






5.梯度、激活函数、损失函数
5.1 什么是梯度
梯度:所有的偏微分的向量

梯度的性质:
1.梯度的长度可以反映函数变化的趋势
2.梯度的方向可以表示函数增长的方向
梯度与优化问题:
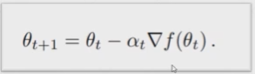
鞍点:
一个点,对于一个维度取极大值,对于另一个维度取极小值
影响优化性能的因素:
初始状态、学习率、动量(逃出局部极小值的方法)
5.2 常见函数的梯度
一维函数的梯度即导数:
f(x) = [y - (x * w + b) ] 2
5.3 激活函数及其梯度
最早的激活函数:
sigmoid激活函数:
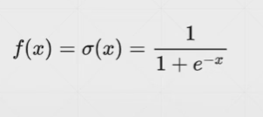
sigmoid的求导:
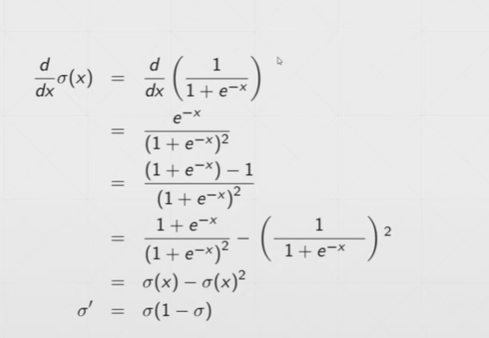
Tanh激活函数:

ReLU激活函数:
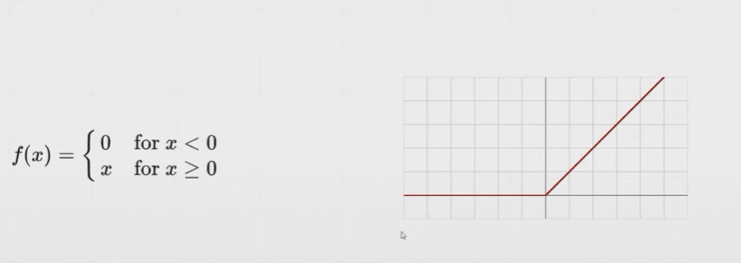
5.4 Loss及其梯度
MSE(均方误差)

L2-norm与MSE的区别在于:L2-norm有开根号,MSE没有开根号
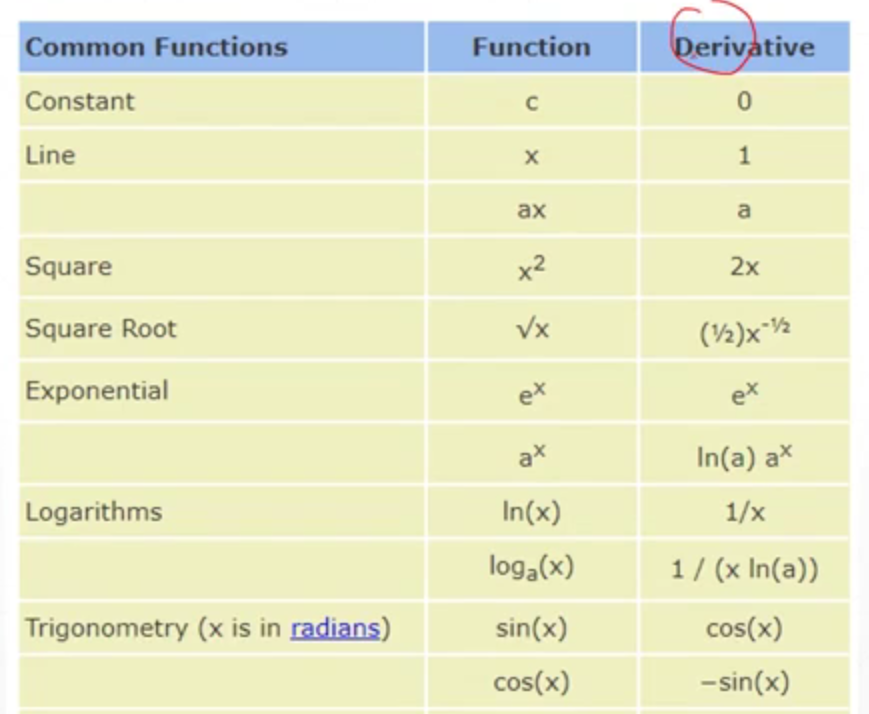
MSE的求导:
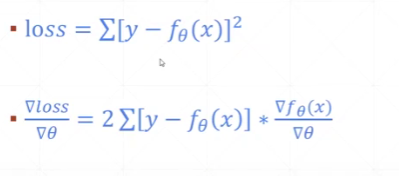
MSE求梯度的示例:
两种方法:
1.torch.autograd.grad(自动求梯度)
2.loss.backward(反向传播,求出所有参数梯度,并主动访问)
#方法1
import torch
from torch.nn import functional as F
x = torch.ones(1)
w = torch.full([1],2.0)
mse = F.mse_loss(torch.ones(1),x*w)
print(mse)#输出结果:tensor(1.)
w.requires_grad_()
mse = F.mse_loss(torch.ones(1),x*w)
print(torch.autograd.grad(mse,[w]))#输出结果:(tensor([2.]),)
#方法2
w.requires_grad_()
mse = F.mse_loss(torch.ones(1),x*w)
mse.backward()
print(w.grad)#输出结果:tensor([2.])
5.5 softmax回归

线性回归的输出输入到softmax回归中,softmax的所有概率输出值相加和为1。
softmax的导数:
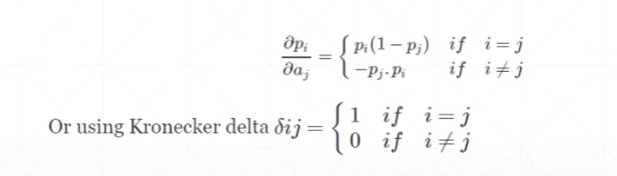
实现softmax的操作和求导示例:
import torch
from torch.nn import functional as F
a = torch.rand(3)
print(a.requires_grad_())#输出结果:tensor([0.2317, 0.3873, 0.8968], requires_grad=True)
p = F.softmax(a,dim=0)
print(torch.autograd.grad(p[1],[a],retain_graph=True))#输出结果:(tensor([-0.0691, 0.2034, -0.1343]),)
print(torch.autograd.grad(p[2],[a]))#输出结果:(tensor([-0.1150, -0.1343, 0.2493]),)
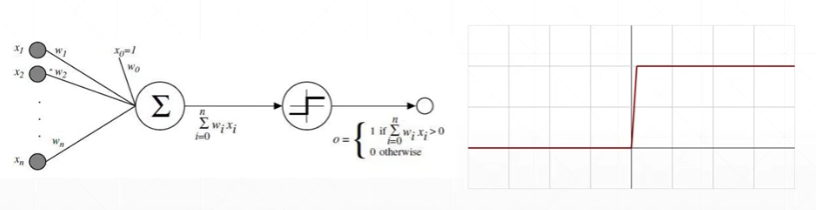
5.6 感知机的梯度推导
简单的单层感知机模型:
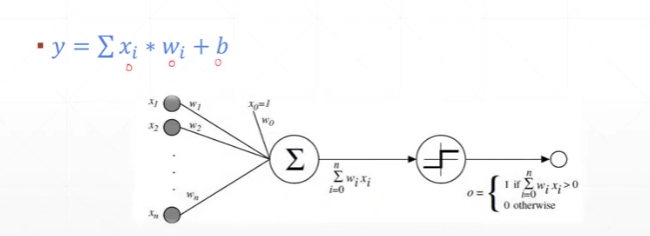
损失函数E与模型表示:
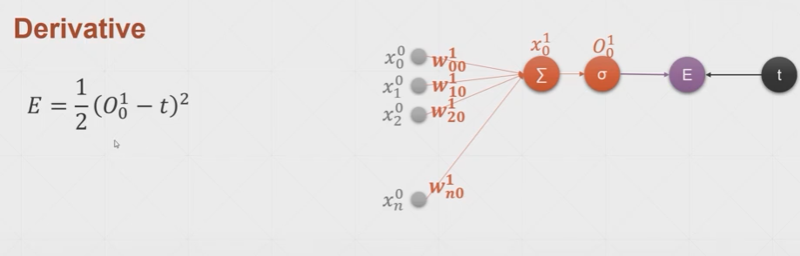
经过推导可得,损失函数关于某参数wj0的导数:

单层感知机模型求导示例:
import torch
from torch.nn import functional as F
x = torch.randn(1,10)
w = torch.randn(1,10,requires_grad=True)
o = torch.sigmoid(x@w.t())
loss = F.mse_loss(torch.ones(1,1),o)
loss.backward()
print(w.grad)#输出结果:tensor([[-0.0329, -0.3117, 0.0493, -0.2312, -0.2009, 0.4507, 0.1286, 0.1634,-0.2982, 0.0854]])
多输出感知机模型:
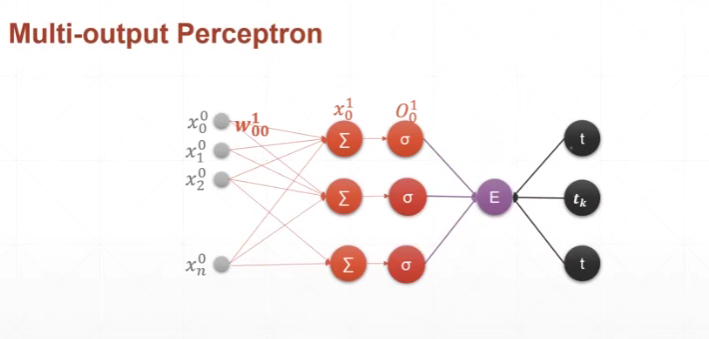
多输出感知机导数推导过程:
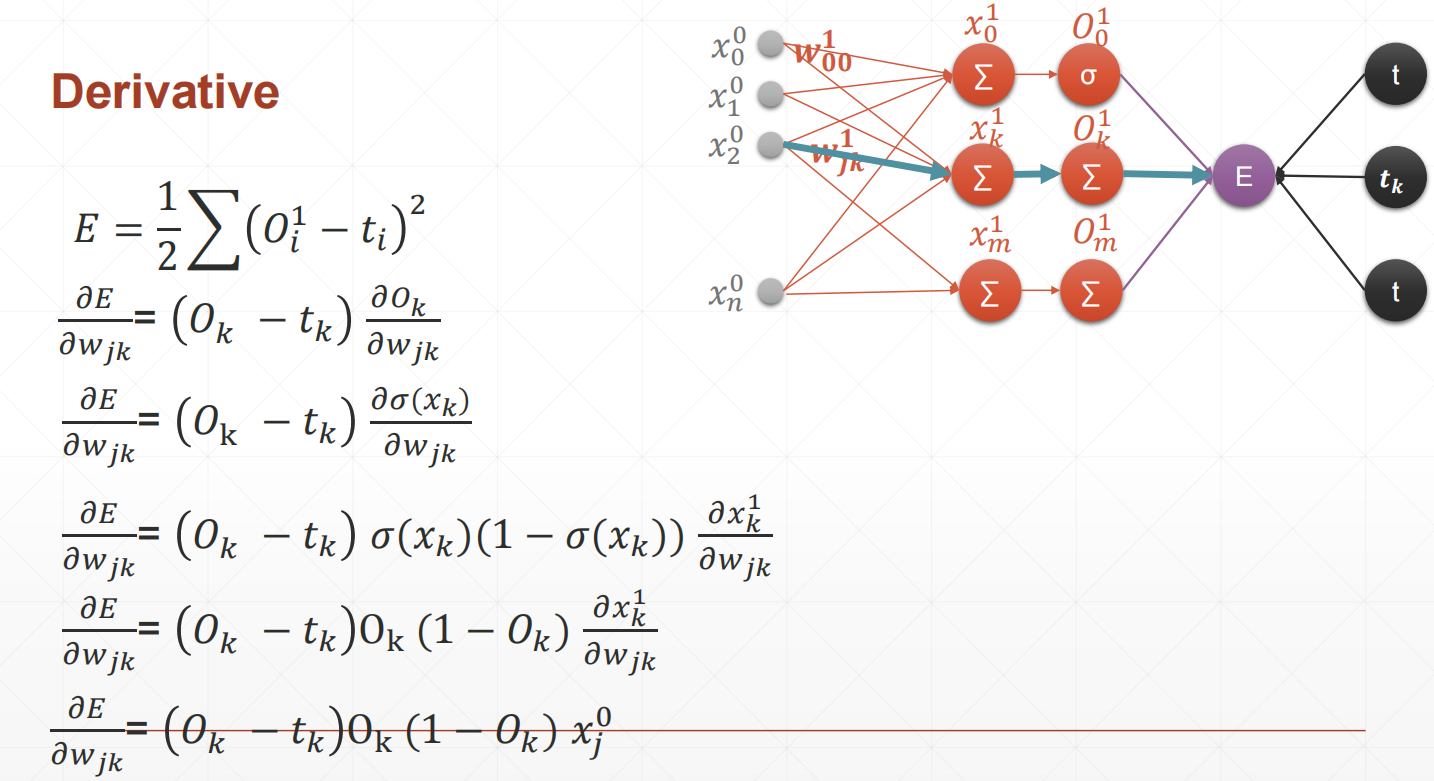
多输出感知机模型求导示例:`
import torch
from torch.nn import functional as F
x = torch.randn(1,10)
w = torch.randn(2,10,requires_grad=True)
o = torch.sigmoid(x@w.t())
loss = F.mse_loss(torch.ones(1,2),o)
print(loss)#输出loss
loss.backward()
print(w.grad)#输出所有权重对应的梯度
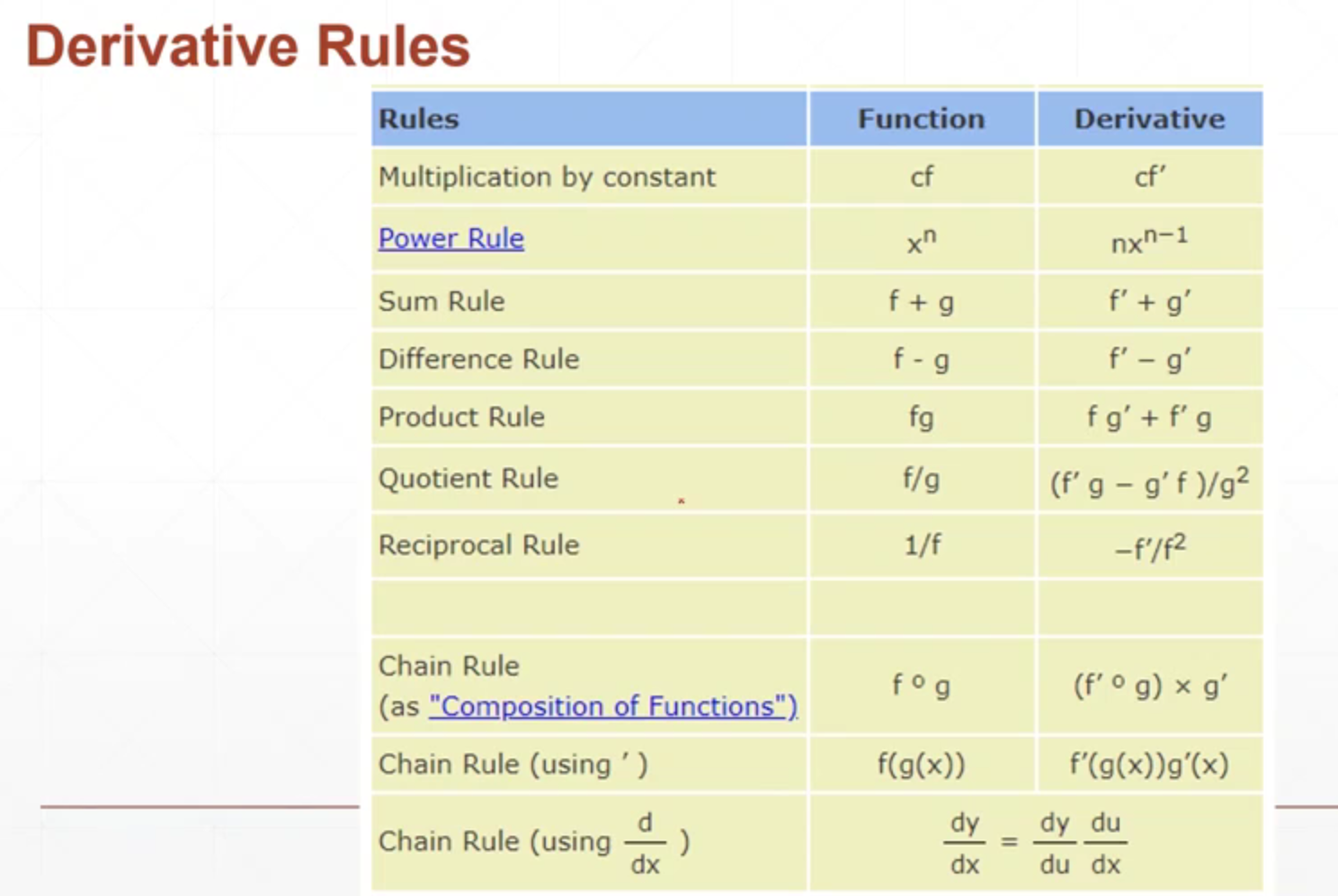
5.7 链式法则
其它的导数运算法则:
链式法则:

感知机中的链式法则:
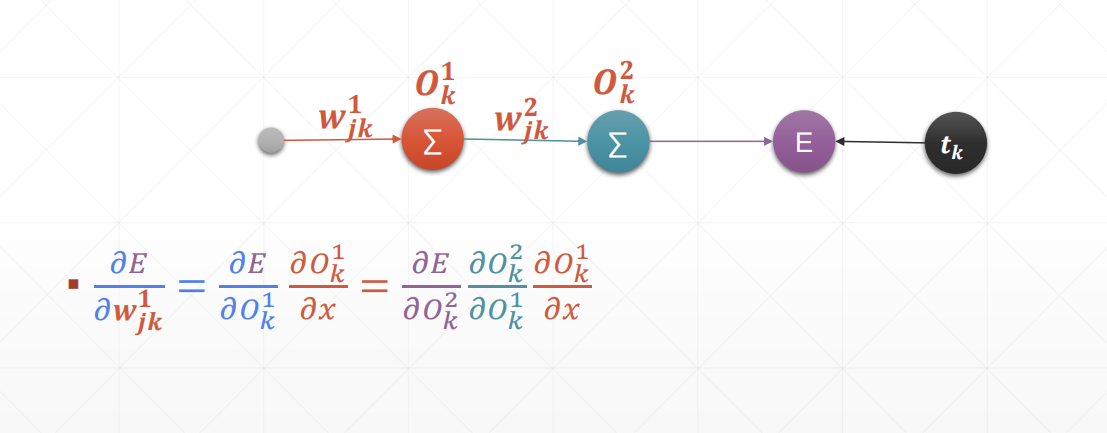
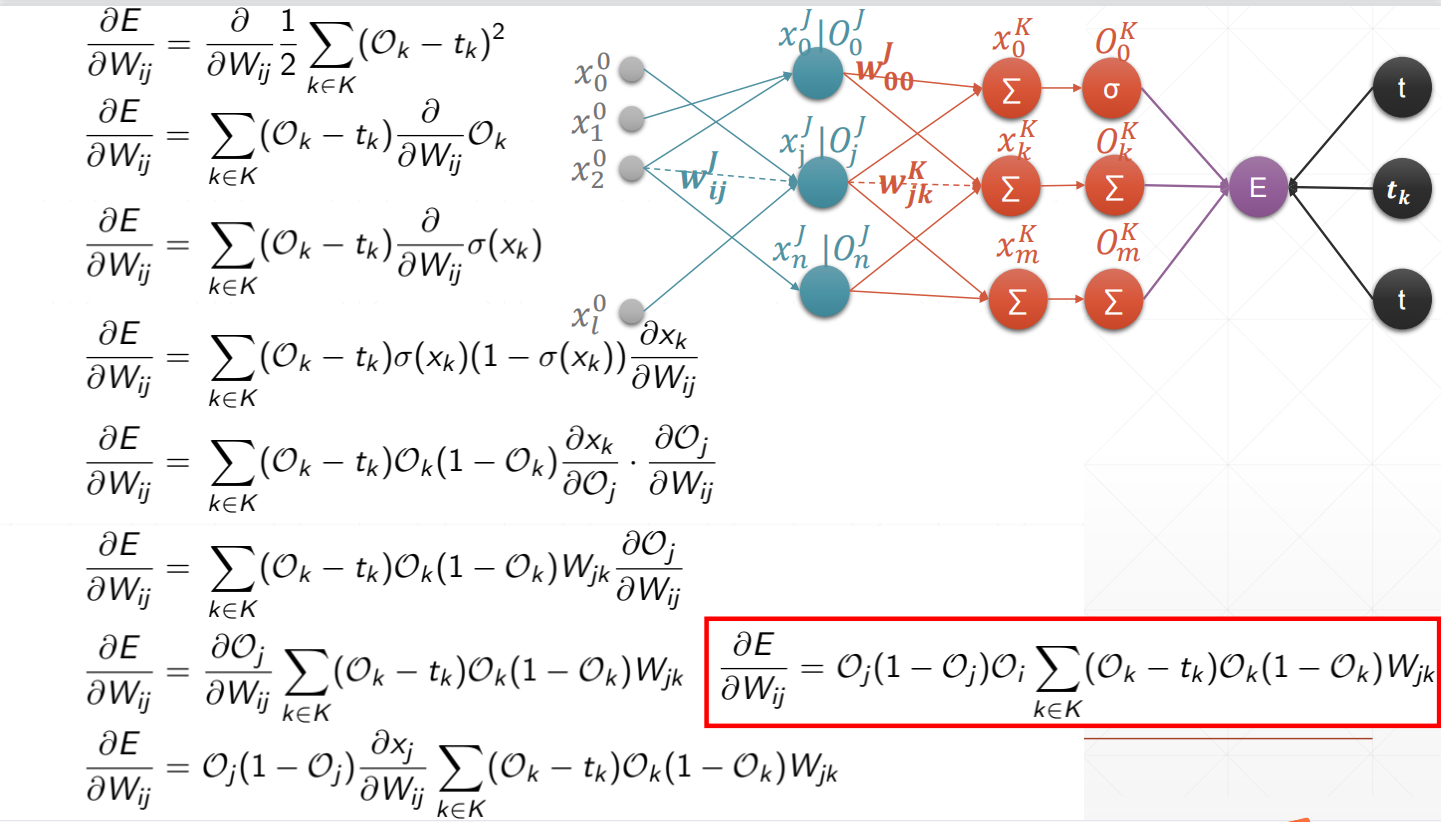
5.8 反向传播算法
反向传播推导过程:
优化问题实战
Himmelblau函数:
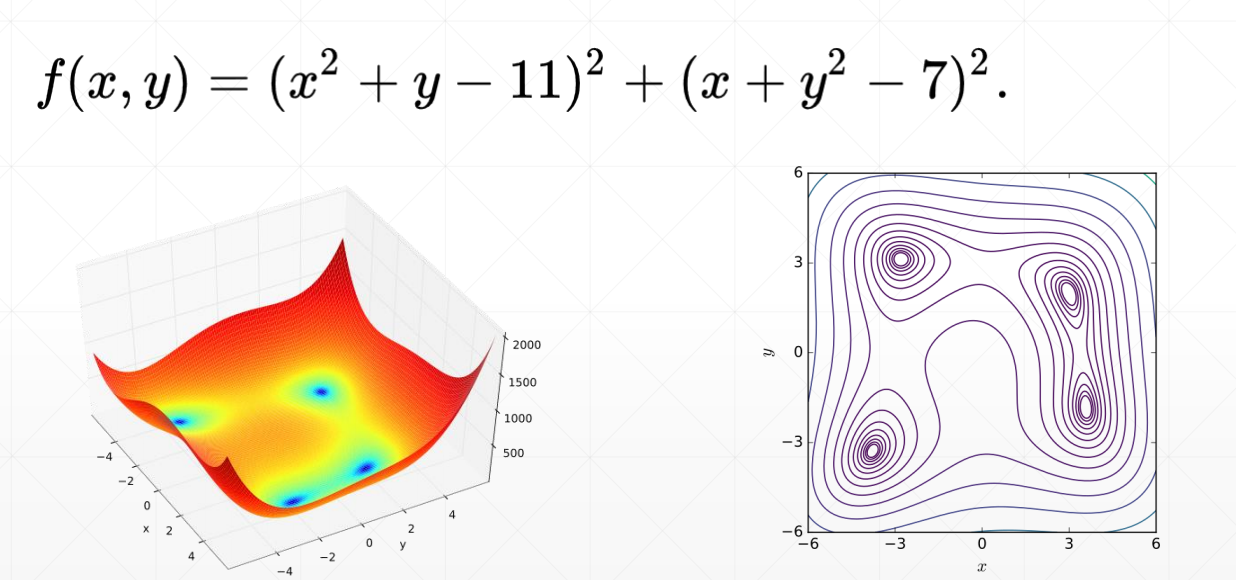
目标:使函数值收敛于极小值点
代码示例:
import numpy as np
from matplotlib import pyplot as plt
def himmelblau(x):
return (x[0]**2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 -7) ** 2
x = np.arange(-6,6,0.1)
y = np.arange(-6,6,0.1)
print("x,y shape:",x.shape,y.shape)#输出结果:x,y shape: (120,) (120,)
X,Y = np.meshgrid(x,y)
print("X,Y shape:",X.shape,Y.shape)#输出结果:X,Y shape: (120, 120) (120, 120)
Z = himmelblau([X,Y])
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure('himmelblau')
ax = fig.add_axes(Axes3D(fig))
ax.plot_surface(X,Y,Z)
ax.view_init(60,-30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
import torch
x = torch.tensor([0.,0.],requires_grad=True)
optimizer = torch.optim.Adam([x],lr=1e-3)
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad()
pred.backward()
optimizer.step()
if step % 2000 == 0:
print("step {}: x = {},f(x) = {}".
format(step,x.tolist(),pred.item()))
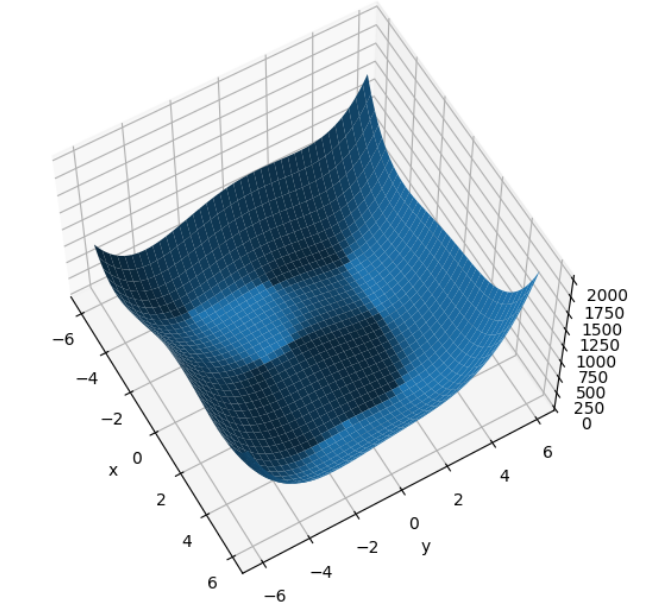
打印出的Himmelblau函数图像:
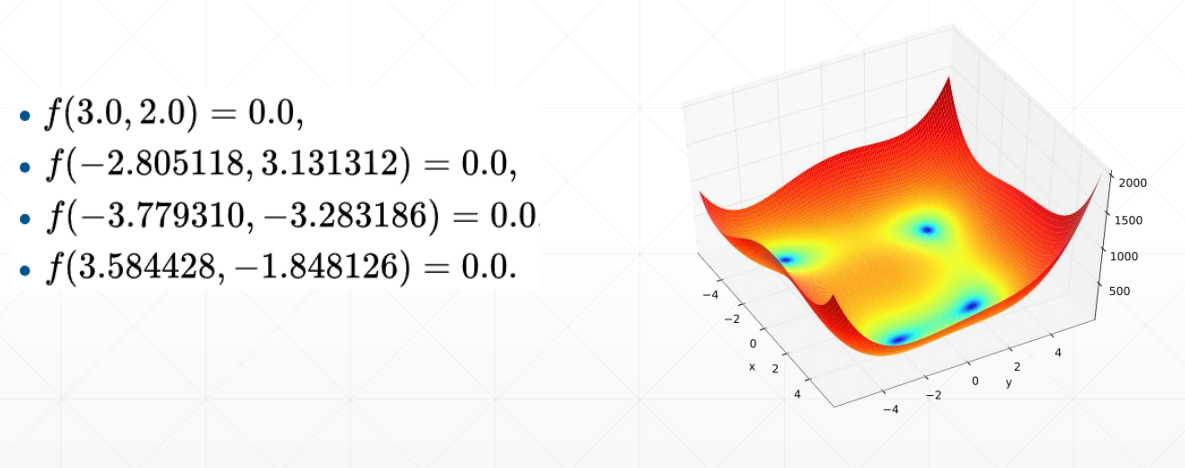
迭代过程:
step 0: x = [0.0009999999310821295, 0.0009999999310821295],f(x) = 170.0
step 2000: x = [2.3331806659698486, 1.9540694952011108],f(x) = 13.730916023254395
step 4000: x = [2.9820079803466797, 2.0270984172821045],f(x) = 0.014858869835734367
step 6000: x = [2.999983549118042, 2.0000221729278564],f(x) = 1.1074007488787174e-08
step 8000: x = [2.9999938011169434, 2.0000083446502686],f(x) = 1.5572823031106964e-09
step 10000: x = [2.999997854232788, 2.000002861022949],f(x) = 1.8189894035458565e-10
step 12000: x = [2.9999992847442627, 2.0000009536743164],f(x) = 1.6370904631912708e-11
step 14000: x = [2.999999761581421, 2.000000238418579],f(x) = 1.8189894035458565e-12
step 16000: x = [3.0, 2.0],f(x) = 0.0
step 18000: x = [3.0, 2.0],f(x) = 0.0
6. 分类问题
6.1 逻辑回归
逻辑回归:线性回归输入到logistic function当中,获得[0,1]的值,解决分类问题。
回归问题和分类问题目标和方法
1.回归问题的目标:得到预测值=真实值
方法:使得损失函数最小化
2.分类问题的目标:预测准确率达到100%
方法:使得概率值损失(散度)最小化
6.2 交叉熵
交叉熵:用于计算逻辑回归的损失
熵:消除不确定所需的信息量的度量

6.3 全连接层
通过线性回归不断堆叠,逐层减少输出神经元个数,直到神经元个数等于标签数。
上一层的输出与下一层的输入之间可以插入激活函数。
应用nn.Module搭建全连接层的步骤:
1.继承nn.Module
2.初始化层
3.执行前向传播
代码示例:
class MLP(nn.Module):
def __init__(self):
super(MLP,self).__init__()
self.model = nn.Sequential(
nn.Linear(784,200),
nn.ReLU(inplace=True),
nn.Linear(200,200),
nn.ReLU(inplace=True),
nn.Linear(200,10),
nn.ReLU(inplace=True),
)
def forward(self,x):
x = self.model(x)
return x
6.4 激活函数与GPU加速
sigmoid和tanh激活函数的缺点:会出现梯度消失问题
ReLU激活函数:有效缓解了梯度消失的问题
LeakyReLU激活函数:在ReLU的基础上,在负区间范围内y = a * x(a很小)
更换设备(示例):
device = torch.device('cuda:0')
net = MLP().to(device)
6.5 测试效果
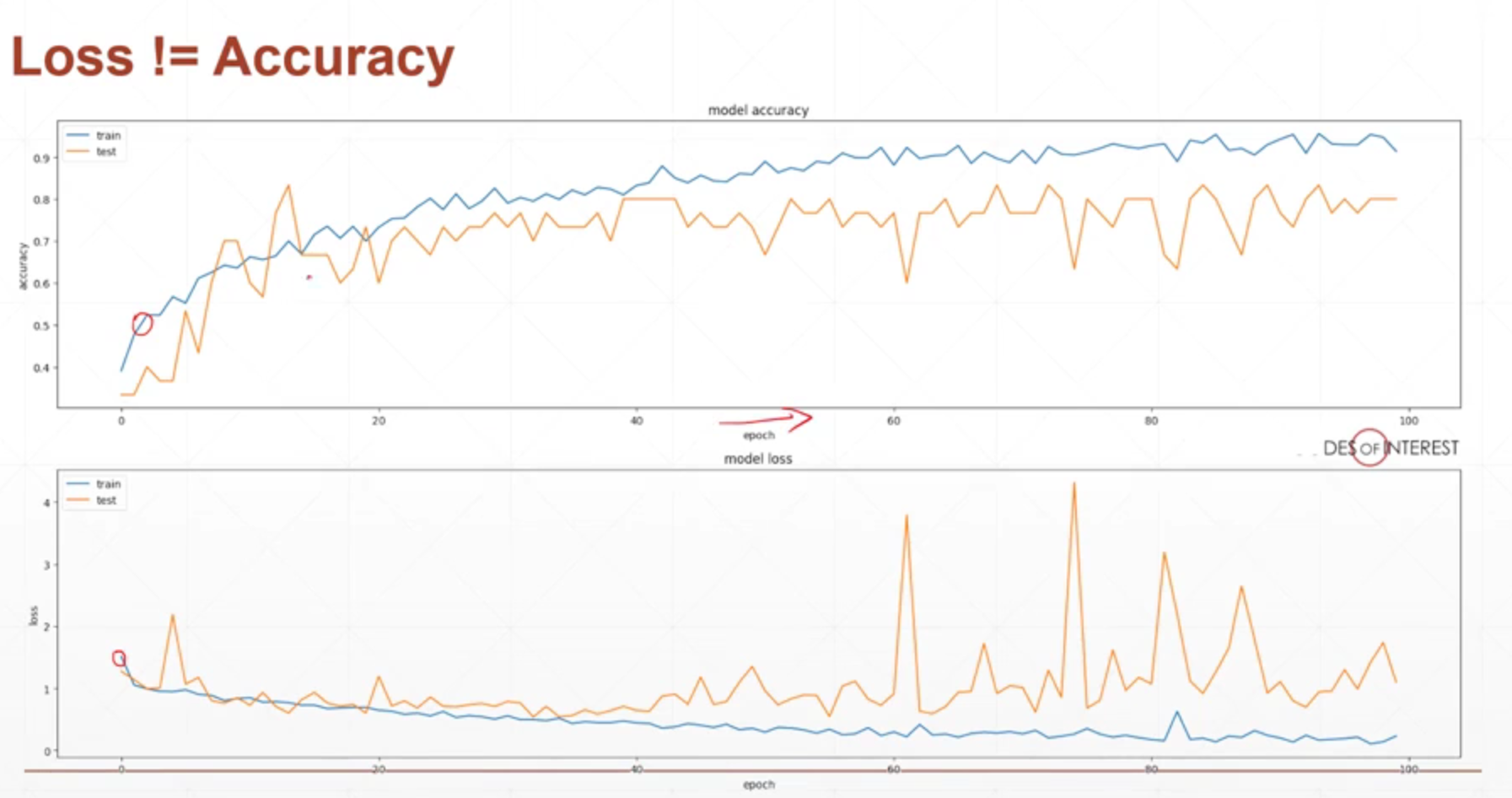
评价模型测试性能的指标:准确率、loss
准确率的代码示例:
correct = torch.eq(pred_label,label)
print(correct.sum().float().item() / 4.)
什么时候做测试合适:通常训练了一次或多次epoch之后测试一次
7.深度学习常见问题
7.1 过拟合和欠拟合
y = w * x + b + eps
样本过少容易受到eps的影响,造成模型模拟的能力受到影响。
欠拟合:训练出的模型的复杂度小于真实模型的复杂度
欠拟合表现在:训练的准确率较低,损失较大;测试更是如此
解决方法:增加模型的复杂度
过拟合:训练出的模型复杂度大于真实模型的复杂度
过拟合表现在:训练的准确率较高,损失较小;但测试上表现相反
解决方法:降低模型的复杂度
过拟合现象:

7.2 交叉验证
通过训练集与验证集的划分,从而检测判断是否存在过拟合现象。
通过多个验证集的划分,得到测试效果最好的参数。
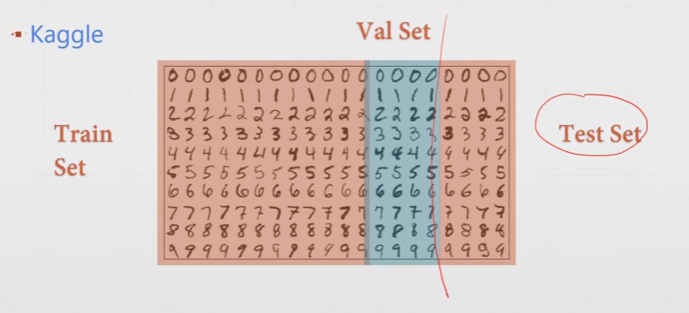
K折交叉验证:

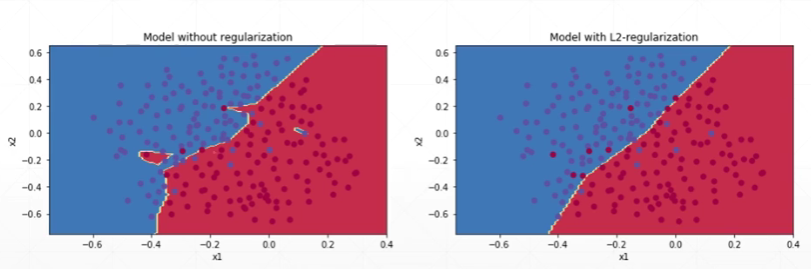
7.3 正则化
正则化作用:减轻过拟合
奥卡姆剃刀定理:优先选择更简单的模型
减轻过拟合的方法:
1.增大数据集。2.降低模型复杂度。3.Dropout。4.数据增强。5.提前终止训练。
常见的正则化:L1-正则化与L2-正则化
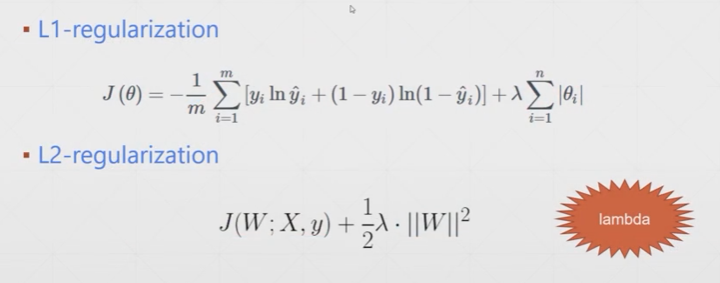
正则化之后的效果:
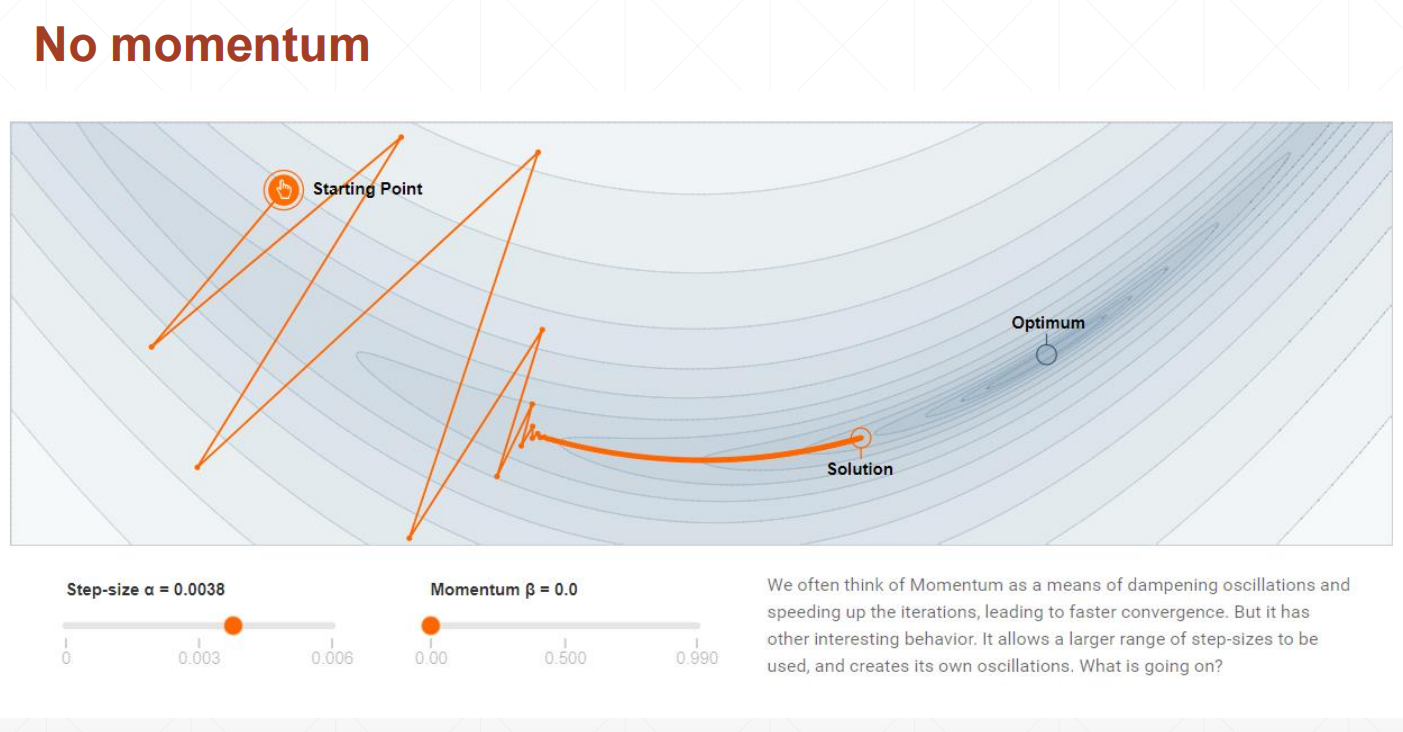
7.4 动量与学习率衰减
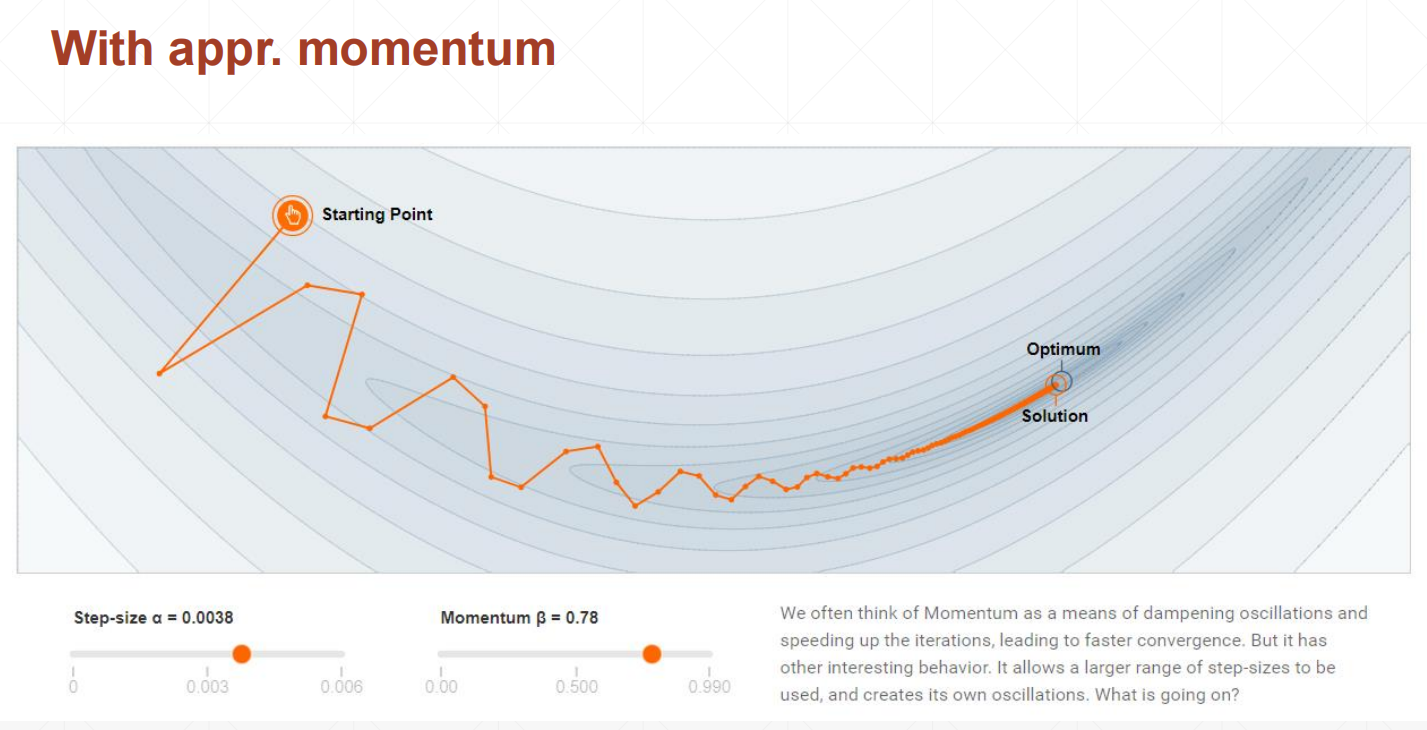
引入动量的目的:缓解模型收敛于局部最优,而非全局最优的问题。
没有引入动量的情况:
引入动量的情况:
学习率会带来的影响:
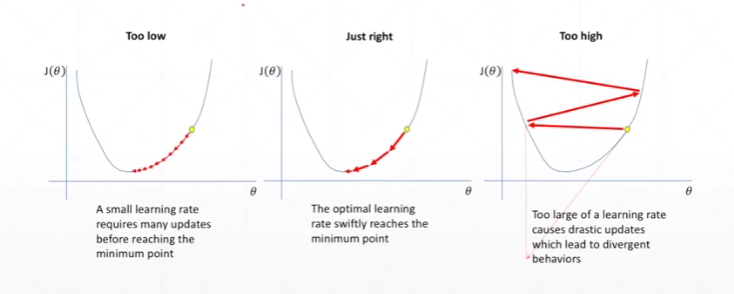
学习率衰减方法:一开始可以使用较大的学习率,接近收敛时使用较小的学习率,经过几轮逐渐减小学习率大小。
7.5 提前终止和丢弃法
提前终止:在测试效果增加与降低的交界时,终止训练过程,将当前的参数作为训练出的模型参数。
提前终止示意图:

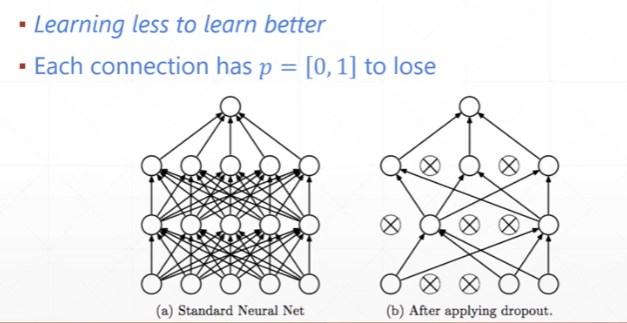
丢弃法:随机丢弃神经网络层中的神经单元,也就是将参数w设为0。
丢弃法示意图:















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









