码器也是对应的几个FC层。如果你的编码器是几个卷积层cnn,那你的解码器就要是几个对称的转置卷积(因为要一层层放大尺寸嘛)。
二是,当你的训练数据是一维表格数据时,你的编码器和解码器用FC层就可以,简单方便。如果你的特征非常非常多,你也是可以用CNN的,就是得要重新reshape你的数据结构。如果你的特征不多,你还想用cnn,那就非常麻烦,你还得升维,升维后再变数据结构,而且效果也未必如愿。此处的考虑可以参考我的博文【深度视觉】第二章:卷积网络的数据_卷积神经网络 数据分析-CSDN博客 里面有数据升维的一个小案例。
当你的训练数据是图像数据时,也就是三维通道数据时,那毫无疑问,你就用CNN搭建你的编码器和解码器好了。但是如果你的图片数据非常非常简单,比如本篇博文后面的手写数字案例,那这么简单的图片数据,就不用CNN了,直接用FC也可以搞定了。
(2)编码器及其最后的输出层
在我们一般的印象中,编码器的输出是网络提取输入数据的特征信息。是的,确实是这样。但是VAE把编码器的输出,不看成是特征,而是看成了输入数据的均值和方差。也就是VAE编码器的最后是有两个输出层,一个输出层的输出被看作是原始数据的均值、另一个输出层的输出被看作是原始数据的方差。
但是这里要重点说明的是: 我看网上的很多资料都把方差输出层看成了log var输出,因为从它的损失函数计算公式中,它们都把输出看成了 log var。我个人觉得是因为方差这个东西肯定是>=0的一个数,但是从编码器的最后一个层出来的数据肯定是有正有负的,而且大多数参考资料中,这个输出层后面都没有跟relu或者其他激活函数的,所以,此时看成log var就更合理一些。因为var恒>=0,那log var可不就是有正有负喽。所以我们后面都把这个输出看成log var。
一句话总结:VAE编码器的输出有2个,一个是输出均值,一个是输出log var。
这里还有啰嗦一下,平时我们都说神经网络输出的是特征嘛,对,VAE输出的不是特征是输入数据的分布!又有人疑问了:你说它输出的是分布就是分布啦,你给狗取个人名,这只狗就变成人啦?!对,还真是这样。因为神经网络是可以训练的,我们用损失函数牵引它训练,让它从狗样往人样去训练,还真能变成人样!比如,前面讲的稀疏自动编码器,就是给损失函数添加一些惩罚项,让网络朝着损失函数期望的方向迭代,还真就可以达到这个目的。所以VAE也是同样的手段:给损失函数添加约束项,让网络朝着我们想要的方向迭代。所以下面我们开始剖析VAE的损失函数。
(3)损失函数
VAE的损失函数是分两部分:重构损失 + KL loss
其中,重构损失指的是解码器的输出和输入数据之间的差异。因为自编码器天生的就是要输入和输出最大化的相似啊,我训练VAE网络,就是想让它给我生成一些以假乱真的图片呀,所以输入图片和输出图片之间的差异肯定是要构成损失函数的一部分的。这点应该不难理解。
其中,KL loss指的是KL散度的损失。KL散度是衡量两个分布之间的差异程度的一个指标。如果两个分布差异越大,KL散度值就越大!
那VAE模型中KL loss是衡量哪两个分布之间的损失呢?衡量的是编码器输出的所有的(均值、方差)对儿 和 N(0,1)标准正态分布之间的KL散度。
也就是说我们通过在损失函数中添加KL loss 让VAE的编码器的输出尽量往正态分布的方向去迭代!
也就是说我通过设置loss = 重构损失 + KL loss, 那我在训练VAE的时候,VAE的参数就朝这个方向迭代:一是朝着“当我喂入VAE训练数据图片后,编码器输出的所有均值方差对儿都越来越靠近标准正态分布,就是均值越来越靠近0,方差越来越靠近1,或者说log var越来越靠近0。就是两个输出层都越来越靠近0。二是朝着“不管是编码器还是解码器,二者的参数都朝着,整个网络的输入和输出最相似的方向迭代”。
(4)为什么要编码器的输出都是0均值1方差?
可以说VAE的难点和重点和特殊点就在这个地方。这个问题要想精确得了解,还是得细细看我上面推荐的4篇博文,他从数学层面非常清晰的剖析了原因。这里我用通俗的大白话再总结一下:
因为我想对解码器输入一个随机数,解码器就能给我生成一张和输入图片几乎一样的图片啊!那我要到达这个目的,是不是我的编码器的输出都是正态分布啊!如果编码器的输出不是正态分布,那我随机一个随机数,输入解码器,解码器就不能给我解码出这个随机数大概率对应的、和训练图片一样的图片啊!或者说就是把训练集数据的真实分布映射到一个标准正态分布上,就是两个分布之间的变换。
用稍稍专业一点的话说就是,VAE学的就是一个高维高斯分布,它就是一个混合高斯模型(Gaussian Mixture Model,GMM) ,就是对高维的数据进行概率表示的一个模型,就是多个高斯分布函数的线性组合!如下图所示: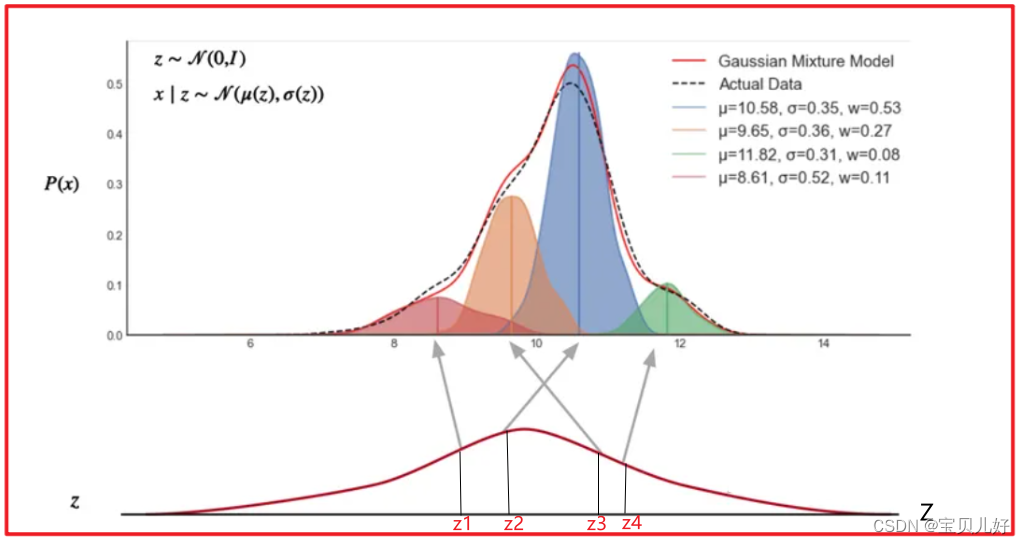
上图就可以非常直观的说清楚这个问题。上图就是我们AVE学习的Latent space隐式空间。你看,大Z是不是服从N(0,1)正态分布,现在我要生成一个随机数4个小z,这4个小z就是从标准正态分布中随机抽取的,假设就是z1,z2,z3,z4这四个点。那现在我把这4个小z分别喂入解码器。那VAE就会根据它学习的这个隐式空间的对应关系,把z1映射到上面混合高斯分布的红色分布区域。而红色分布区域是训练集数据真实的概率分布。假如红色分布是训练集中猫的图片、橙色分布对应的图片是一张狗的图片、蓝色分布对应的图片是训练集中人的图片、绿色分布是天空的图片。所以当你喂入解码器z1时,解码器给你返回的就是一张猫图;当你喂入z2时,返回的就是一张有人的图片;同理z3大概率就是一张猫图;z4就是一张天空的风景图。当然你输入别的随机数,也可能会得到一张比如既像猫又像狗的图。
- 那Z和P(x)如何映射呢?
你Z都是一个标准正态分布,就是Z~N(0, 1),如果P(x)也接近正态分布,假如P(x)~N(均值,方差),那x和z之间的关系是不是就是:P(x)=z*方差+均值
z和x是不是就建立了分布之间的映射关系了!而且重点是这个映射关系可导呀!网络训练的时候是可以正常正向传播和反向求导的呀!这也太香了!很多参考资料把这个环节叫重参数技巧!别被这么专业的一个词汇给吓懵了,后面的代码实现的时候,代码背后的数学原理就是这个原理!
至此,你也就非常清楚我为什么在损失函数中加上KL散度损失,逼迫编码器的输出尽量朝正态分布输出了。也是因为每个样本的分布尽量往正态分布靠,那所有样本的联合分布就越靠近正态分布,那所有样本的联合分布就和z的分布之间有更好的对应关系了。
至此,VAE理论部分的重点该讲的都讲到了。下面是KL散度的推导公式:

这个推导公式贴出来是因为,后面的编写代码的时候,损失函数要用到这些结论。网上很多资料都是直接用,也没有解释为什么是这么计算的,更没有人解释为啥编码器输出不是方差而是log_var等这些细节。
4、VAE架构图
如果上面的文字原理部分,你还云里雾里,我觉得还是有必要画一个VAE的架构图,来直观的看一下,你会有更深的体会。
由于后面我还要写一个实现案例,就是用手写数据集MNIST来训练一个VAE,看看效果。所以这里的架构我就画成针对这个数据集的架构了:
从上面的架构图我们可以清晰看出随机数z是怎么和FC3_1、FC3_2的输出对应的。这个过程就是重参数技巧!
另外还要说明的一点就是KL LOSS是怎么计算的:
比如样本1的kl loss的计算公式就是用上上图右下角的公式:0.5* torch.sum(M1_1.pow(2) + LW1_1.exp() - LW1_1 - 1) ,这里的sum求得都是样本1输出的20对儿均值和方差对儿。
同理,m条样本,可以求m条样本的kl loss和,也可以求平均值,你随意,都可以。
5、代码实现生成手写数字
#导库、导MNIST数据集并加载
import os
import torch.nn.functional as F
import torchvision
from torchvision import transforms, utils
from torch.utils.data import DataLoader
from torchvision.utils import save_image
T = transforms.Compose([transforms.ToTensor()])
dataset = torchvision.datasets.MNIST(root = r'D:\pytorch-data\mnist\data\MNIST', transform = T, download=False)
dataloader = DataLoader(dataset, batch_size=128, shuffle=True)#数据探索:看看我们的数据集
batch_img = next(iter(dataloader))
plt.axis('off')
plt.title('MNIST')
plt.imshow(np.transpose(utils.make_grid(batch_img[0]), (1, 2, 0)))
#写VAE架构
class My_VAE(nn.Module):
def __init__(self):
super().__init__()
# Encoder
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc31 = nn.Linear(256, 20)
self.fc32 = nn.Linear(256, 20)
# Decoder
self.fc4 = nn.Linear(20, 256)
self.fc5 = nn.Linear(256, 512)
self.fc6 = nn.Linear(512, 784)
def encoder(self, x):
h1 = F.relu(self.fc1(x.view(-1, 784))) #x传进来的时候是:([128, 1, 28, 28]), view后是:([128, 784]),再进入线性层
h2 = F.relu(self.fc2(h1))
return self.fc31(h2), self.fc32(h2)
def reparameterize(self, mean, log_var): #重参数 reparameterize
std = torch.exp(0.5*log_var) #求标准差---torch.Size([128, 20])
z = torch.randn_like(std) #随机生成一个z----torch.Size([128, 20])
z_ = z.mul(std).add_(mean) #再隐式空间转化z #torch.Size([128, 20])
return z_
def decoder(self, x):
h4 = F.relu(self.fc4(x))
h5 = F.relu(self.fc5(h4))
return F.sigmoid(self.fc6(h5))
def forward(self, x):
mean, log_var = self.encoder(x)
z = self.reparameterize(mean, log_var)
reconst = self.decoder(z)
return reconst, mean, log_var# 开始训练
num_epochs = 10
learning_rate = 0.001
net = My_VAE() #实例化架构
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate) #优化器
for epoch in range(num_epochs):
for i, (x, _) in enumerate(dataloader):
reconst, mean, log_var = net.forward(x)
reconst_loss = F.binary_cross_entropy(reconst, x.view(-1, 784), reduction='sum') # 计算重构损失
kl_loss = 0.5 * torch.sum(mean.pow(2) + log_var.exp() - log_var -1) # KL散度损失
loss = reconst_loss + kl_loss # 计算总损失
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0: #打印损失
print("Epoch[{}/{}], Step [{}/{}], Reconst Loss: {:.4f}, KL Loss: {:.4f}"
.format(epoch + 1, num_epochs, i + 1, len(dataloader), reconst_loss.item(), kl_loss.item()))
with torch.no_grad(): #训练完毕一个epoch后,看看效果
z = torch.randn(128, 20) # 用随机数 z解码输出
out = net.decoder(z).view(-1, 1, 28, 28)
save_image(out, os.path.join(r'D:\pytorch-data\VAE', 'decode_{}.jpg'.format(epoch + 1)))
out, _, _ = net(x) # 查看输入图像和重构图像之间的差异
x_concat = torch.cat([x.view(-1, 1, 28, 28), out.view(-1, 1, 28, 28)], dim=3)
save_image(x_concat, os.path.join(r'D:\pytorch-data\VAE', 'reconst_{}.png'.format(epoch + 1)))架构和代码算是非常简单的了,就是原理太难了。
我训练10个epochs(大约也就几分钟)后的效果:
但是这里还要说一点,我看有的人把均值和方差的输出都设置的是2维(上面我自己的案例中,我设置的是20维,就是每个z的长度都是20,就是z是一个长度维20的向量)。它们把长度设置为2,就出现下面很奇特的结果:
很奇特吧,在平面中数字和数字之间是慢慢过渡的那种,就是这些像素点的数值是在一个二维空间中的正态分布,所以才有上图的景观。我觉得这个点更加有助于我们理解VAE是一个混合高斯模型,实现分布与分布之间的转换。















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









