







文章目录
Pandas
Python Data Analysis Library 或 pandas 是基于NumPy的一种工具,为了解决数据分析任务而创建的。同时纳入了大量库和一些标准的数据模型,高效地操作大型数据集所需的工具。
Pandas基本数据结构
Series
一维数组,与Numpy中的一维array类似。二者与Python剧本的数据结构List相近。
Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。DataFrame
二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容易。
Pandas库的series类型
默认情况下,Series的下标都是数字(可以使用额外参数指定),类型是统一的
s = pd.Series([1, 3, 5, np.nan, 6, 8]) #一维Series可以用一维列表初始化
s = pd.Series([1, 3, 5, np.nan, 6, 8], index=[‘a’,‘b’,‘c’,‘d’,‘e’,‘f’])
print(s)
索引-数据的行标签
s.index # RangeIndex(start=0, stop=6, step=1)
值
s.values # [ 1. 3. 5. nan 6. 8.]
切片操作
同numpy
索引赋值
s.index.name = '索引'
s.index=list('abcdef')
s[‘a’:‘c’] # 左闭右闭
Pandas库的DataFrame类型
date = pd.data_range(‘20250519’,periods=6)
print(date)
df = pd.DataFrame(np.random.randn(6,4), index=date,columns=list(‘ABCD’))
使用字典传入数据
…
查看数据
df.head() # 不输入默认为前5行
df.tail()
df.dtypes # 各个数据的类型
df.index
df.columns
df.values
pandas读取数据及数据操作
df = pd.read_excel(‘filename.xlsx’)
df,head()
行操作
df.iloc[0]
df.iloc[0:5] # 类似df.head()
df.loc[0:4]
添加一行
dit = {…}
s = pdf.Series(dit)
df = df._append(s)
删除一行
df = df.drop([38738])
print(df.tail())
列操作
df.columns
增加一列
df[‘序号’] = range(1, len(df) + 1)
删除一列
df = df.drop(‘序号’, axis=1)
通过标签选择数据
df.loc[[index],[column]]
条件选择
df[df[‘产地’] == ‘中国’][:5]
缺失值及异常值处理

填充缺失值
df['评分'].fillna(np.mean(df['评分']),inplace=True)
删除缺失值

数据保存
df.to_excel('movie_data.xlsx')
数据格式查看与转换
df[‘投票人数’].dtype
df[‘投票人数’] = df[‘投票人数’].astype(‘int’)
排序
默认排序
df.sort_values(by='投票人数', ascending=False)[:5]
多个值排序
df.sort_values(by=['评分','投票人数'], ascending=False)[:5]
基本统计分析
dataframe.describe():对dataframe中的数值型数据进行描述性统计
df[['投票人数','评分']].corr()相关系数
df[['投票人数','评分']].cov()协方差
var方差
unique()去重
replace(_src, _dst, [inplace=True])替换
replace([_src], [_dst], [inplace=True])替换
value_counts() 每个值 每个值出现的次数默认从大到小
数据透视
快速地对数据进行强大的分析。
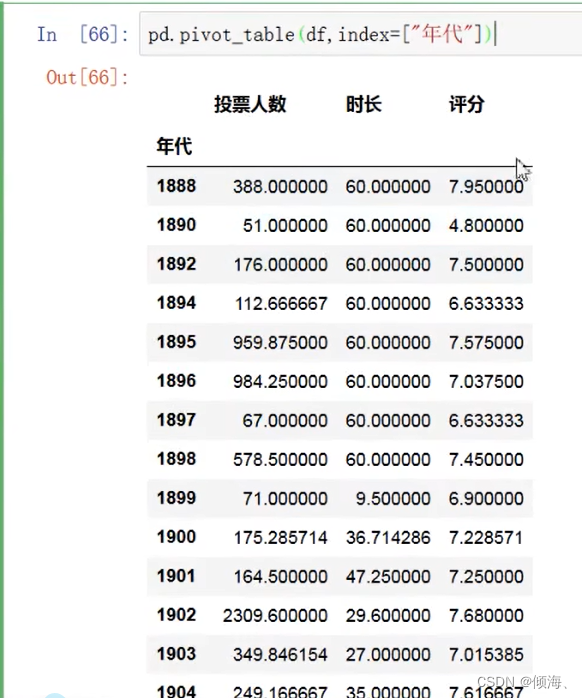
pd.set_option('display:max_columns',100)
pd-.set_option('display:max_rows',500)
多个索引
pd.pivot_table(df, index=['年代','产地'])
指定列
pd.pivot_table(df, index=['年代','产地'],values=['评分'])
指定函数统计不同的统计值
pd.pivot_table(df, index=['年代','产地'],values=['投票人数'],aggfunc=np.sum)
pd.pivot_table(df, index=['产地'],values=['投票人数','评分'],aggfunc=[np.sum,np.mean])
pd.pivot_table(df, index=['产地'],aggfunc=[np.sum,np.mean],fill_value=0) 填充NaN为0
pd.pivot_table(df, index=['产地'],aggfunc=[np.sum,np.mean],fill_value=0,margins=True) 最后一行添加总和结果
不同值执行不同函数
pd.pivot_table(df, index=['产地'],values=['投票人数','评分'],aggfunc={'投票人数':np.sum,'评分':np.mean},fill_value=0)
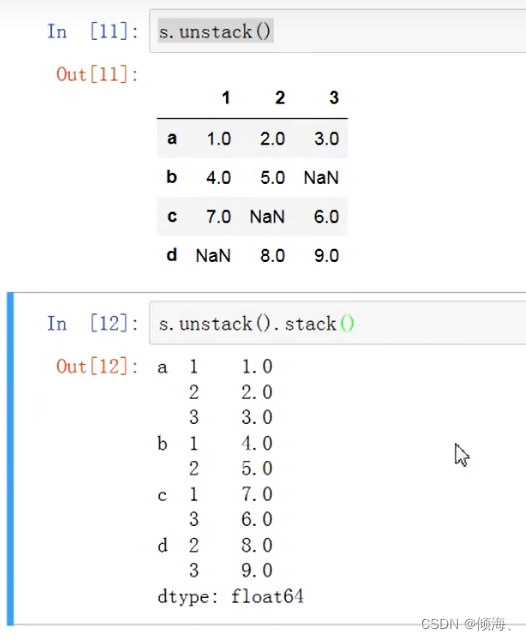
数据重塑和轴向旋转
Series的层次化索引
s = pd.Series(np.arange(1, 10), index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,3]])
print(s.index)
Series与Dataframe转化
Dataframe的层次化索引
data = pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['A','A','B'],['Z','X','C']])
print(data)
data['A']
data.index.names = ['row1','row2']
data.columns.names = ['col1','col2']
data.swaplevel('row1','row2') # 交换
产地和年代同时设成索引,产地是外层索引,年代为内层索引
set_index可以把列变为索引
reset_index是把索引变成列
df=df.set_index(['产地','年代'])
print(df)
取消层次化索引
df=df.reset_index()
数据旋转
.T可以直接旋转行列
数据分组,分组运算
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表。
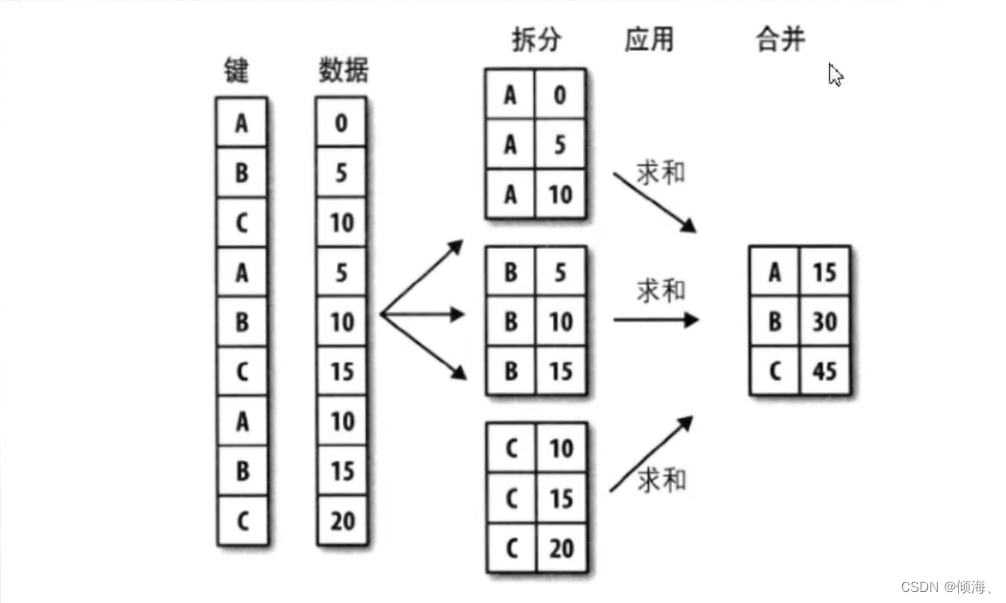
# 按照电影的产地进行分组
group = df.groupby(df['产地'])
print(group.mean())
print(group.sum())
# 计算每年的平均评分
df['评分'].groupby(df['年代']).mean()
df['年代'] = df['年代'].astype('str')# 保证下面不会对年份进行运算
df.groupby(df['产地']).sum()
df.groupby([df['产地'],df['年代']]).mean()
离散化处理
实际中,对有的数据属性,往往并不关心数据的绝对取值,只关心它所处的区间或者等级。
离散化也可称为分组、区间化。
pd.cut(x, bins, right=True, labels=None,retbins=False,precision=3,include_lowest=False)
x:需要离散化的数组、Series、DataFrame
bins: 分组的依据
# (]区间
df['评分等级']=pd.cut(df['评分'],[0,3,5,7,9,10],labels=['E','D','C','B','A'])
bins = np.percentile(df['投票人数'],[0,20,40,60,80,100])
df['热门程度'] = pd.cut(df['投票人数'],bins,labels=['E','D','C','B','A'])
合并数据集
append 先把数据集拆分为多个,再进行合并
df_usa = df[df.产地=='美国']
df_china = df[df.产地=='中国大陆']
df_china.append(df_usa)
merge pd.merge(df1, df2, how=‘inner’, on=‘名字’)
concat 将多个数据集进行批量合并
df1 = df[:10]
df2 = df[100:110]
df3 = df[200:210]
dff = pd.concat([df1, df2 ,df3], axis=0)
















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











