






最近发现华为NPU的生态里多了一个成员——MindIE,部分解决了大模型推理的问题,下面简要介绍下Mind华为昇腾NPU卡的生态。
1)华为NPU生态新增了MindIE,部分解决了大模型推理问题。
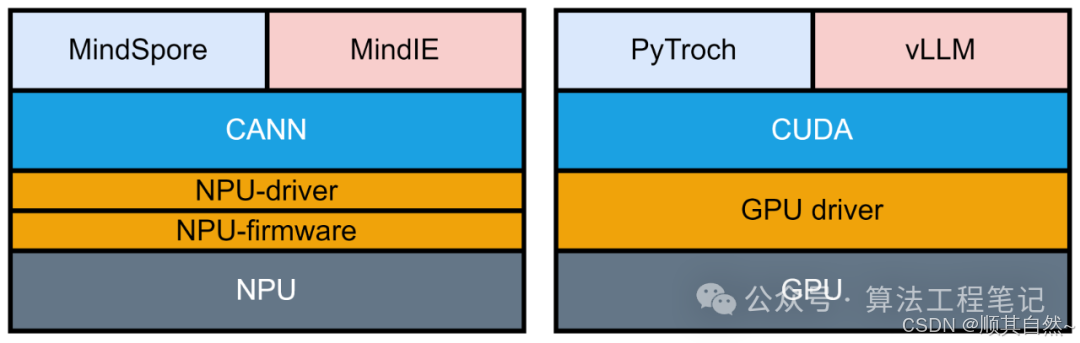
2)华为昇腾NPU与英伟达GPU生态层级对比:
CANN 对应 CUDA
MindSpore 对应 PyTorch
MindFormer 对应 Transformers
MindIE 对应 vLLM
3)MindIE推理性能测试(使用910B4卡):
并发数:40
首token平均延迟:66毫秒
每秒生成token数:约1200
单请求每秒生成token数:约30
模型:Qwen 1.5-14B-Chat
硬件:4卡910B4
测试条件:
测试结论:测试结果显示,MindIE的推理性能基本可以满足生产环境需求
基本概念
首先,在英伟达的生态中,有从底层到上层分别有CUDA、PyTorch、transformers、vLLM等常见库。对应的,在华为的生态中,分别有CANN、MindSpore、MindFormer、MindIE。具体对应关系见下图:
关于MindSpore、MindIE的详细介绍,分别见下面的图与链接:
MindSpore——https://www.mindspore.cn/
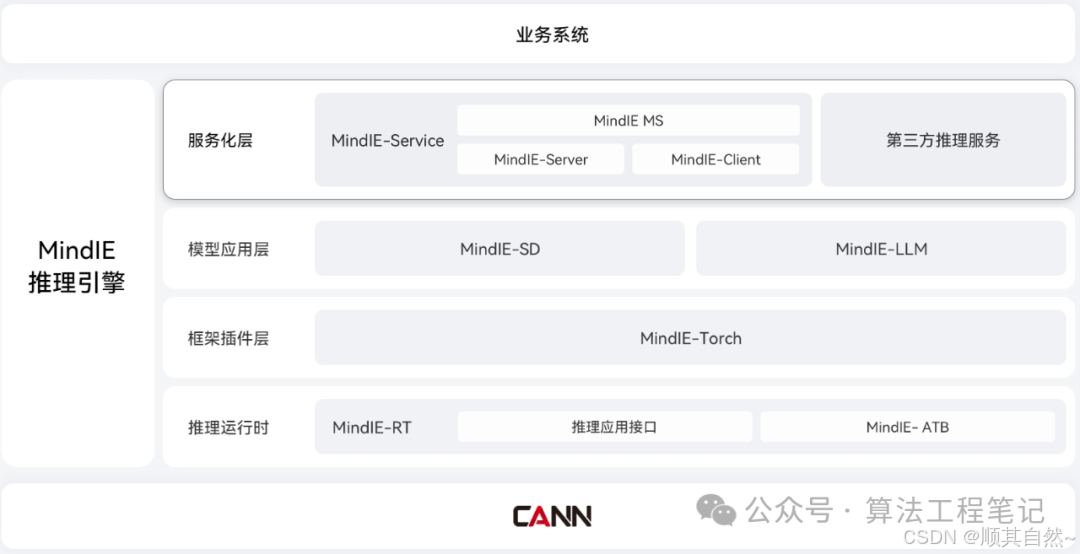
MindIE——https://www.hiascend.com/software/mindie
MindIE推理效果
虽然支持的模型不多,但是,得益于910B系列卡的强劲算力,配合MindIE框架做了下并发推理测试,具体结果如下:
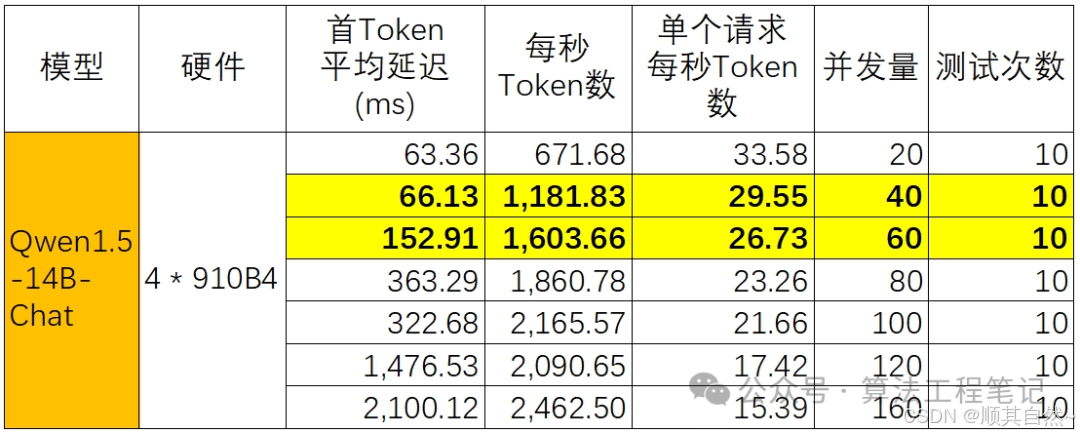
可以看到4卡910B4,跑Qwen1.5-14B-Chat模型,在40并发的情况下,首token平均延迟为66毫秒,每秒token生成数在1200左右,单个请求每秒生成token数约为30个,基本可以满足生产环境的需求。
参考资料:华鲲振宇AI最优解/ Ascend-FAQ的gitee: https://gitee.com/HKZY-FAE/ascend-faq/wikis

















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









