







前言
客户流失预警
提示:以下是本篇文章正文内容,下面案例可供参考
一、 数据清洗与格式转换
import warnings
warnings.filterwarnings('ignore') #忽视
import pandas as pd
import numpy as np
# 加载数据集
churn_df = pd.read_csv('churn.csv')
col_names = churn_df.columns.tolist() #所有的列展示出来
print("Column names:")
print(col_names)
to_show = col_names[:6] + col_names[-6:] #前6列特征和后6列特征
print("\nSample data:")
churn_df[to_show].head(6)
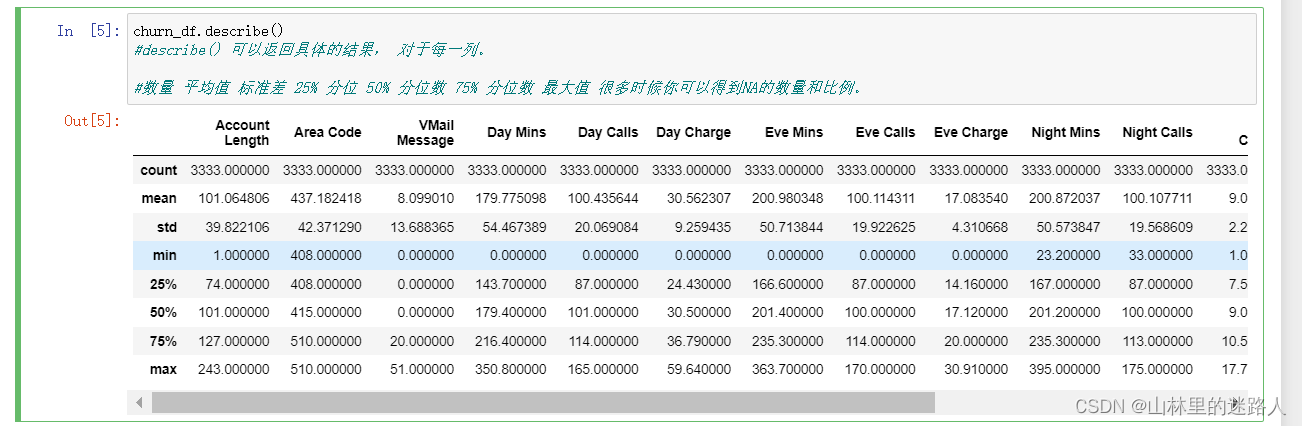
churn_df.describe()
#describe() 可以返回具体的结果, 对于每一列。
#数量 平均值 标准差 25% 分位 50% 分位数 75% 分位数 最大值 很多时候你可以得到NA的数量和比例。
二、 探索性数据分析
#我们先来看一下流失比例, 以及关于打客户电话的个数分布
import matplotlib.pyplot as plt # 仿真
%matplotlib inline
fig = plt.figure()
fig.set(alpha=0.3) # 设定图表颜色alpha参数
#subplot2grid(shape , loc )
plt.subplot2grid((1,2),(0,0))# 图像几行几列,从第0行第0列,
# bar:条形直方图
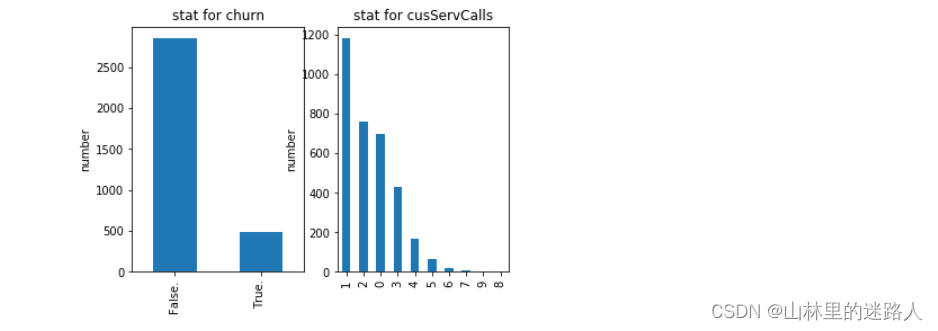
churn_df['Churn?'].value_counts().plot(kind='bar') #把用户是否流失分组起来,流失的有多少人,没有流失的有多少人
plt.title("stat for churn") # 设置标签/label
plt.ylabel("number") #流失与否的数量,一共3333行,没有流失的约占2700 ,流失的占500左右
plt.subplot2grid((1,2),(0,1))
churn_df[u'CustServ Calls'].value_counts().plot(kind='bar') # 客服电话, 客户打电话投诉多那流失率可能会大
plt.title("stat for cusServCalls") # 标题
plt.ylabel(u"number") #客户打1个客服电话的有1400个左右,客户.....总计加起来有3333个
plt.show()
import matplotlib.pyplot as plt
%matplotlib inline
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((1,3),(0,0)) # 在一张大图里分列几个小图
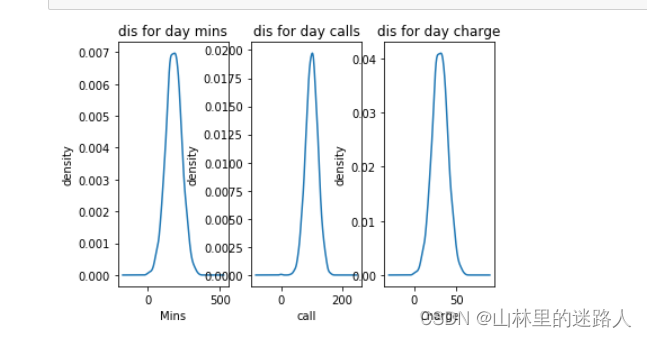
churn_df['Day Mins'].plot(kind='kde') # 白天通话分钟数,图用的kde的图例
plt.xlabel(u"Mins")# 横轴是分钟数
plt.ylabel(u"density") # density:密度
plt.title(u"dis for day mins") #标题
plt.subplot2grid((1,3),(0,1))
churn_df['Day Calls'].plot(kind='kde')# 白天打电话个数
plt.xlabel(u"call")# 客户打电话个数
plt.ylabel(u"density") #密度
plt.title(u"dis for day calls") #标题
plt.subplot2grid((1,3),(0,2))
churn_df['Day Charge'].plot(kind='kde') # 白天收费情况
plt.xlabel(u"Charge")# 横轴是白天收费情况
plt.ylabel(u"density") #密度
plt.title(u"dis for day charge")
plt.show()
#import matplotlib.pyplot as plt
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
#查看流失与国际漫游之间的关系
int_yes = churn_df['Churn?'][churn_df['Int\'l Plan'] == 'yes'].value_counts() # 分组,yes:参与了有国际漫游需求的统计出来
int_no = churn_df['Churn?'][churn_df['Int\'l Plan'] == 'no'].value_counts() #分组:no:没有参与国际漫游的统计出来
#用DataFrame做图例上的标签 ,在右上角
df_int=pd.DataFrame({u'int plan':int_yes, u'no int plan':int_no})
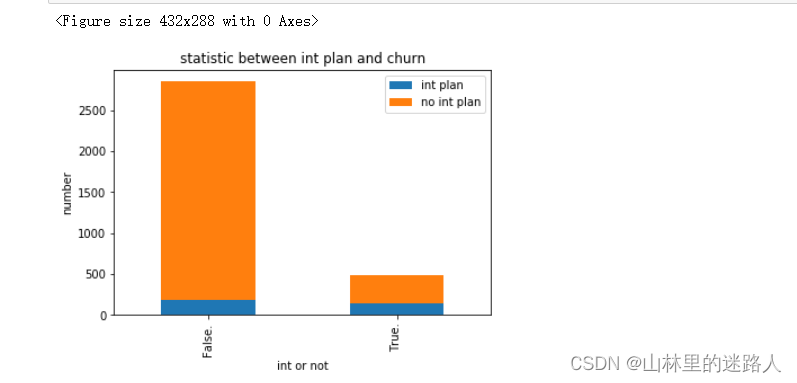
df_int.plot(kind='bar', stacked=True)
plt.title(u"statistic between int plan and churn")
plt.xlabel(u"int or not")
plt.ylabel(u"number")
plt.show()
# 下图中,原始数据有3333行,False:对于没有流失的用户中,有2700个,其中参与了有100个左右,没有参与的2600多个
#True:对于真正流失的用户有400个左右,参与了国际漫游的有100个,没有参与漫游的用300个
#结论:有国际电话的流失比例较高
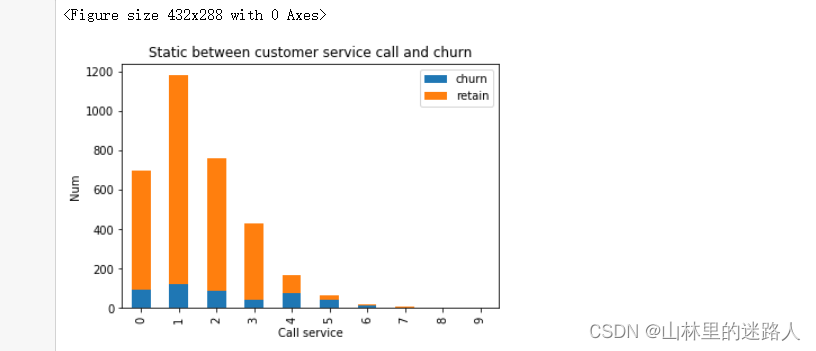
#查看客户服务电话和结果的关联
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
cus_0 = churn_df['CustServ Calls'][churn_df['Churn?'] == 'False.'].value_counts()#没有用户流失的电话数
cus_1 = churn_df['CustServ Calls'][churn_df['Churn?'] == 'True.'].value_counts()#有用户流失的电话数
df=pd.DataFrame({u'churn':cus_1, u'retain':cus_0})
df.plot(kind='bar', stacked=True)
plt.title(u"Static between customer service call and churn")
plt.xlabel(u"Call service") # 打电话的数量
plt.ylabel(u"Num") #流失与不流失的总数
plt.show()
# 在打3次客服电话的时候有400多人,其中没有流失的有300,流失了有100人
# 在打4次客服电话的时候有180人,其中没有流失的有80人,流失的有100人
















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











