









为什么要做流失分析
关于用户留存有这样一个观点:如果将用户流失率降低5%,公司利润将提升25%-85%。
而流失分析的目的就是找出用户流失的主要原因,通过这些因素采取措施,从而达到降低流失率的目的。
数据特征
导入pandas库查看数据集的基本概况
import pandas as pd
import numpy as np
data = pd.read_csv(r"电信用户流失数据.csv",encoding='utf-8') #读取csv数据,设置编码方式
data.head() #查看前五行数据
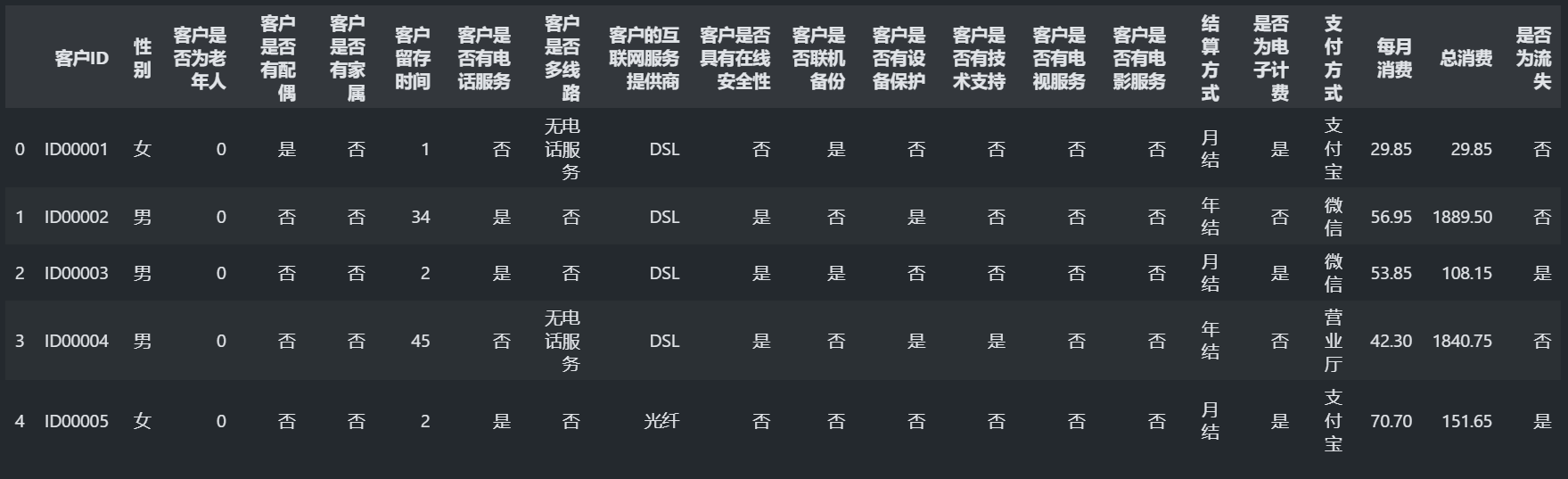
离散型和连续型是概率论和数理统计中常用的两种数据类型。 它们的区别在于数据的取值范围不同。 离散型数据是指只能取有限个或可数个数值的数据,例如掷骰子的点数、班级学生的人数等。 这些数据的取值通常是整数,且相邻两个数之间有间隔。 连续型数据则是指可以取任意实数值的数据,例如人的身高、温度等。 这些数据的取值范围是连续的,相邻两个数之间没有间隔。 在统计分析中,离散型数据通常使用频数和频率来描述,而连续型数据则使用概率密度函数和累积分布函数来描述。
从中可以看出该数据集总共有21个字段,其中"客户是否为老年人",“客户留存时间”,“每月消费”,“总消费”这四个字段为数值型的数据,但“客户是否为老年人”只有0和1两种值,也就是说该字段和大部分其他的字符型的字段一样,属于离散型的数据。而其他数值型的数据属于连续型的数据。
数据清洗
首先查看一下数据集有没有缺失值:
data.isnull().sum() #统计每个特征的缺失值个数
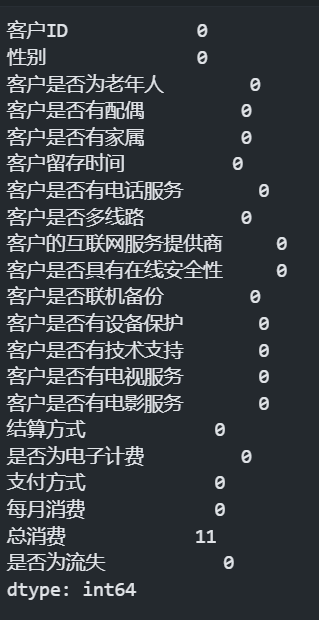
可以从输出中看出“总消费”字段存在11个缺失值,由于缺失值的个数很小,所以这里采取将缺失值所在的行删除的措施。
data = data.dropna() #删除缺失值所在行
data.isnull().sum() #统计每个特征的缺失值个数
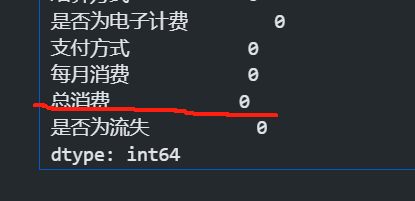
再次查看输出,发现已经没有缺失值了。
缺失值处理完之后查看数据的基本信息,看看有没有字段类型不正确,如果类型有问题,需要转换数据类型。
data.info() #查看数据信息
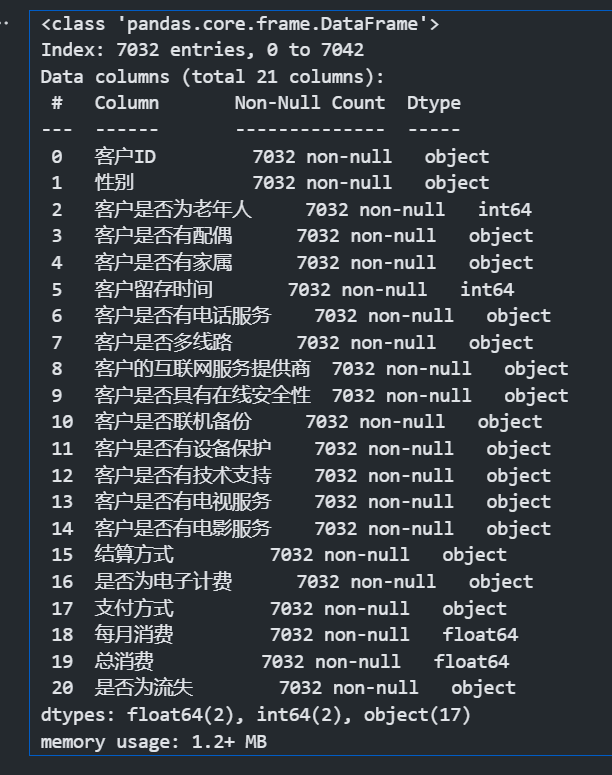
发现客户是否为老年人应该是分类特征
将该字段转换为字符型
data['客户是否为老年人'] = data['客户是否为老年人'].astype(str) #转为字符型
选取特征
首先用户id是用户的唯一标识,所以不能用作数据的特征,另外用户是否流失是预测的目标值,所以也不是数据的特征。
基于这两点我们可以把其他的字段当作数据的特征。
print('列名:\n', data.columns.values) #列名
print(' '*20)
print('特征个数:', len(data.columns)-1) #特征个数

基本数据分析
在投入模型训练前,最好先基于现有的数据,做一些简单的数据分析,可以帮我们更好的理解数据。(如果不想看这一段,可以跳到后面的模型训练部分)
- 计算流失比例
import matplotlib.pyplot as plt
fig = plt.figure() #画布
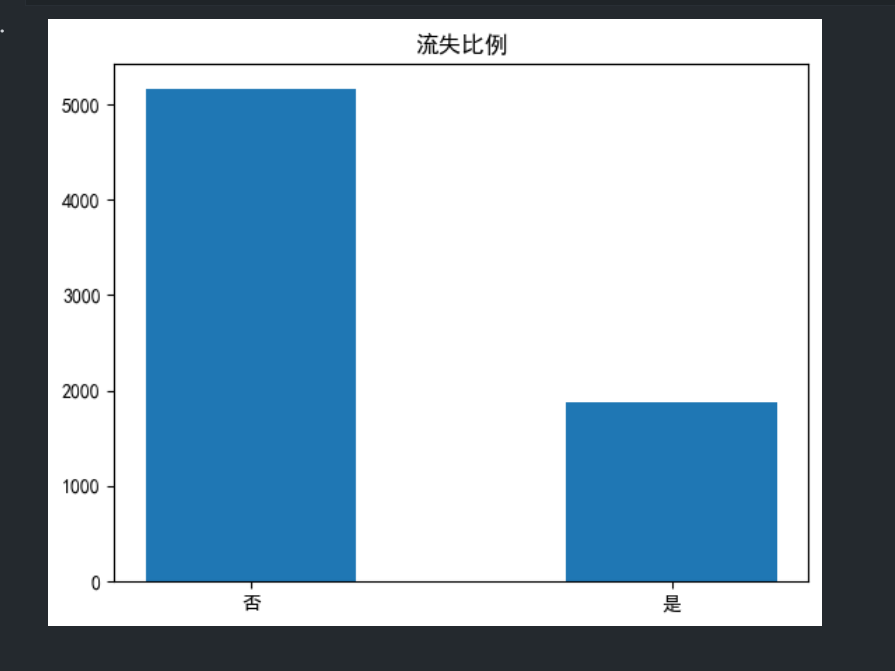
loss = data.groupby('是否为流失')['客户ID'].count() #对流失进行分组统计,计算流失与未流失人数
label = ['否','是'] #标签
plt.bar(label,loss,width=0.5) #绘制条形图,宽度为0.5
plt.title('流失比例') #标题
plt.show()
data['是否为流失'].value_counts(normalize=True) #统计流失与未流失个数,显示为频率
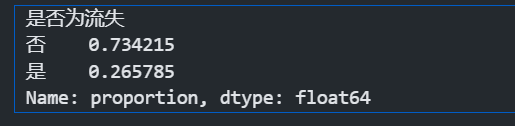
用户流失率大概为26%
- 数值型特征对于流失率的影响
该数据集中,有三个连续型的数值型数据,我们可以简单分析一下数值型数据对于流失率的影响。
fig = plt.figure(figsize=(10,10)) #设置图像大小
#客户留存时间对比
ax1 = fig.add_subplot(3,1,1) #子图1
sns.distplot(data_churn['客户留存时间'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['客户留存时间'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
#客户每月消费对比
ax2 = fig.add_subplot(3,1,2)#子图2
sns.distplot(data_churn['每月消费'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['每月消费'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
#客户总消费对比
ax3 = fig.add_subplot(3,1,3)#子图3
sns.distplot(data_churn['总消费'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['总消费'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
plt.subplots_adjust(wspace=0.1) #子图水平距离
plt.show()
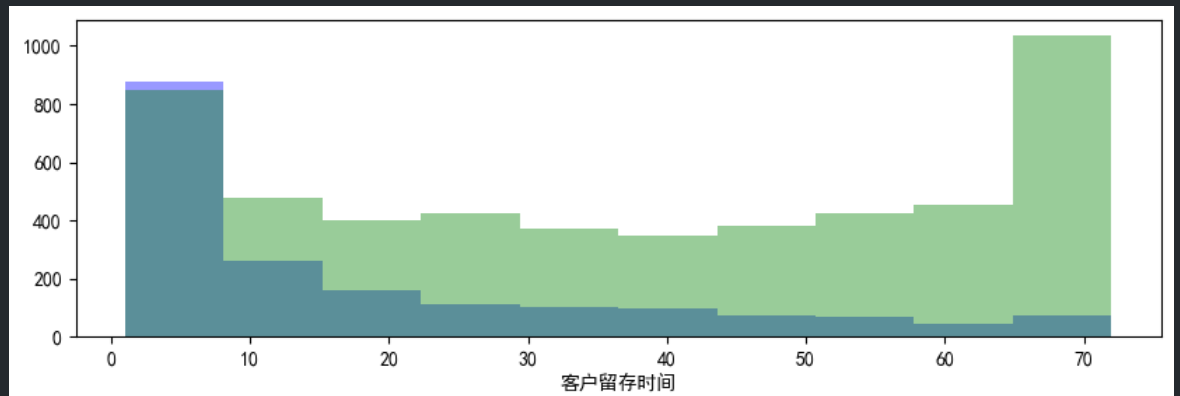
- 在这张图中,可以看出客户留存时间越长,客户的流失率越低。
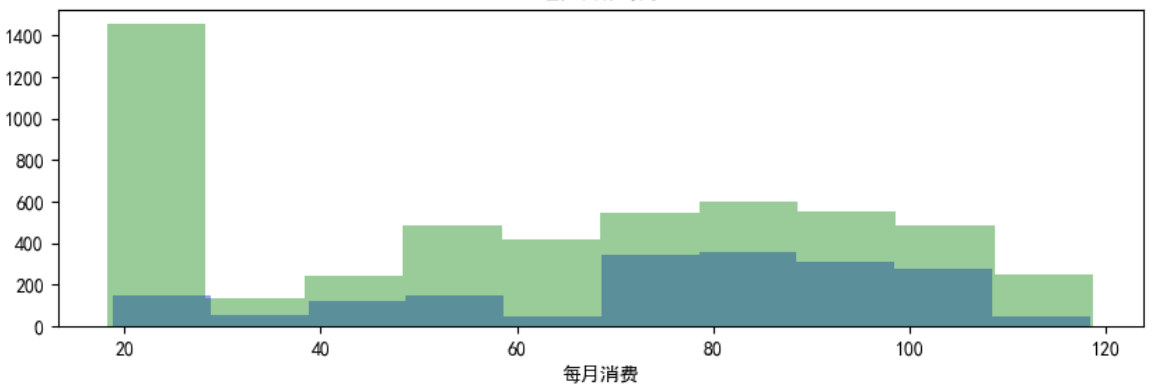
- 在这张图中可以看出,客户的每月消费情况和流失率基本没有关系。
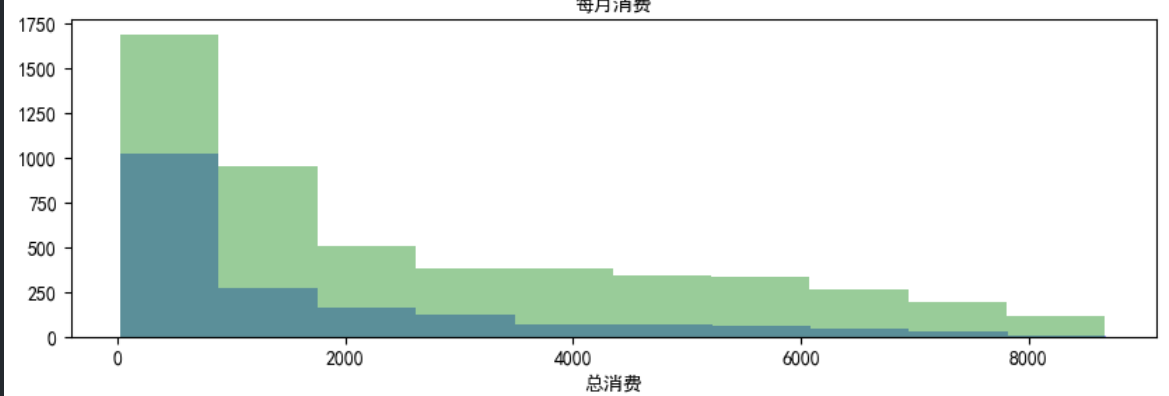
-
总消费的情况也是一样。
-
离散型的数据对于流失率的影响
分类特征很多,只选取其中6个特征作查看
#分类特征很多,只选取其中6个特征作查看
fig,axes = plt.subplots(2,3,figsize=(12,12)) #设置图像大小、子图排列方式,两行三列
axe=axes.ravel() #axes中解压所有子图数组
#流失与性别的关系
data0 = data.groupby(['性别','是否为流失'])['是否为流失'].count().unstack() #对性别和流失进行分组统计,计算性别,行转列
data0.plot(kind='bar',ax = axe[0],stacked='True') #绘制柱状图,位置是第一个子图,进行堆叠
#流失与老年人的关系
data1 = data.groupby(['客户是否为老年人','是否为流失'])['是否为流失'].count().unstack()
data1.plot(kind='bar',ax = axe[1],stacked='True') #绘制柱状图,位置是第二个子图,进行堆叠
#流失与是否有配偶的关系
data2 = data.groupby(['客户是否有配偶','是否为流失'])['是否为流失'].count().unstack()
data2.plot(kind='bar',ax = axe[2],stacked='True') #绘制柱状图,位置是第三个子图,进行堆叠
#流失与是否有设备保护的关系
data3 = data.groupby(['客户是否有设备保护','是否为流失'])['是否为流失'].count().unstack()
data3.plot(kind='bar',ax = axe[3],stacked='True') #绘制柱状图,位置是第四个子图,进行堆叠
#流失与结算方式的关系
data4 = data.groupby(['结算方式','是否为流失'])['是否为流失'].count().unstack()
data4.plot(kind='bar',ax = axe[4],stacked='True') #绘制柱状图,位置是第五个子图,进行堆叠
#流失与客户的互联网服务提供商的关系
data5 = data.groupby(['客户的互联网服务提供商','是否为流失'])['是否为流失'].count().unstack()
data5.plot(kind='bar',ax = axe[5],stacked='True') #绘制柱状图,位置是第六个子图,进行堆叠
plt.subplots_adjust(hspace=0.6) #子图竖直距离
plt.show()
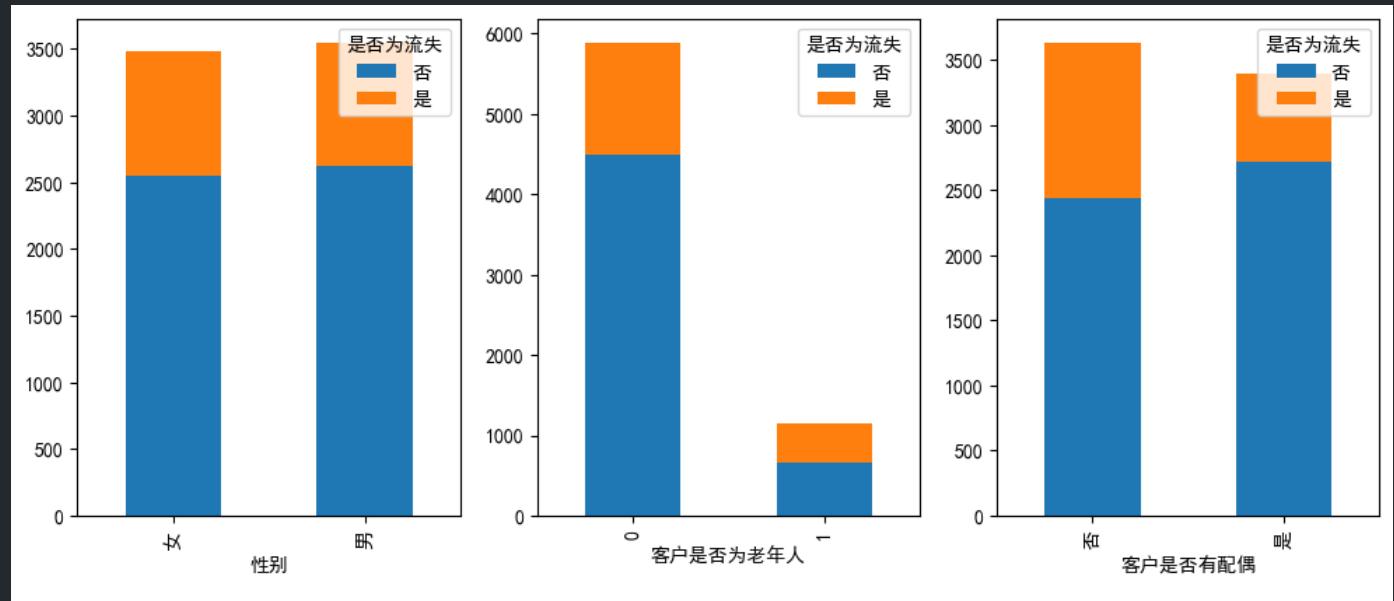
从这张图中可以看出,性别和客户是否有配偶两个特征与整体流失率没有关系
但是可以看出,老年人的群体的流失率比非老年人群体的流失率高。
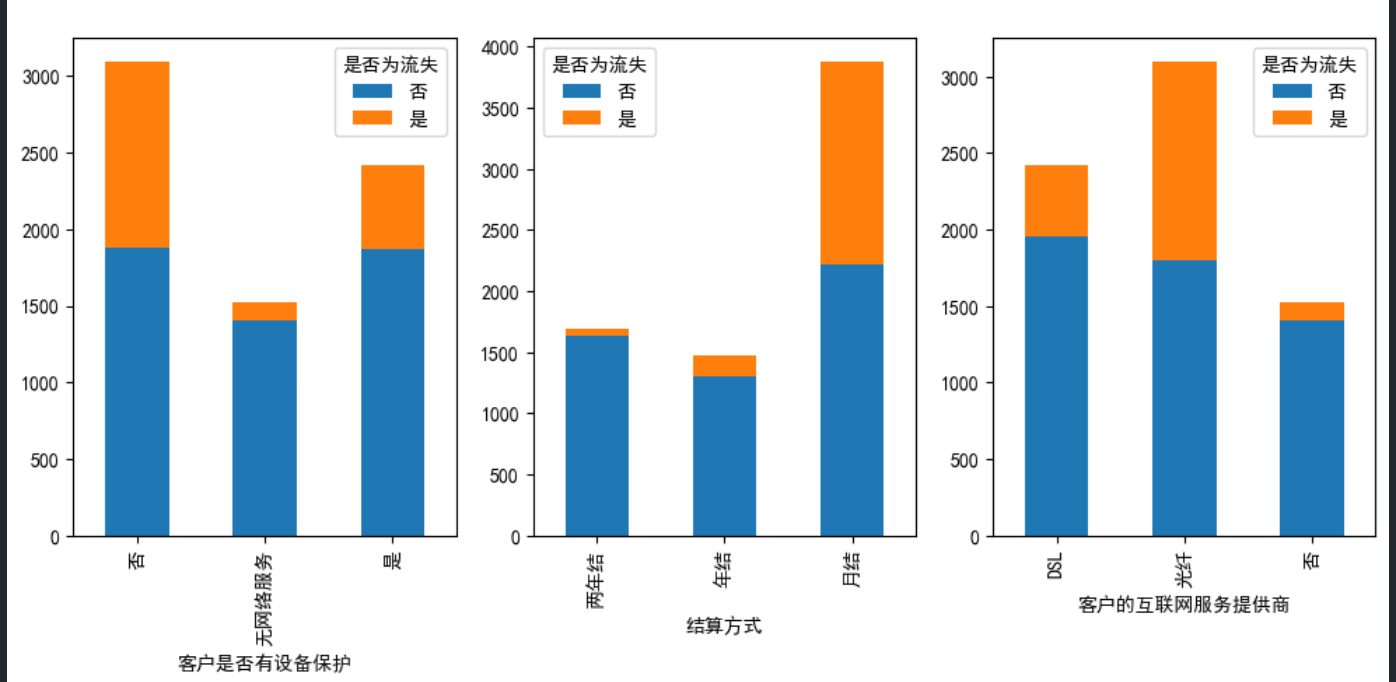
从这张图中可以看出,月结用户和不购买设备保护服务的流失率较高,光纤用户的流失率也较高。
拆分特征和标签
基本信息的可视化分析告一段落,可以进行预测任务了,对于用户留存分析这一任务,我们预测的首要目标是为了找出影响用户留存的最主要的因素。
首先进行拆分特征和标签
#特征
#特征是第二列至倒数第二列
x = data.iloc[:,1:-1] #特征。按行列索引,取所有行、第二列至倒数第二列
x[:5]
第一列和最后一列是id和是否流失,都不是特征,所以不需要。
y = data['是否为流失'] #标签。取最后一列,标签列
y[:5]
是否为流失是标签列,变量命名为y。
分割数据集
将数据集分割为训练集和测试集
from sklearn.model_selection import train_test_split
#将数据分割为训练集,测试集,训练集标签,测试集标签
X_train,X_test,y_train,y_test = train_test_split(x, y, test_size=0.2) #测试集占比20%
特征编码
由于模型不能识别字符型的数据,所以我们对字符型的数据进行编码
这里对标签列采用标签编码,对其他的特征列使用独热编码
#特征编码。分别对训练集测试集编码,防止数据泄露
#DictVectorizer进行独热编码时,不会将数值型编码,而是保留
from sklearn.preprocessing import LabelEncoder #标签编码器
from sklearn.feature_extraction import DictVectorizer #独热编码器
dv = DictVectorizer() #独热编码
le = LabelEncoder() #标签编码
dv_fit = dv.fit(X_train.to_dict(orient='records')) #转为dict,训练
le_fit = le.fit(y_train) #训练
X_train = dv_fit.transform(X_train.to_dict(orient='records')) #训练集转换
X_test = dv_fit.transform(X_test.to_dict(orient='records')) #测试集转换
y_train = le_fit.transform(y_train) #训练集转换
y_test = le_fit.transform(y_test) #测试集转换
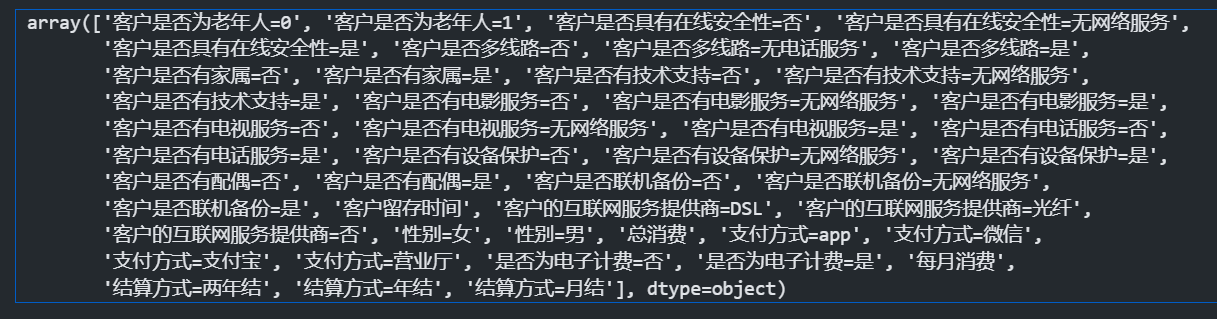
这里可以查看以下所有编码过的特征列的名称
dv.get_feature_names_out() #获取特征名称
算法分类
这里采用随机森林算法
#随机森林分类
from sklearn.ensemble import RandomForestClassifier
#随机森林分类器
clf = RandomForestClassifier(
min_samples_leaf=20, #每个节点的最小样本数
max_depth=10, #最大树深
n_estimators=150, #弱分类器的个数
random_state=42 #随机种子固定
)
clf.fit(X_train,y_train) #训练分类器
等模型拟合完毕,就可以使用测试集的数据查看模型的得分了。
#准确率
print(clf.score(X_train,y_train)) #训练集准确率
print(clf.score(X_test,y_test)) #测试集准确率
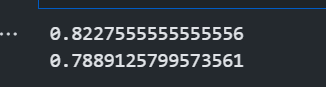
该模型在测试集上的准确率为0.78
可以通过模型预测的预测值和真实值建立混淆矩阵,并用热力图展示出来。
#预测
y_pred = clf.predict(X_test) #预测测试集标签
y_pred
#混淆矩阵
from collections import Counter
import seaborn as sns
from sklearn.metrics import confusion_matrix
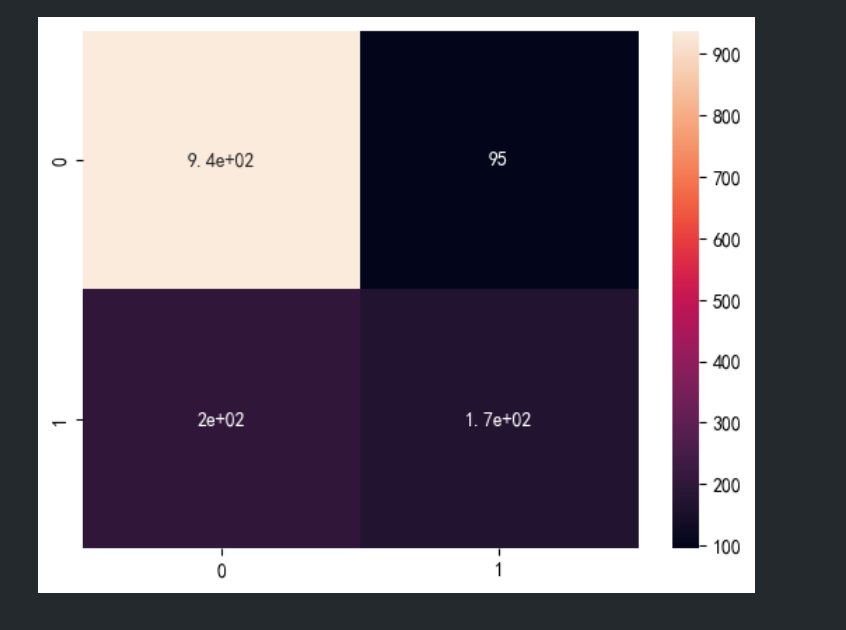
print("真实值:",Counter(y_test)) #真实标签
print("预测值:",Counter(y_pred)) #预测标签
print ("总体准确率:\n",round(sum(y_test==y_pred) / len(y_test),4)) #计算准确率
confmat= confusion_matrix(y_true=y_test,y_pred=y_pred) #输出混淆矩阵
sns.heatmap(confmat,annot=True) #绘制热度图
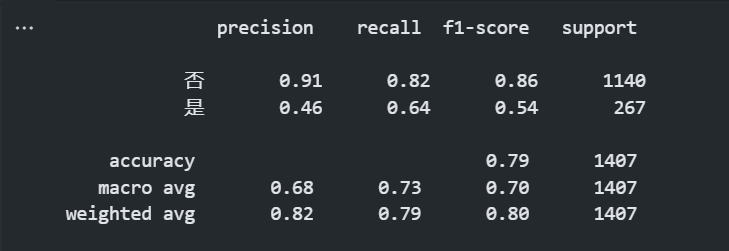
- 输出模型的评估报告
from sklearn.metrics import classification_report
print(classification_report(y_pred,y_test,target_names=['否','是'])) #输出模型评估报告
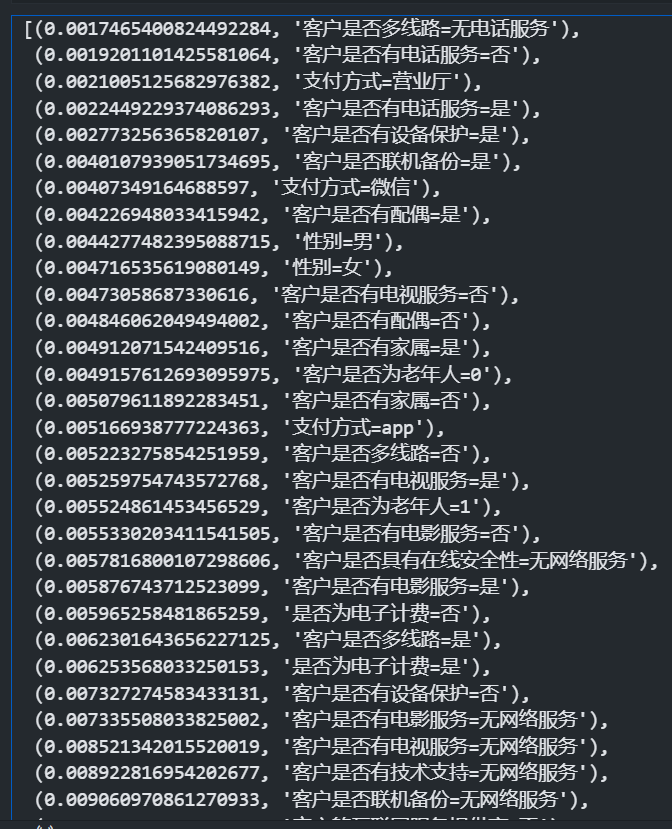
查看特征重要性
还记的我们的最终目的吗?是找到影响流失率的关键因素。
可以使用feature_importances_ 查看特征重要性,来达到这一目的。
这里对特征重要性做了以下处理,和特征名称做了合并,用于可视化。
#特征排序
importance = clf.feature_importances_ #特征重要性
indices = np.argsort(importance) #获取排序索引
#indices
importance_sort = clf.feature_importances_[indices] #特征重要性按索引排序
feature_names_sort = np.array(dv.get_feature_names_out())[indices] #特征名转化为array格式后排序
list(zip(importance_sort,feature_names_sort))
我们把特征重要性小于0.01的忽略,找出大于0.01的所有特征列,并作可视化。
#特征筛选
importance_select = [] #特征重要性
feature_select = [] #特征名
#获取筛选后的特征名和特征重要性
for i,j in list(zip(importance_sort,feature_names_sort)):
#特征重要性是否大于0.01
if i>0.01:
importance_select.append(i) #添加到importance_select中
feature_select.append(j) #添加到feature_select中
else:
continue
print(importance_select)
print(feature_select)
#特征可视化
y_pos = np.arange(len(feature_select)) #特征个数的排列
fig = plt.figure(figsize=(12,12)) #设置图像大小
plt.barh(y_pos, importance_select, align='center') #条形图
plt.yticks(y_pos, feature_select) #y轴刻度
plt.xlabel('特征') #x轴标签
plt.xlim(0,1) #x轴坐标范围
plt.title('特征重要性') #标题
plt.show()
plt.savefig("out3.jpg")
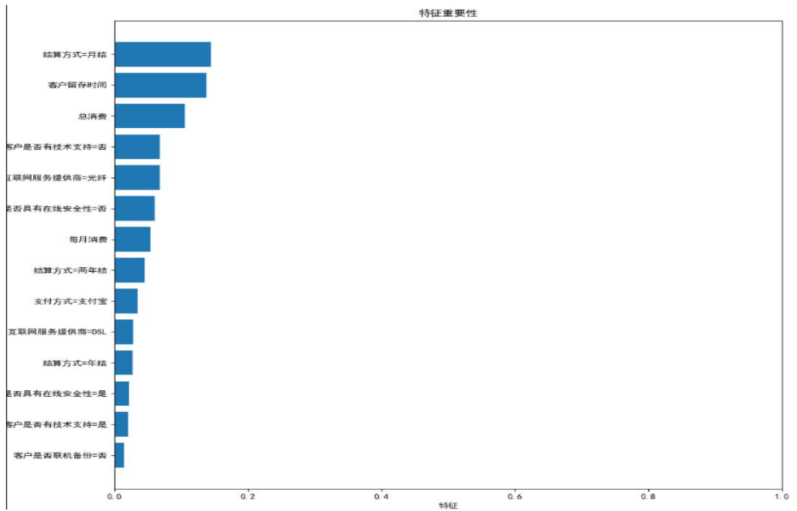
该图就是特征重要性从高到低排序的结果了,可以看到影响客户流失率最主要的几个因素。
源码放在下面
import numpy as np
import pandas as pd
pd.set_option('display.max_columns', None) #显示所有列
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文
import seaborn as sns
import warnings
warnings.filterwarnings("ignore") #忽略警告
# 数据读取
data = pd.read_csv("电信用户流失数据.csv")
print("---------------------------数据概览------------------------------------")
print(data.head(5))
print("---------------------------每个特征的缺失值个数------------------------------------")
print(data.isnull().sum())
data = data.dropna() #删除缺失值所在行
print("---------------------------删除行之后的缺失值个数------------------------------------")
print(data.isnull().sum())
print("---------------------------查看数据信息------------------------------------")
print(data.info())
#特征类型转换
data['客户是否为老年人'] = data['客户是否为老年人'].astype(str) #转为字符型
print("---------------------------类型转换的数据信息------------------------------------")
print(data.info())
print("---------------------------查看数据统计量------------------------------------")
print(data.describe())
print("---------------------------查看特征名和特征个数------------------------------------")
print('列名:\n', data.columns.values) #列名
print(' '*20)
print('特征个数:', len(data.columns)-1) #特征个数
fig = plt.figure() #画布
loss = data.groupby('是否为流失')['客户ID'].count() #对流失进行分组统计,计算流失与未流失人数
label = ['否','是'] #标签
plt.bar(label,loss,width=0.5) #绘制条形图,宽度为0.5
plt.title('流失比例') #标题
plt.savefig("./churn_rate.jpg")
print("---------------------------计算流失比例------------------------------------")
print(data['是否为流失'].value_counts(normalize=True))
#数值型特征的客户对比
data_churn = data[data['是否为流失']=='是'] #流失
data_retention = data[data['是否为流失']=='否'] #未流失
#三个数值特征可视化
fig = plt.figure(figsize=(10,10)) #设置图像大小
#客户留存时间对比
ax1 = fig.add_subplot(3,1,1) #子图1
sns.distplot(data_churn['客户留存时间'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['客户留存时间'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
#客户每月消费对比
ax2 = fig.add_subplot(3,1,2)#子图2
sns.distplot(data_churn['每月消费'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['每月消费'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
#客户总消费对比
ax3 = fig.add_subplot(3,1,3)#子图3
sns.distplot(data_churn['总消费'],bins=10,hist=True,kde=False,color='b') #流失客户直方图,箱数设为10,不绘制核密度图,颜色为蓝色
sns.distplot(data_retention['总消费'],bins=10,hist=True,kde=False,color='g') #未流失客户直方图,箱数设为10,不绘制核密度图,颜色为绿色
plt.subplots_adjust(wspace=0.1) #子图水平距离
plt.savefig("./num_type_feature_churn_rate.jpg")
print("客户留存时间越长,越不容易流失;每月消费20到30月的客户很多,客户是否流失与消费金额关系不大。")
#分类特征很多,只选取其中6个特征作查看
fig,axes = plt.subplots(2,3,figsize=(12,12)) #设置图像大小、子图排列方式,两行三列
axe=axes.ravel() #axes中解压所有子图数组
#流失与性别的关系
data0 = data.groupby(['性别','是否为流失'])['是否为流失'].count().unstack() #对性别和流失进行分组统计,计算性别,行转列
data0.plot(kind='bar',ax = axe[0],stacked='True') #绘制柱状图,位置是第一个子图,进行堆叠
#流失与老年人的关系
data1 = data.groupby(['客户是否为老年人','是否为流失'])['是否为流失'].count().unstack()
data1.plot(kind='bar',ax = axe[1],stacked='True') #绘制柱状图,位置是第二个子图,进行堆叠
#流失与是否有配偶的关系
data2 = data.groupby(['客户是否有配偶','是否为流失'])['是否为流失'].count().unstack()
data2.plot(kind='bar',ax = axe[2],stacked='True') #绘制柱状图,位置是第三个子图,进行堆叠
#流失与是否有设备保护的关系
data3 = data.groupby(['客户是否有设备保护','是否为流失'])['是否为流失'].count().unstack()
data3.plot(kind='bar',ax = axe[3],stacked='True') #绘制柱状图,位置是第四个子图,进行堆叠
#流失与结算方式的关系
data4 = data.groupby(['结算方式','是否为流失'])['是否为流失'].count().unstack()
data4.plot(kind='bar',ax = axe[4],stacked='True') #绘制柱状图,位置是第五个子图,进行堆叠
#流失与客户的互联网服务提供商的关系
data5 = data.groupby(['客户的互联网服务提供商','是否为流失'])['是否为流失'].count().unstack()
data5.plot(kind='bar',ax = axe[5],stacked='True') #绘制柱状图,位置是第六个子图,进行堆叠
plt.subplots_adjust(hspace=0.6) #子图竖直距离
plt.savefig("./class_feature_churn_rate.jpg")
print("性别与流失的关系不大;老年人更容易流失;没有配偶更容易流失;月结客户更容易流失;使用光纤的客户更容易流失")
#特征
#特征是第二列至倒数第二列
x = data.iloc[:,1:-1] #特征。按行列索引,取所有行、第二列至倒数第二列
print("---------------------------特征列概览------------------------------------")
print(x[:5])
#标签
#最后一列为标签
y = data['是否为流失'] #标签。取最后一列,标签列
print("---------------------------标签列概览------------------------------------")
print(y[:5])
#分割数据集
from sklearn.model_selection import train_test_split
#将数据分割为训练集,测试集,训练集标签,测试集标签
X_train,X_test,y_train,y_test = train_test_split(x, y, test_size=0.2, random_state=42) #测试集占比20%,设置随机种子为42
#特征编码。分别对训练集测试集编码,防止数据泄露
#DictVectorizer进行独热编码时,不会将数值型编码,而是保留
from sklearn.preprocessing import LabelEncoder #标签编码器
from sklearn.feature_extraction import DictVectorizer #独热编码器
dv = DictVectorizer() #独热编码
le = LabelEncoder() #标签编码
dv_fit = dv.fit(X_train.to_dict(orient='records')) #转为dict,训练
le_fit = le.fit(y_train) #训练
X_train = dv_fit.transform(X_train.to_dict(orient='records')) #训练集转换
X_test = dv_fit.transform(X_test.to_dict(orient='records')) #测试集转换
y_train = le_fit.transform(y_train) #训练集转换
y_test = le_fit.transform(y_test) #测试集转换
#查看特征
print("---------------------------查看特征------------------------------------")
print(dv.get_feature_names_out())
#随机森林分类
print("---------------------------随机森林算法训练开始------------------------------------")
from sklearn.ensemble import RandomForestClassifier
#随机森林分类器
clf = RandomForestClassifier(
min_samples_leaf=20, #每个节点的最小样本数
max_depth=10, #最大树深
n_estimators=150, #弱分类器的个数
random_state=42 #随机种子固定
)
clf.fit(X_train,y_train) #训练分类器
print("---------------------------训练结束------------------------------------")
print("---------------------------查看准确率------------------------------------")
#准确率
print("训练集准确率:",clf.score(X_train,y_train)) #训练集准确率
print("测试集准确率",clf.score(X_test,y_test)) #测试集准确率
#预测
y_pred = clf.predict(X_test) #预测测试集标签
print("---------------------------预测测试集标签------------------------------------")
print(y_pred)
print("---------------------------评估模型------------------------------------")
#混淆矩阵
from collections import Counter
import seaborn as sns
from sklearn.metrics import confusion_matrix
print("真实值:",Counter(y_test)) #真实标签
print("预测值:",Counter(y_pred)) #预测标签
print ("总体准确率:\n",round(sum(y_test==y_pred) / len(y_test),4)) #计算准确率
confmat= confusion_matrix(y_true=y_test,y_pred=y_pred) #输出混淆矩阵
sns.heatmap(confmat,annot=True) #绘制热度图
plt.savefig("./metric_model.jpg")
print("---------------------------生成模型报告------------------------------------")
#模型报告
from sklearn.metrics import classification_report
print(classification_report(y_pred,y_test,target_names=['否','是'])) #输出模型评估报告
print("---------------------------计算特征重要性------------------------------------")
#特征排序
importance = clf.feature_importances_ #特征重要性
indices = np.argsort(importance) #获取排序索引
#indices
importance_sort = clf.feature_importances_[indices] #特征重要性按索引排序
feature_names_sort = np.array(dv.get_feature_names_out())[indices] #特征名转化为array格式后排序
#特征筛选
importance_select = [] #特征重要性
feature_select = [] #特征名
#获取筛选后的特征名和特征重要性
for i,j in list(zip(importance_sort,feature_names_sort)):
#特征重要性是否大于0.01
if i>0.01:
importance_select.append(i) #添加到importance_select中
feature_select.append(j) #添加到feature_select中
else:
continue
#特征可视化
y_pos = np.arange(len(feature_select)) #特征个数的排列
fig = plt.figure(figsize=(12,12)) #设置图像大小
plt.barh(y_pos, importance_select, align='center') #条形图
plt.yticks(y_pos, feature_select) #y轴刻度
plt.xlabel('特征') #x轴标签
plt.xlim(0,1) #x轴坐标范围
plt.title('特征重要性') #标题
plt.savefig("./importance_feature.jpg")
print("---------------------------可视化完成 图片已保存------------------------------------")
















 3396
3396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











