







文章目录
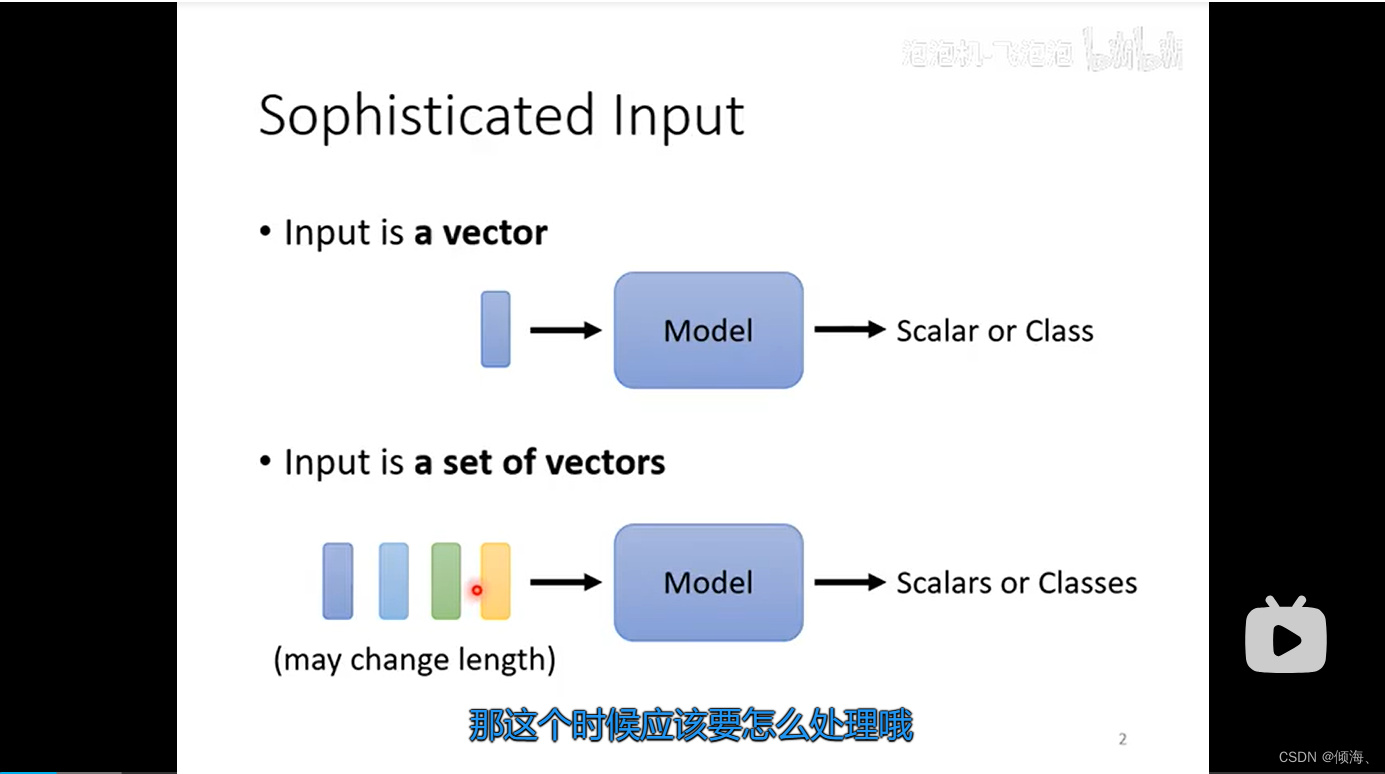
输入
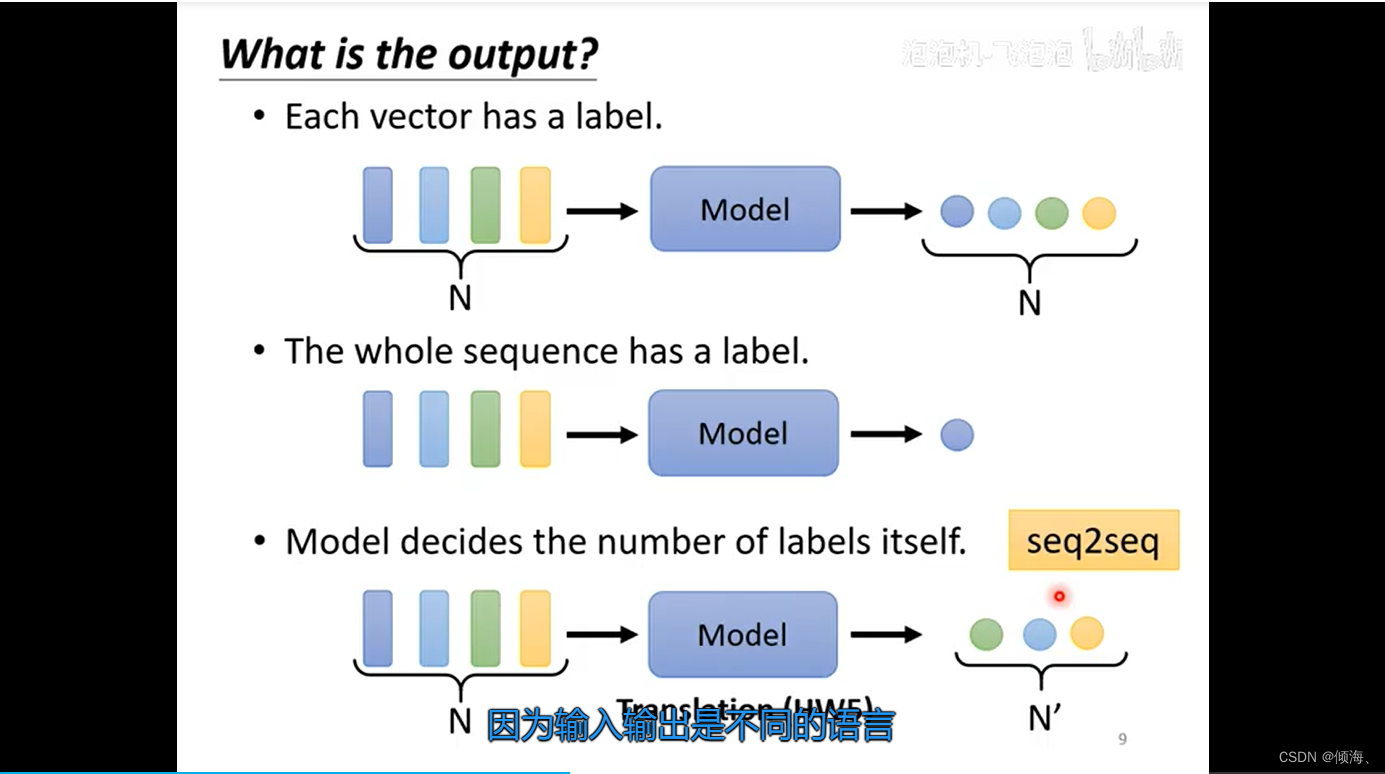
输出
运行
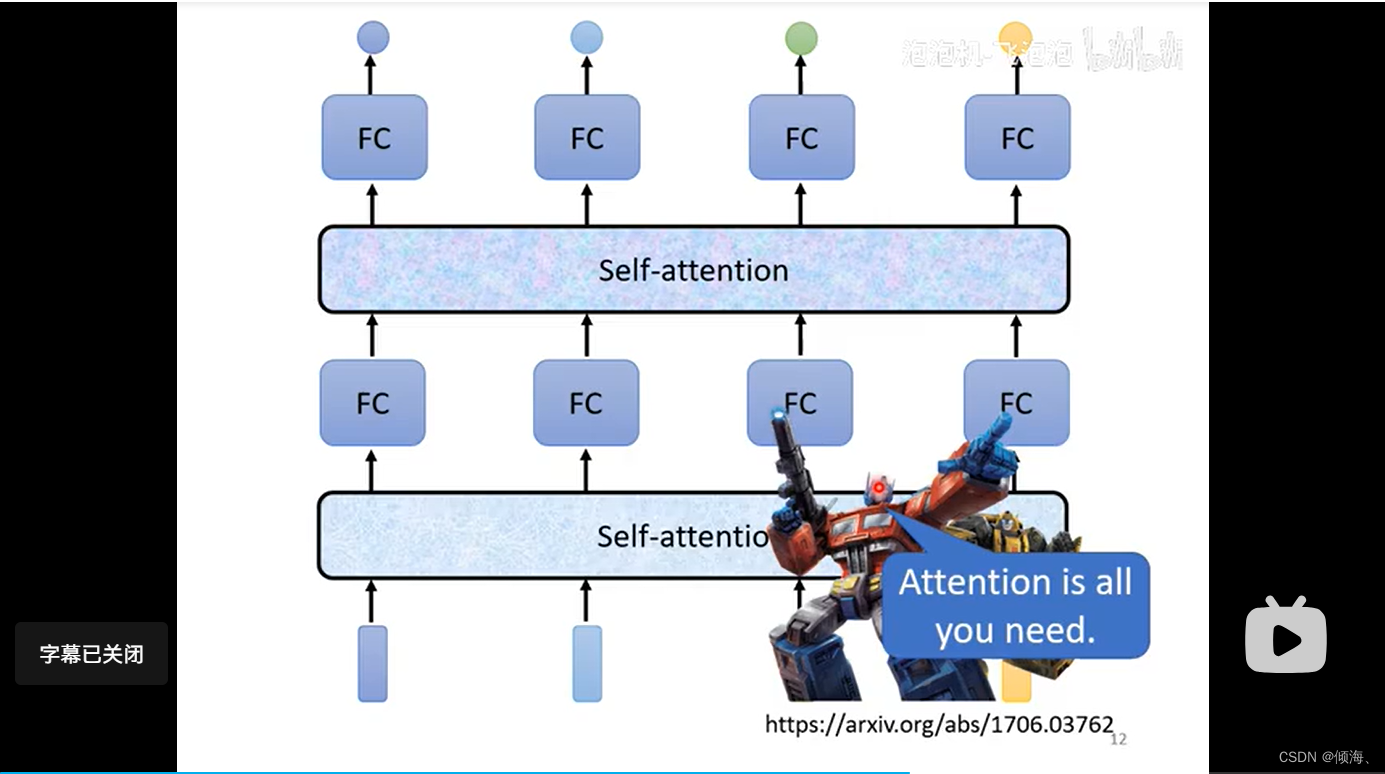
如何运行
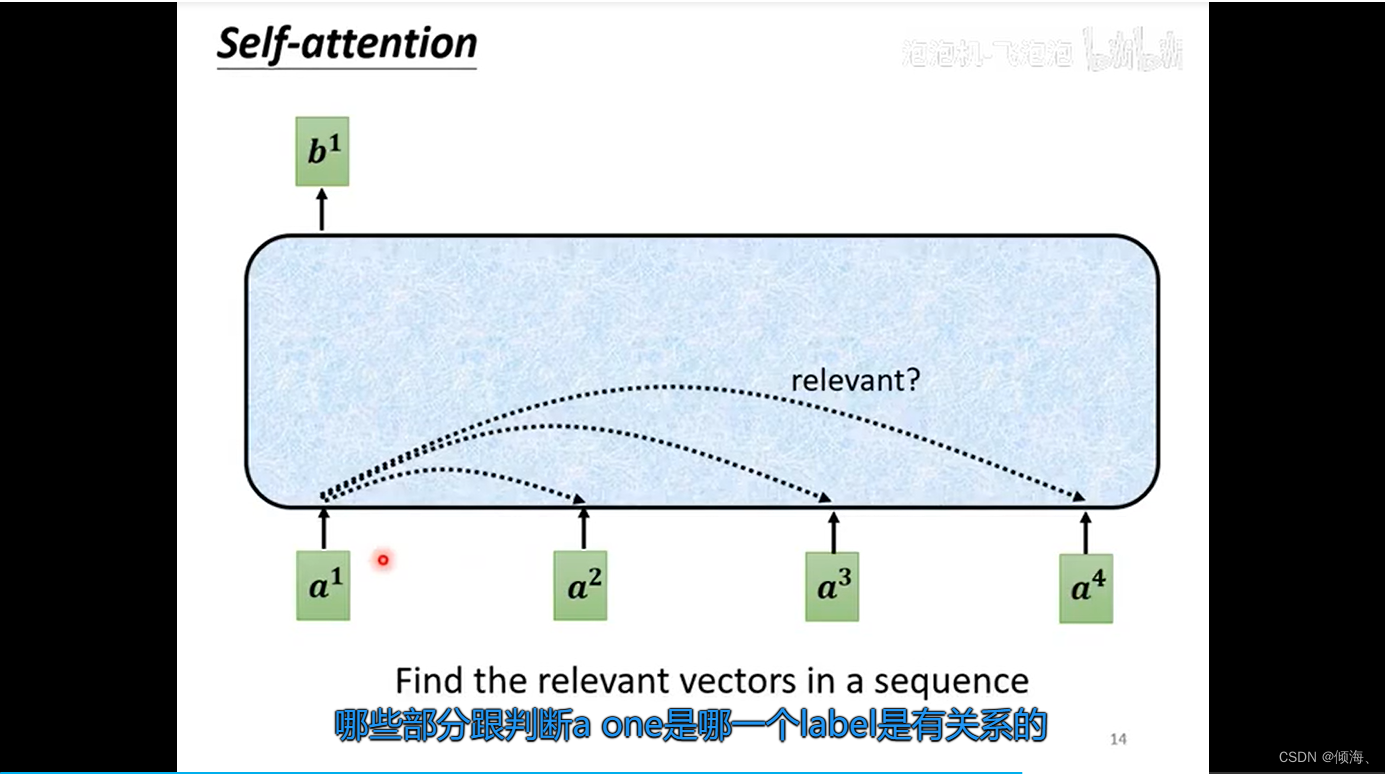
解决关联性
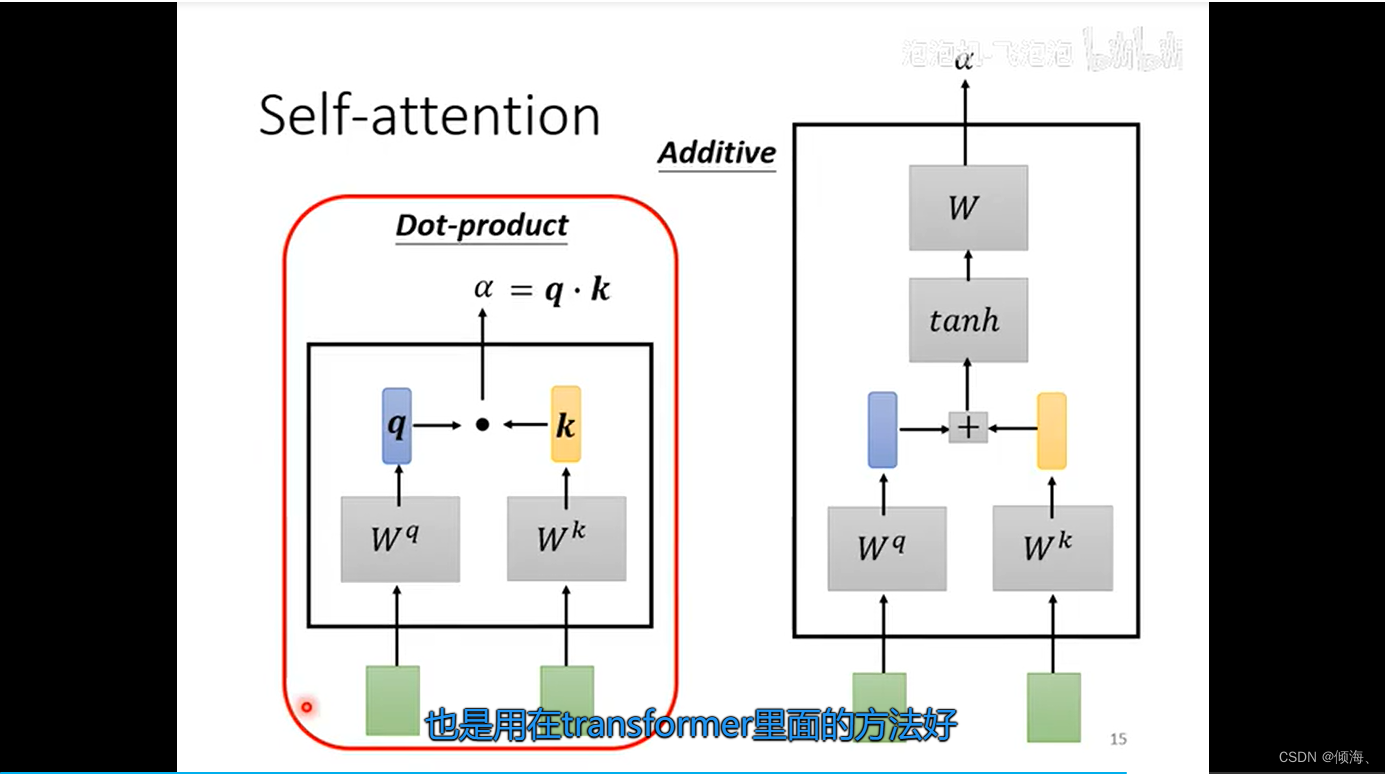
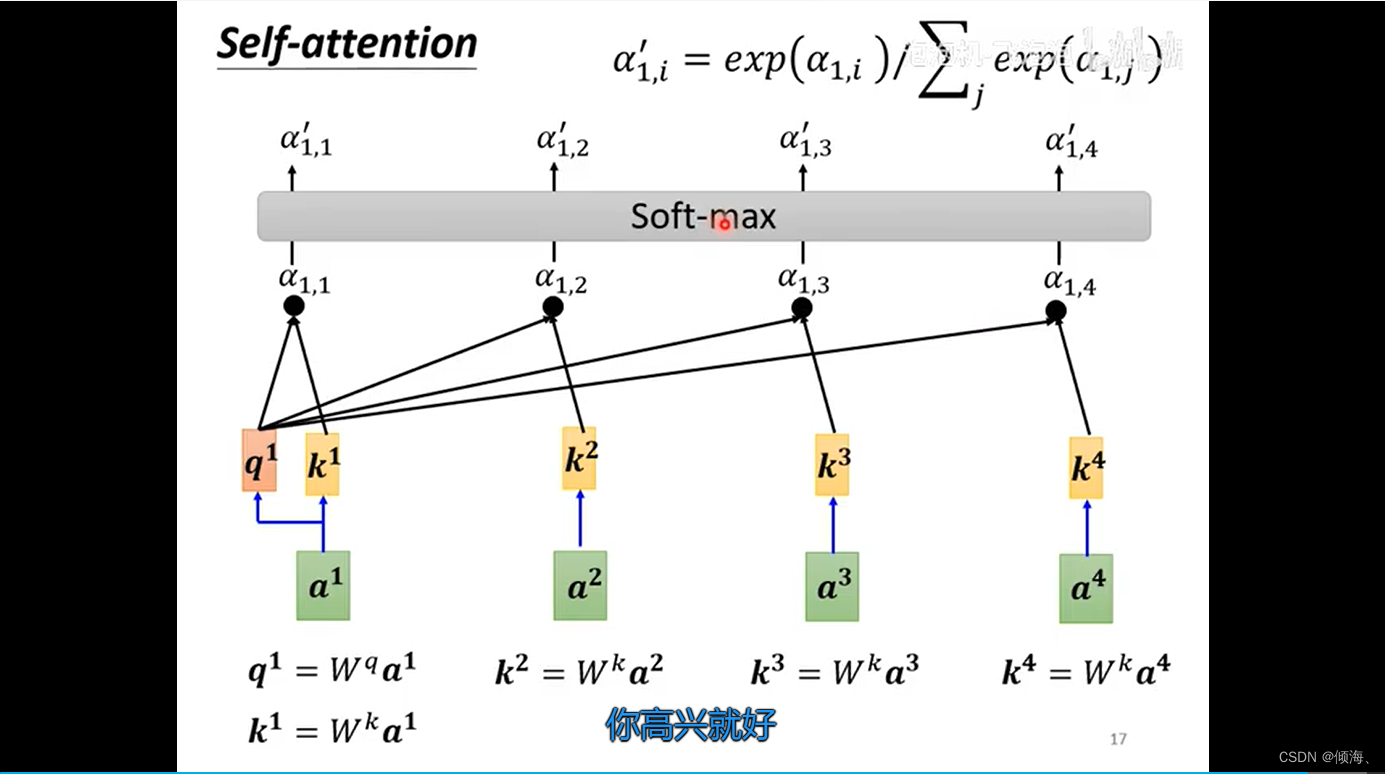
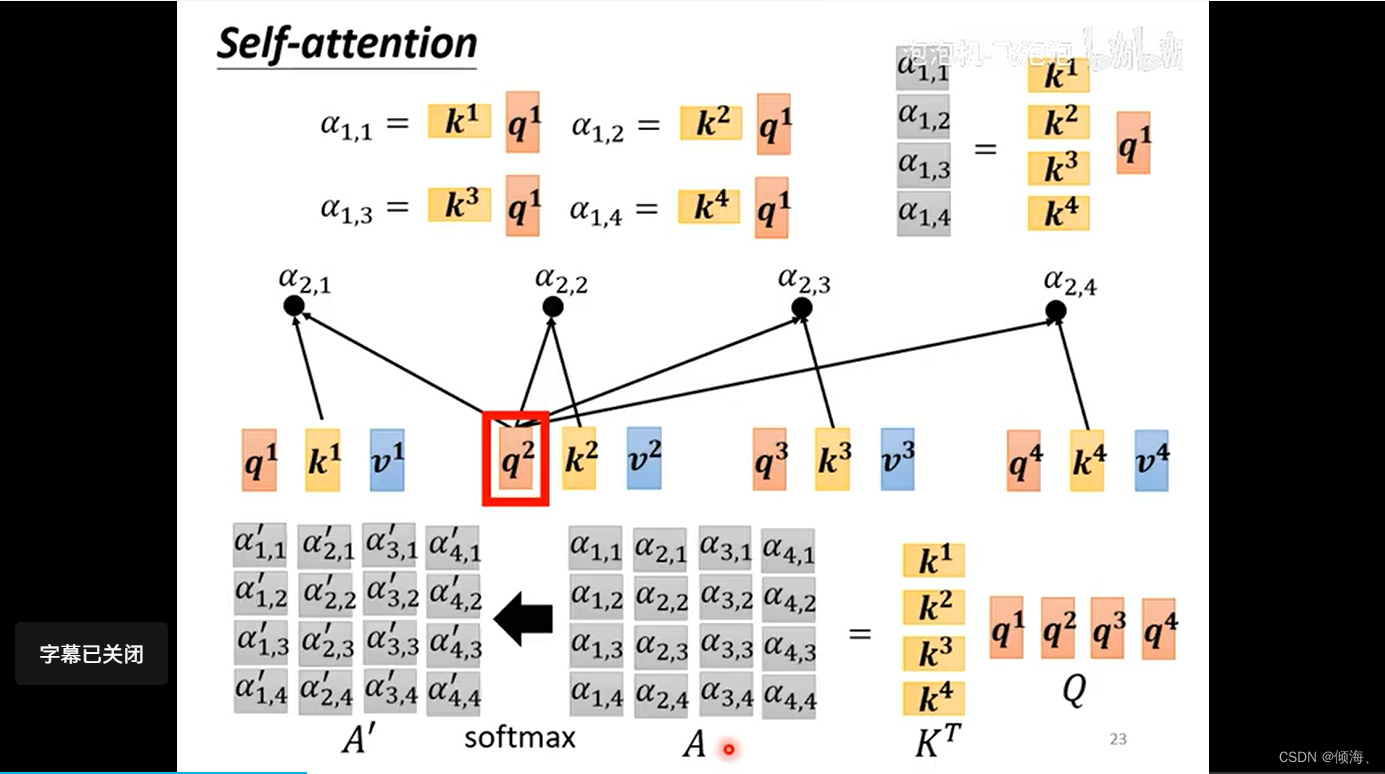
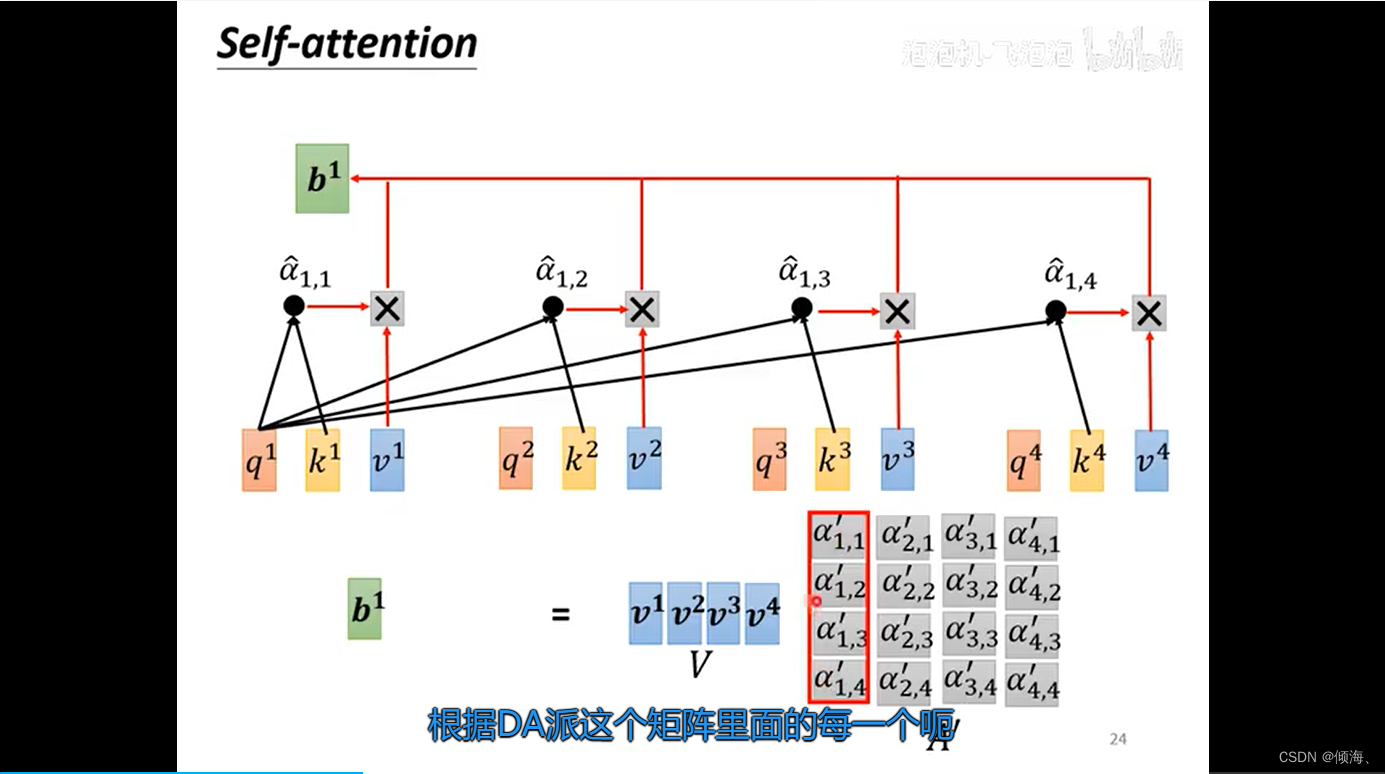
attention score
也可以不用softmax,relu也行。
额外的
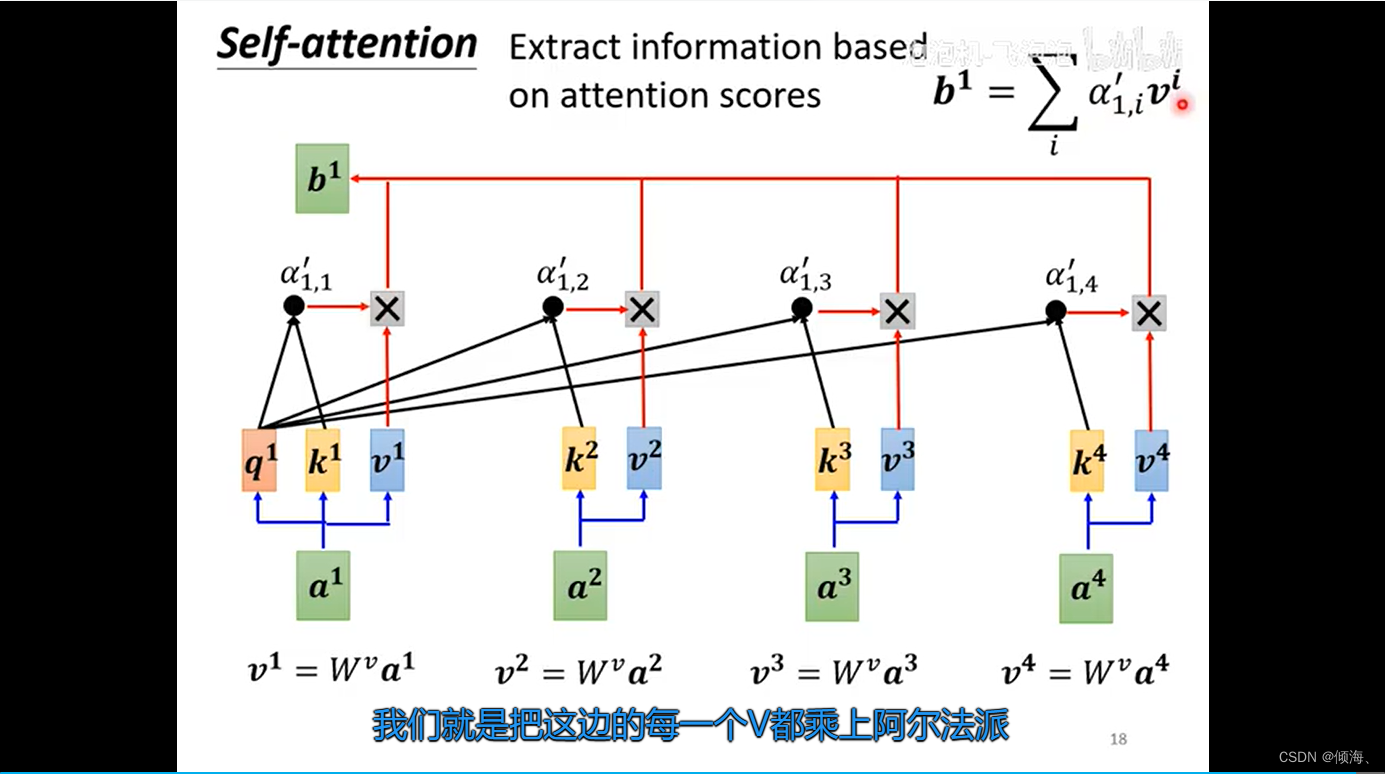
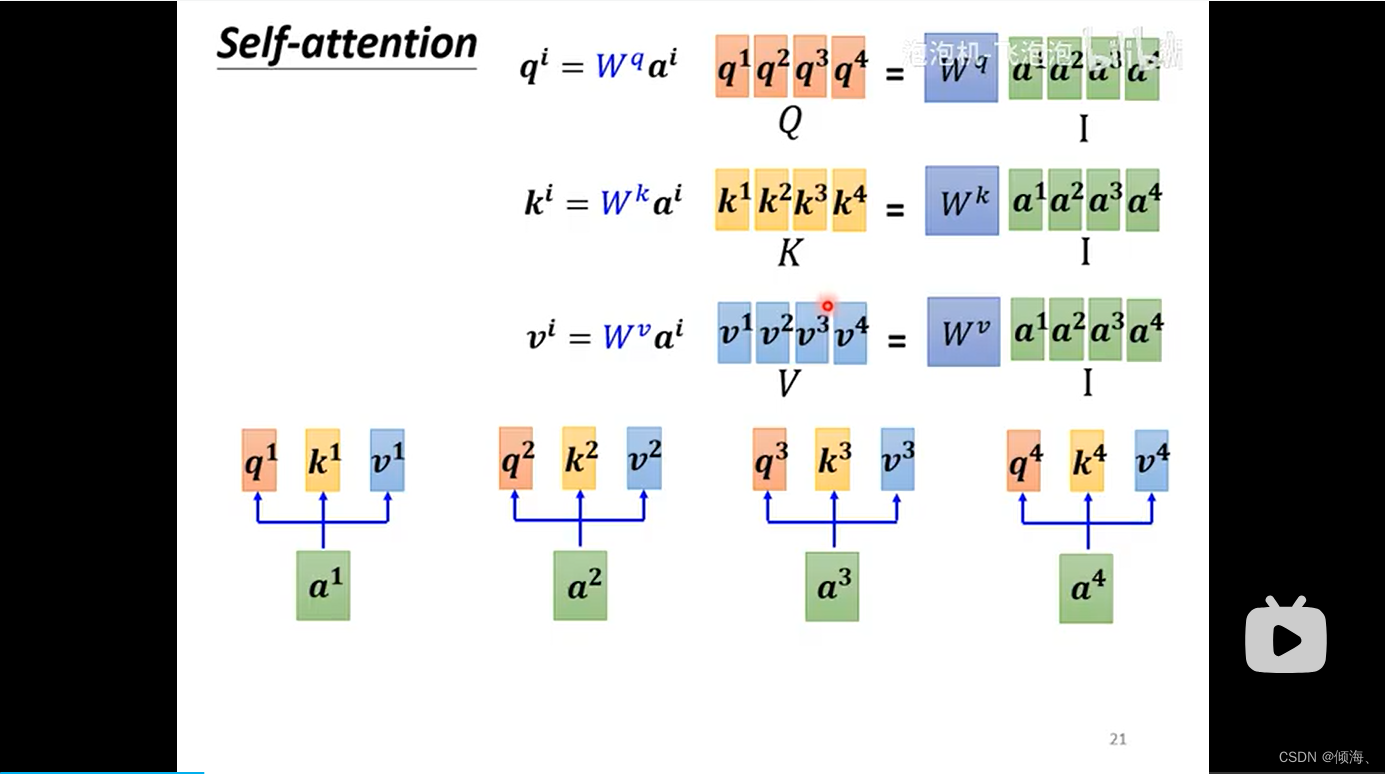
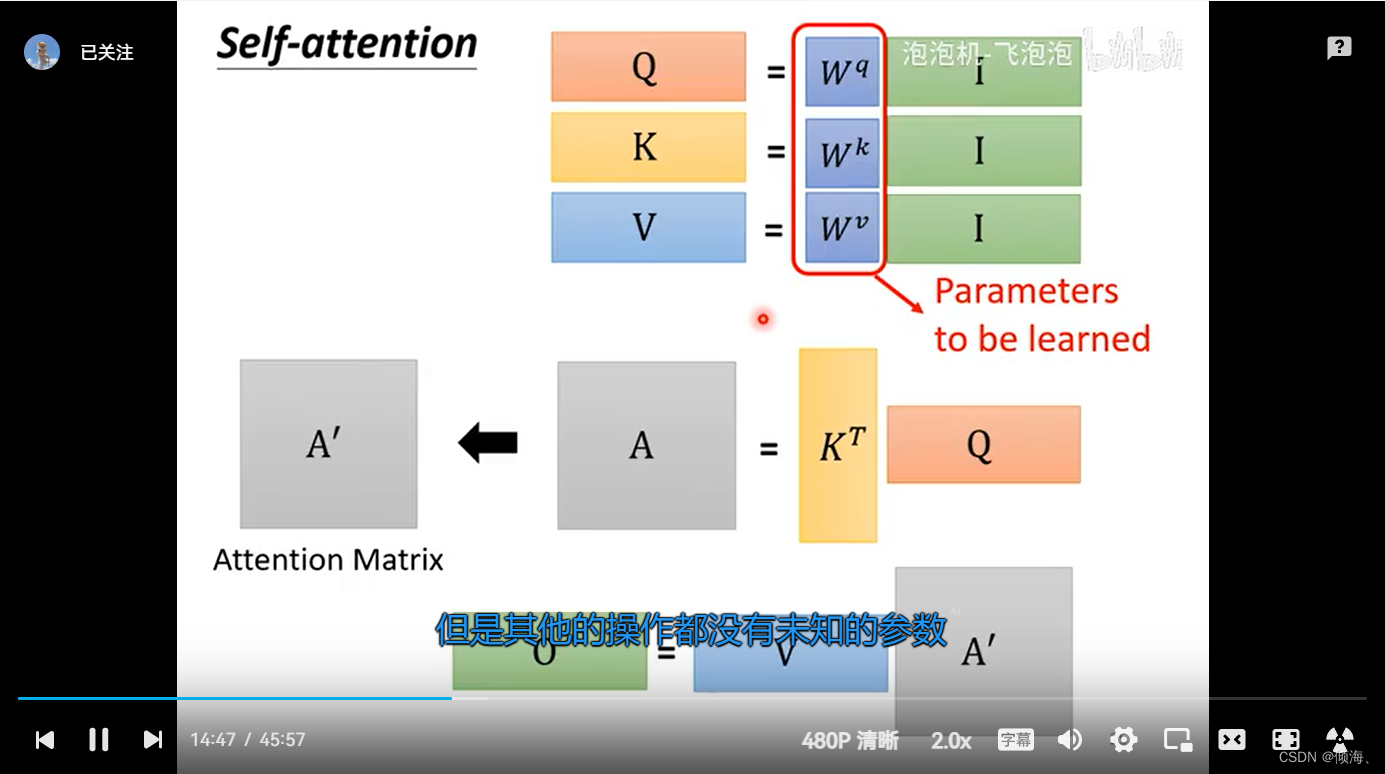
Q K V
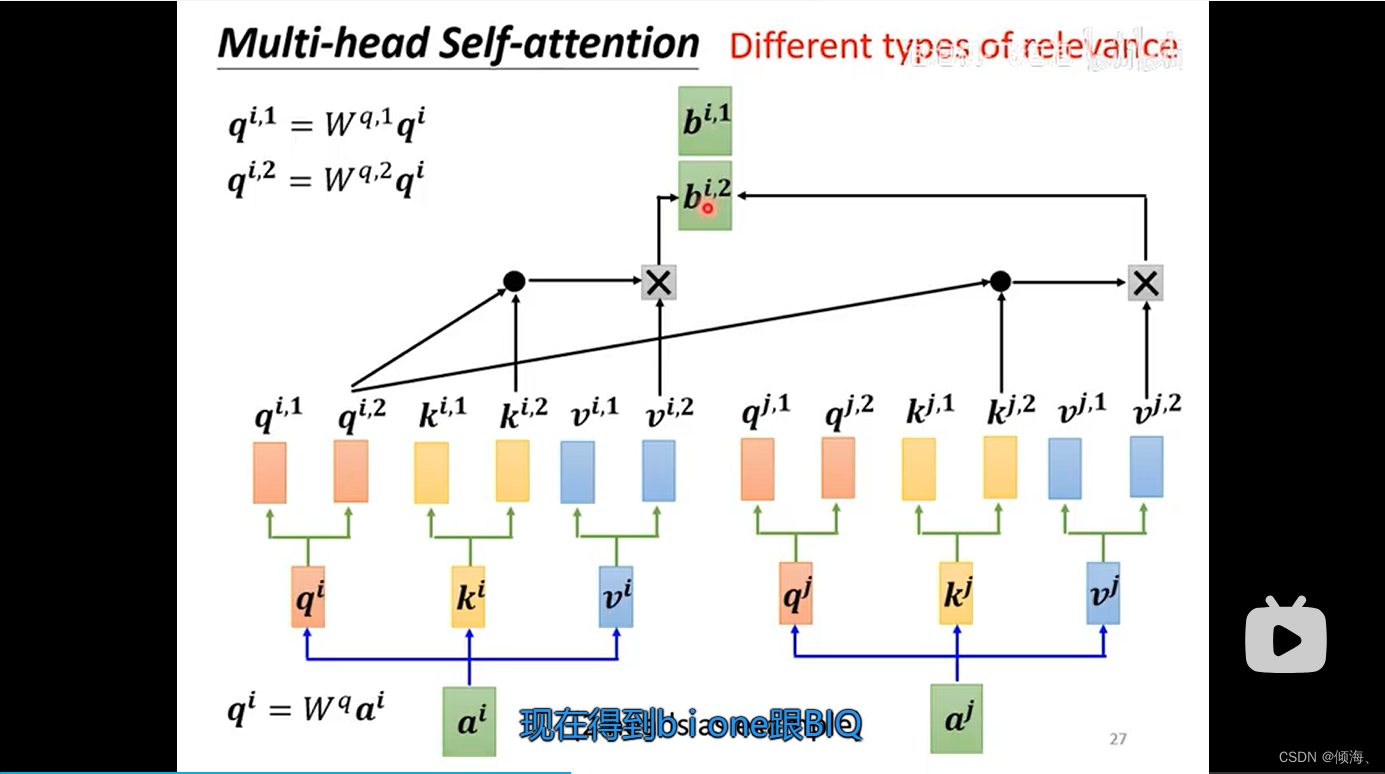
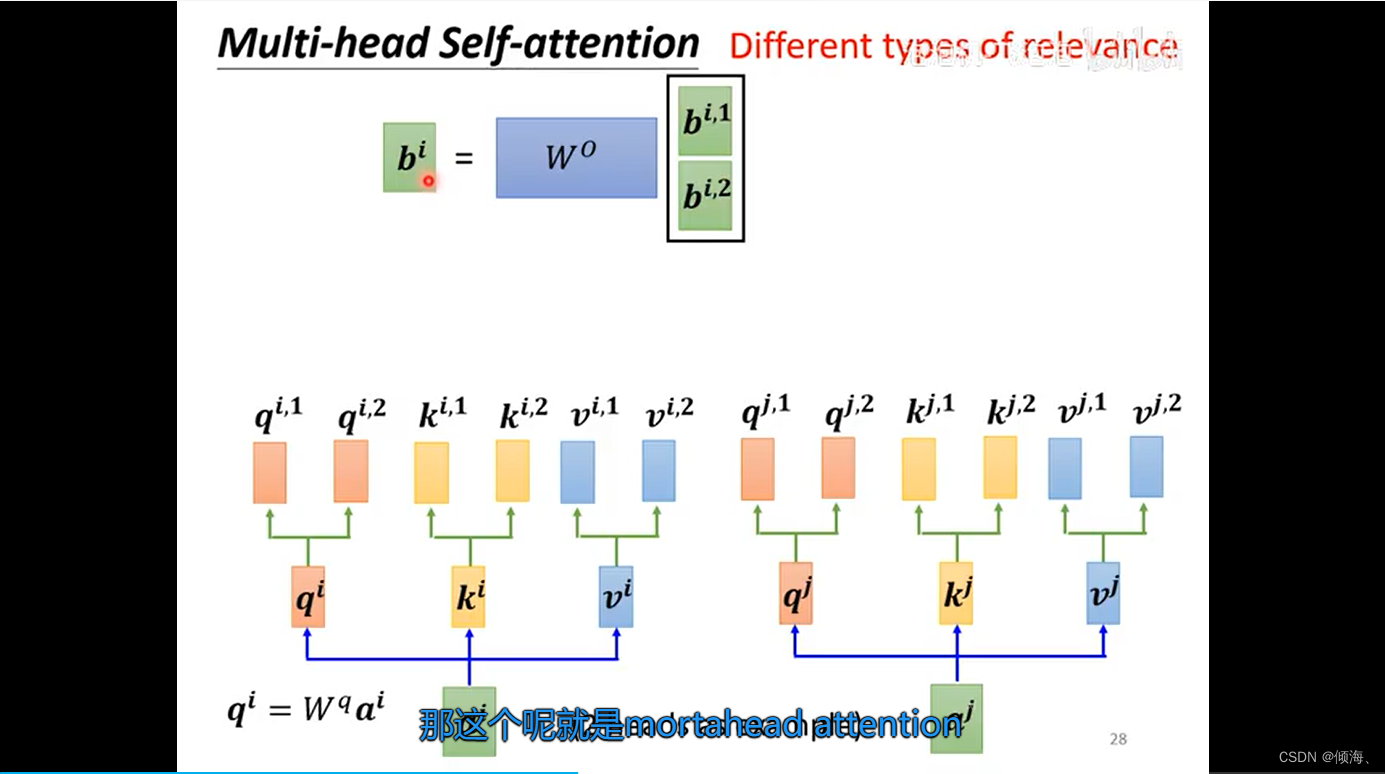
Multi-head self-attention
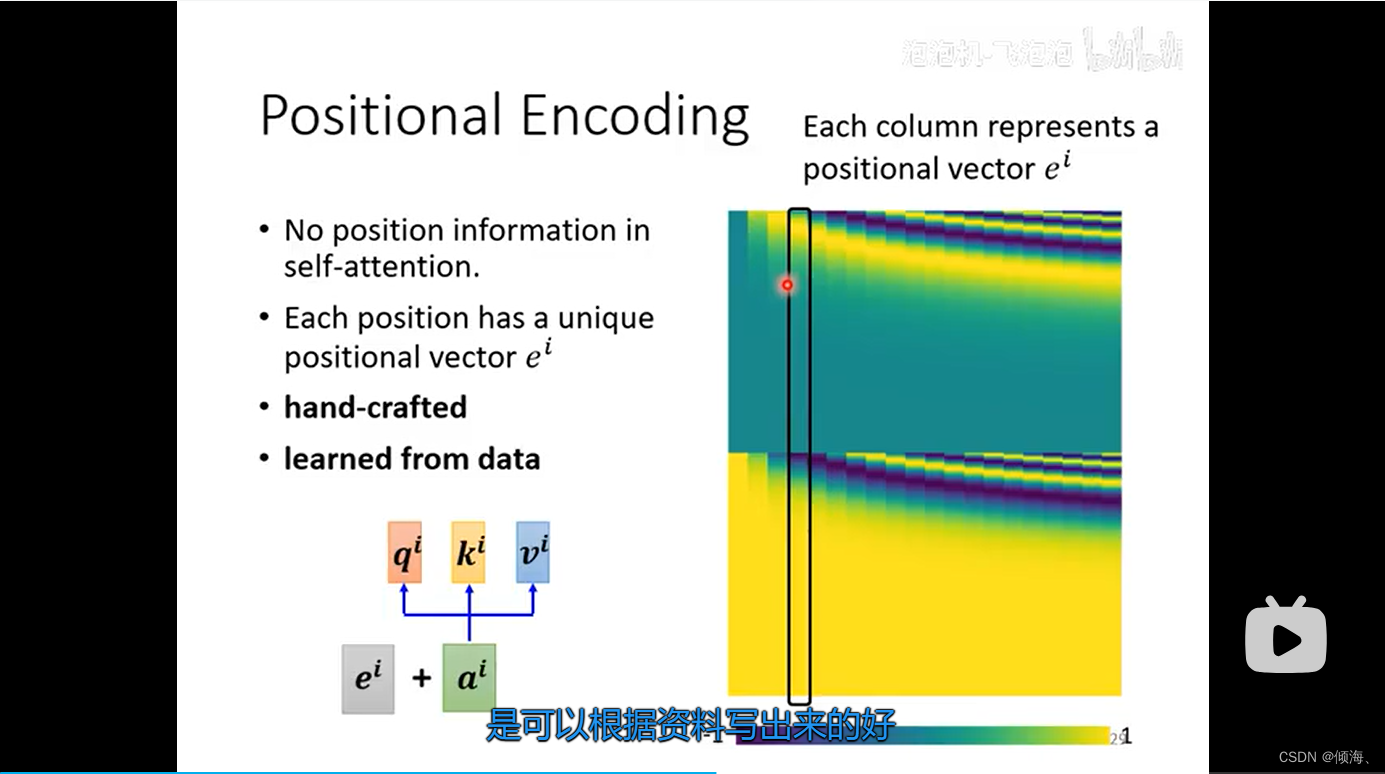
Positional Encoding
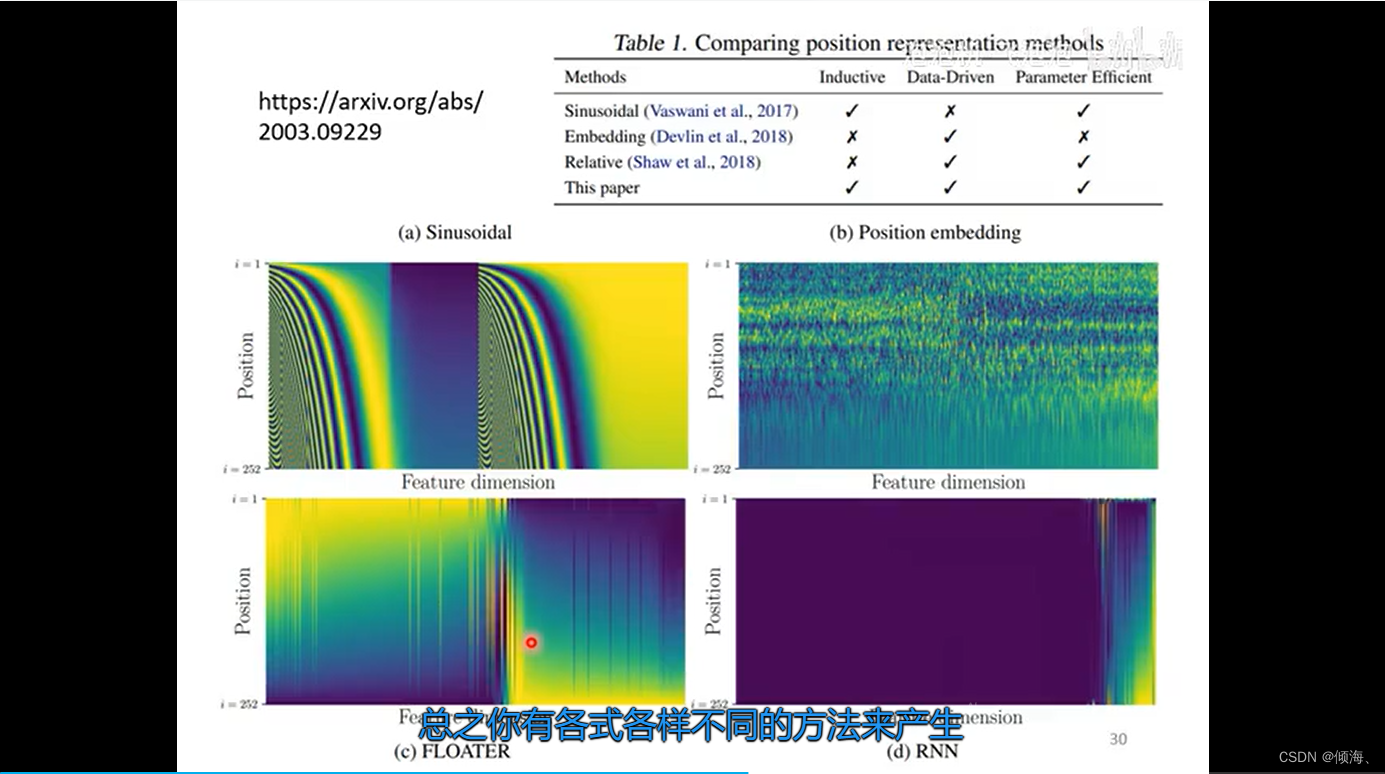
https://arxiv.org/abs/2003.09229
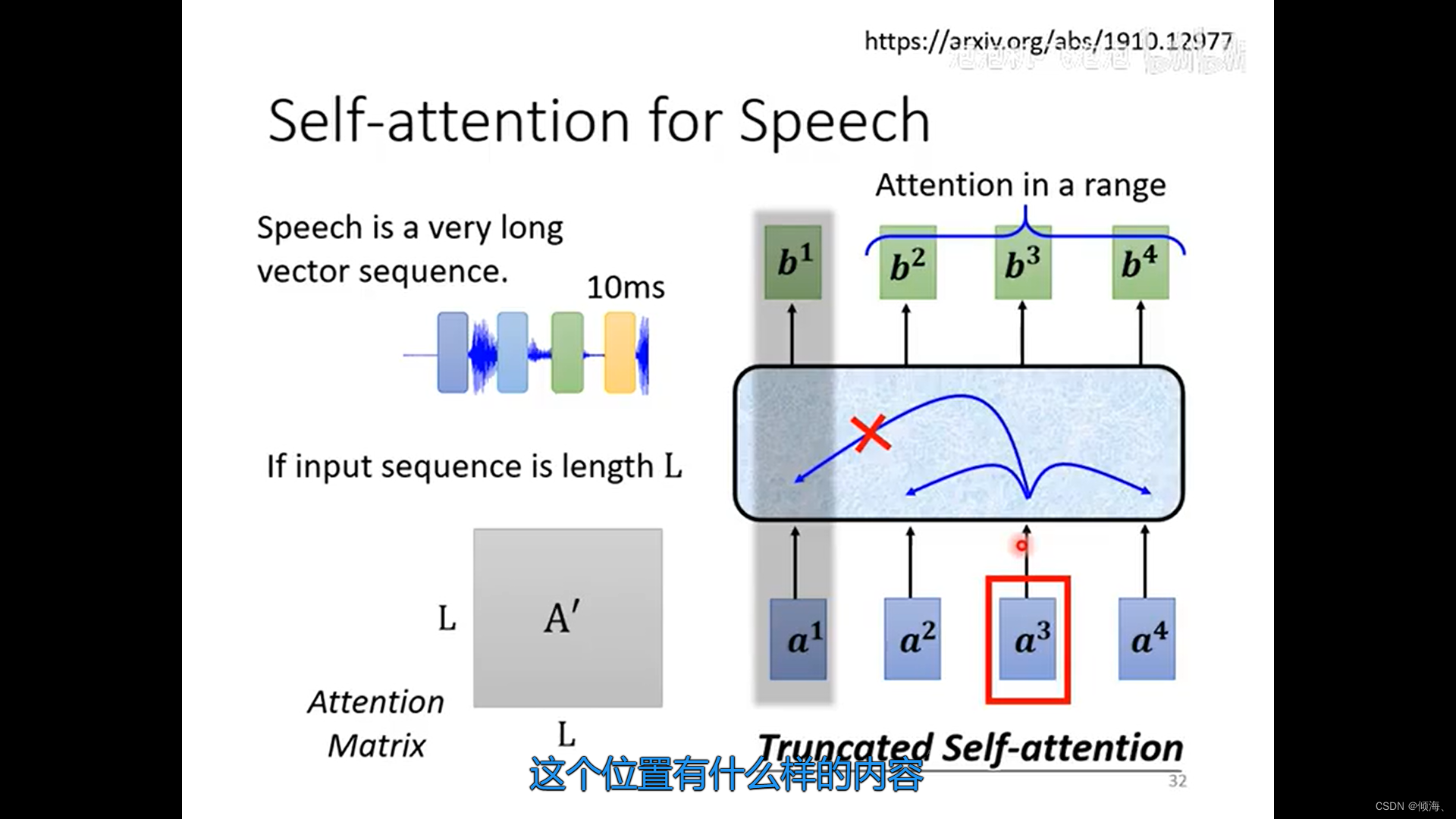
Truncated Self-attention
只看一个小范围。
影像处理
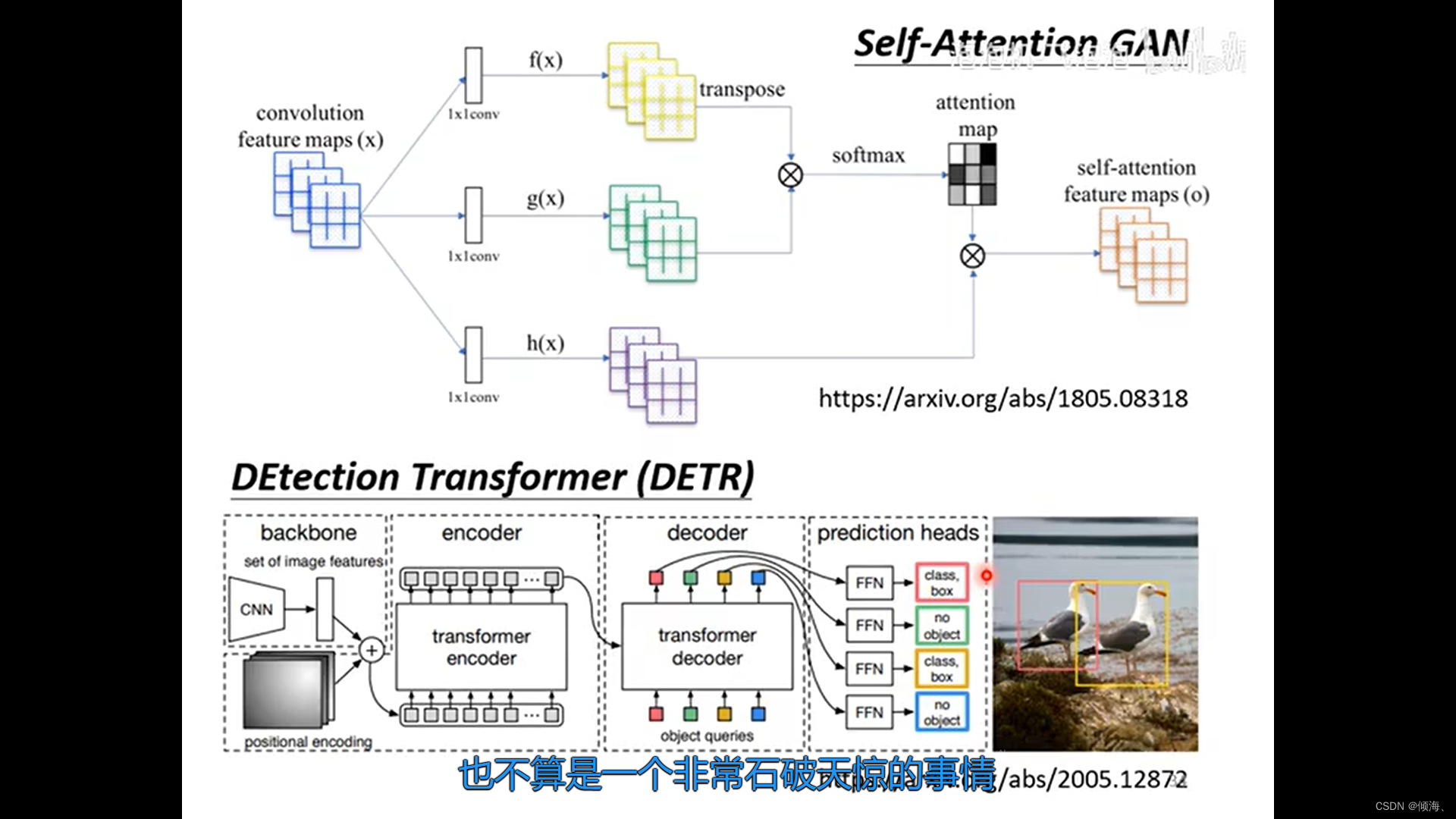
vs CNN

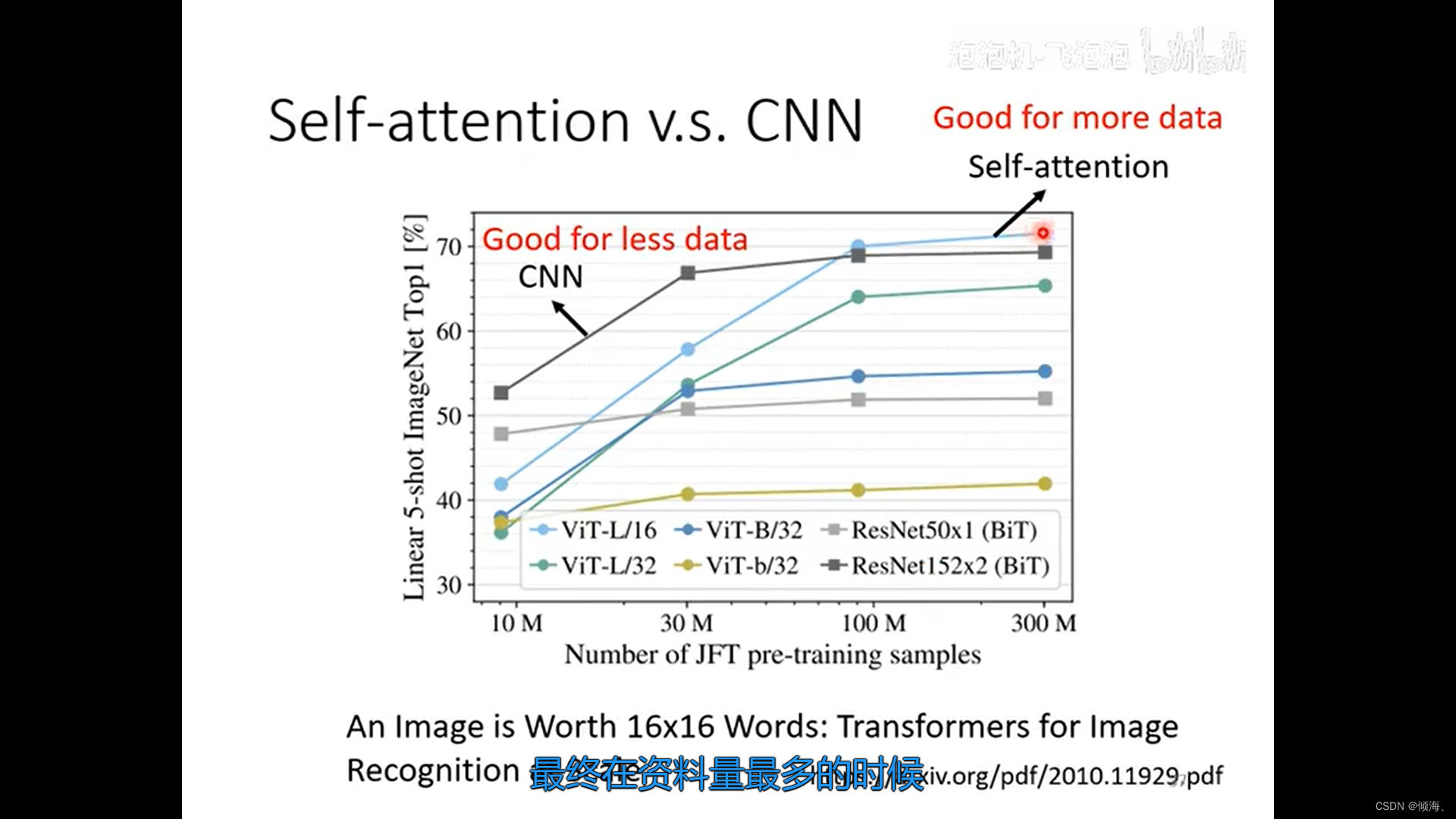
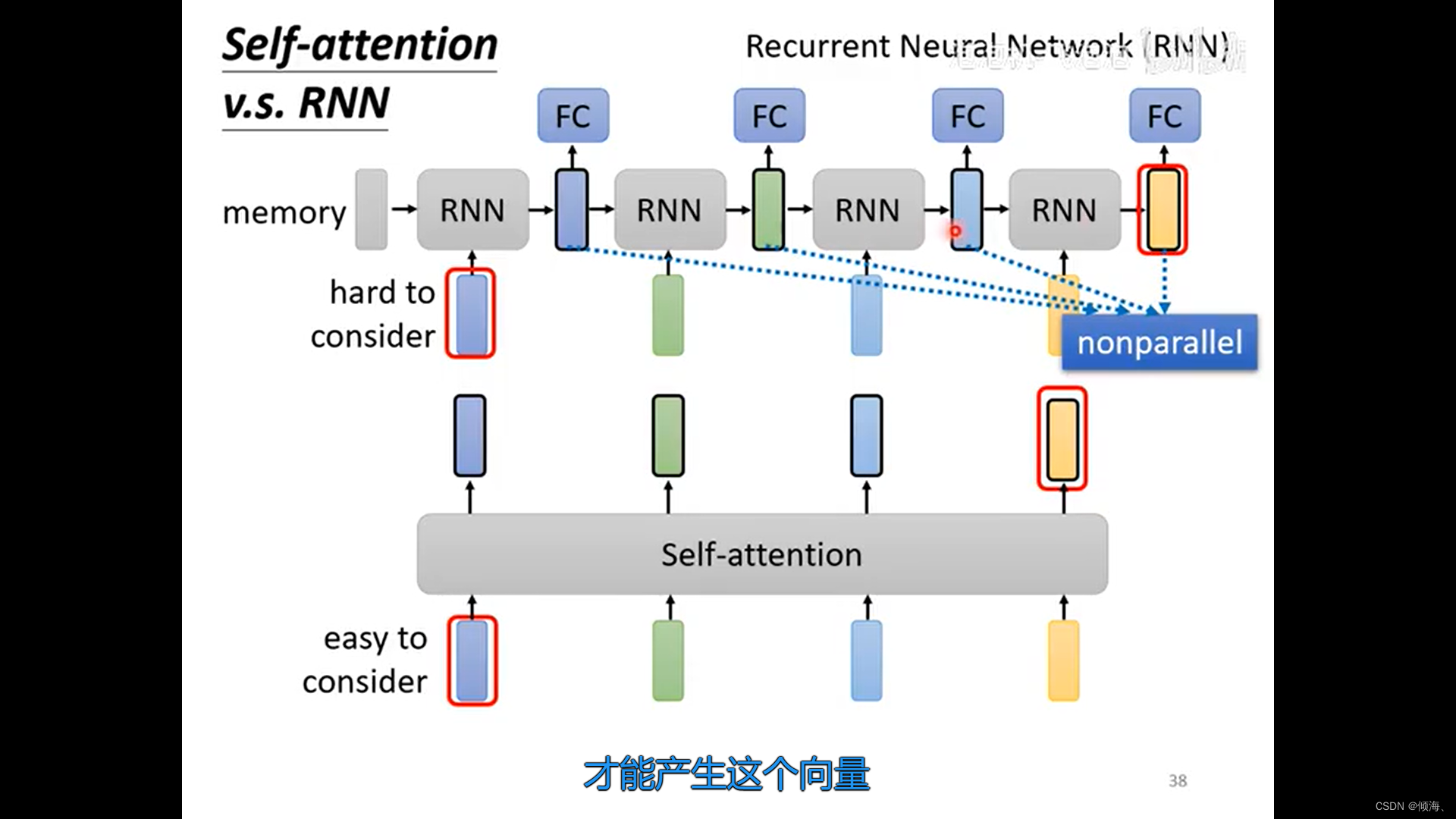
vs RNN
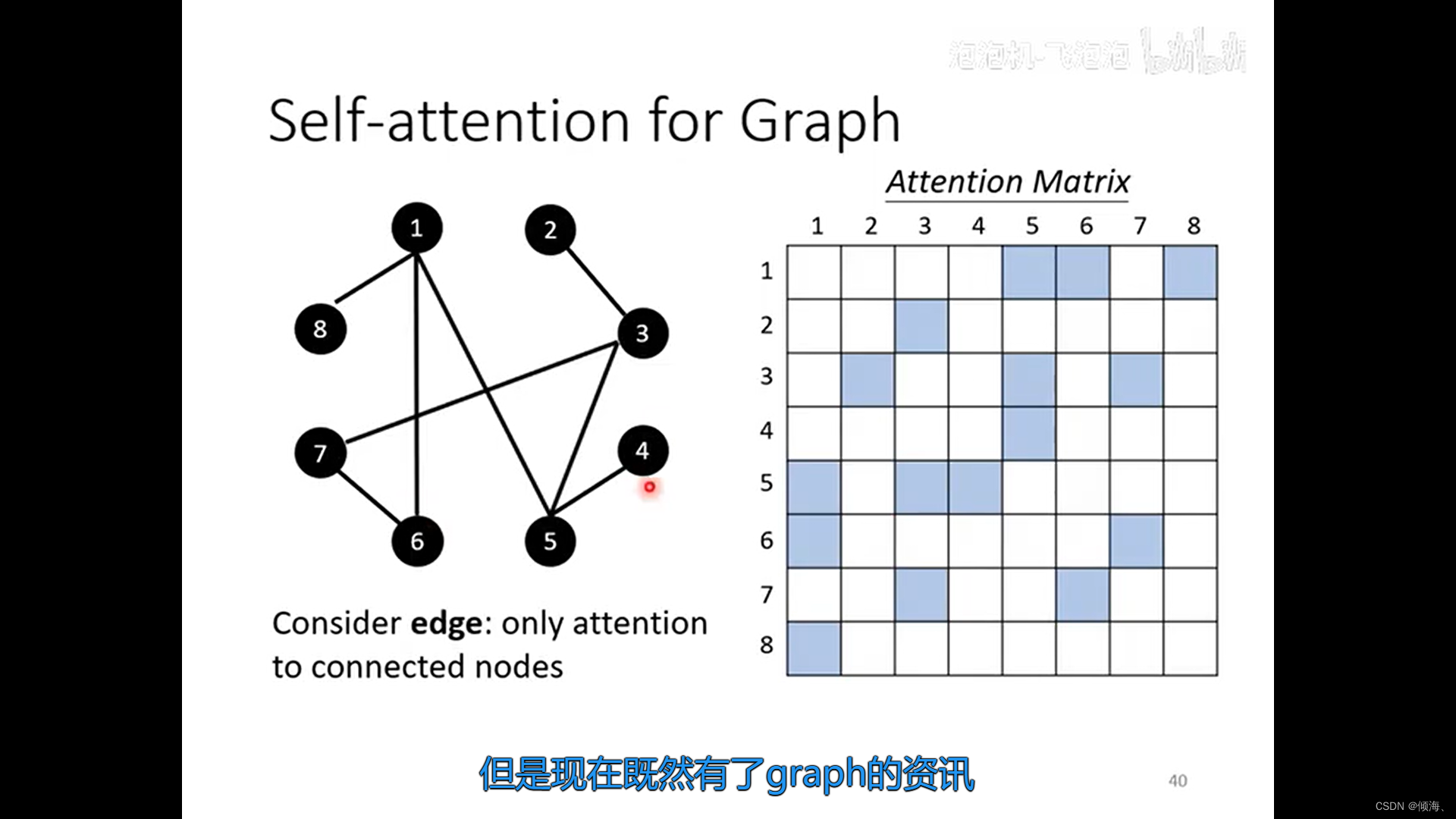
图上的应用
也可以不用softmax,relu也行。
https://arxiv.org/abs/2003.09229
只看一个小范围。
 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























