







用简单通俗易懂的话和可执行方式来定位手机发热

1.手机发热成因
1.手机发热上限
手机CPU温度在50度以下即为正常温度。在一般情况下,手机CPU的温度应当控制在不超过室内的温30度以上,也就是说室温是20度,手机CPU温度就应该控制在不超过50度为宜。
为什么是这个值,因为超过这个值,CPU的硅片会受到影响,从而影响运算效率,手机更加卡顿。在实际上的应用开发中,静态APP一般都是在室温上下(35度左右),长时间集成语音/视频会增加10度,40度左右,但是还是会有感觉。但是,如果达到50度,用户会有很强的感受。尤其是超过37度(人体温度)
这个值的获取,估计是驱动人生等应用结合经验确定的。
2.手机发热成因
1.定性
CPU与GPU占用率过高。当占用率高的时候,参与运算的晶体管越多,那么由于输入功率大部分转化为热能,所以,产生的热量会更多。
2.定量
由于未找到TDP 热设计功耗公式,不展开。
2.CPU占用率查看方法
1.查看工具
1.使用外部第三方工具来辅助测试,比如:腾讯 GT,网易 Emagee 等
2.Linux top 命令(有误差,易获取)
2.top命令
adb shell top //动态变化CPU占用率
adb shell top -m 10 -s CPU //可查看占用 CPU 最高的前 10 个程序(-t 显示进程名称,-s 按指定行排序,-n 在退出前刷新几次,-d 刷新间隔,-m 显示最大数量)
adb shell top -n 1| grep PackageName /自己应用
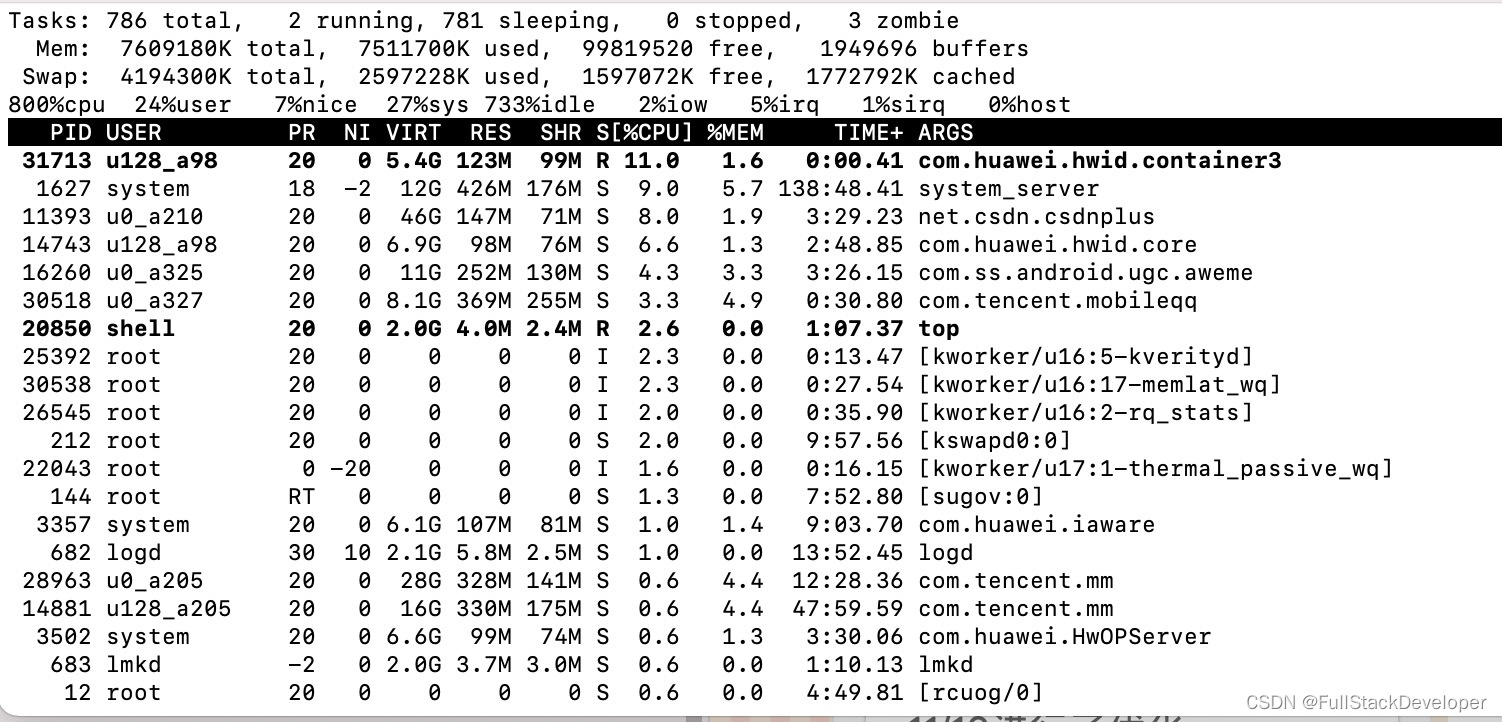
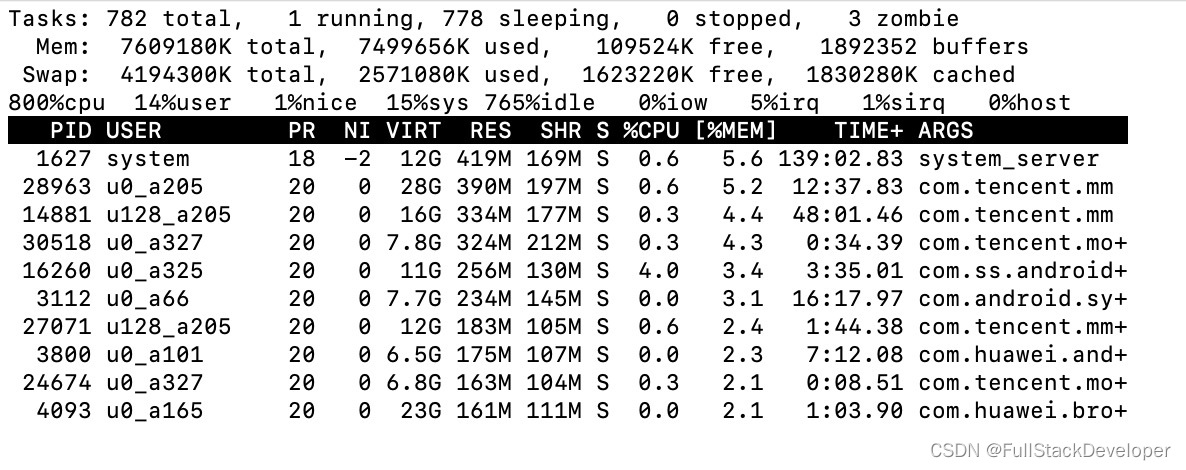
3.打印信息参数诠释
这里引入了 Jiffies(时间片)的概念,Jiffies 的介绍如下:
Jiffies 为 Linux 核心变数,是一个 unsigned long 类型的变量,它被用来记录系统自开机以来,已经过了多少 tick。每发生一次 timer interrupt,Jiffies 变数会被加 1
而上面每一列的数值含义如下:
user :从系统启动开始累计到当前时刻,用户态的 jiffies ,不包含 nice 值为负进程;
nice :从系统启动开始累计到当前时刻,nice 值为负的进程所占用的 jiffies;
system :从系统启动开始累计到当前时刻,系统态的 jiffies;
idle :从系统启动开始累计到当前时刻,除硬盘 IO 等待时间以外其它等待的 jiffies;
iowait : 从系统启动开始累计到当前时刻,硬盘 IO 等待的 jiffies;
irq : 从系统启动开始累计到当前时刻,硬中断的 jiffies;
softirq :从系统启动开始累计到当前时刻,软中断的 jiffies。
总的 Jiffies 就是上面所有项加起来的总和。因此我们计算一段时间的 CPU 占用率的时候就可以使用:
total=user+system+nice+idle+iowait+irq+softirq
*CPU usage=[(user_end +sys_end+nice_end) - (user_begin + sys_begin+nice_begin)]/(total_end - total_begin)100
上述方法统计的是当前系统所有进程的 CPU 总和使用率
3.CPU高占用率定位
我们最终肯定是优化我们的代码,那么就需要知道具体是哪行代码占用了高CPU,这时候我们用Android Studio的Monitor就可以了,打开Android Studio的Monitor(请保持adb连接你的设备),如下图点击CPU的时钟按钮开始跟踪APP CPU调用:














 51
51











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









