







由于网上资料很多,这里就不再对算法原理进行推导,仅给出博主用Python实现的代码,供大家参考
适用问题:二类分类
实验数据:二分类的数据 train_binary.csv
SVM有三种模型,由简至繁为
- 当训练数据训练可分时,通过硬间隔最大化,可学习到硬间隔支持向量机,又叫线性可分支持向量机
- 当训练数据训练近似可分时,通过软间隔最大化,可学习到软间隔支持向量机,又叫线性支持向量机
- 当训练数据训练不可分时,通过软间隔最大化及核技巧(kernel trick),可学习到非线性支持向量机
实现代码(用sklearn实现):
# encoding=utf-8
import time
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import datasets
from sklearn import svm
if __name__ == '__main__':
print('prepare datasets...')
# Iris数据集
# iris=datasets.load_iris()
# features=iris.data
# labels=iris.target
# MINST数据集
raw_data = pd.read_csv('../data/train_binary.csv', header=0) # 读取csv数据,并将第一行视为表头,返回DataFrame类型
data = raw_data.values
features = data[::, 1::]
labels = data[::, 0] # 选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
time_2=time.time()
print('Start training...')
clf = svm.SVC() # svm class
clf.fit(train_features, train_labels) # training the svc model
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict=clf.predict(test_features)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)代码可从这里svm/svm_sklearn.py获取
注:可用拆解法(如OvO,OvR)将svm扩展成适用于多分类问题(其他二分类问题亦可),sklearn中已经实现
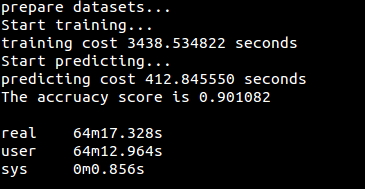
运行结果:















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









