






GPT-2 就像传统的语言模型一样,一次只输出一个单词(token)。这种模型之所以效果好是因为在每个新单词产生后,该单词就被添加在之前生成的单词序列后面,这个序列会成为模型下一步的新输入。这种机制叫做自回归(auto-regression)。
GPT-2,以及一些诸如 TransformerXL 和 XLNet 等后续出现的模型,本质上都是自回归模型,而 BERT 则不然。这就是一个权衡的问题了。虽然没有使用自回归机制,但 BERT 获得了结合单词前后的上下文信息的能力,从而取得了更好的效果。XLNet 使用了自回归,并且引入了一种能够同时兼顾前后的上下文信息的方法。
只使用解码器
在 transformer 原始论文发表之后,一篇名为「Generating Wikipedia by Summarizing Long Sequences」的论文提出用另一种 transformer 模块的排列方式来进行语言建模——它直接扔掉了所有的 transformer 编码器模块。
图中所有的解码器模块都是一样的,因此本文只展开了第一个解码器的内部结构。可以看见,它使用了带掩模的自注意力层。请注意,该模型在某个片段中可以支持最长 4000 个单词的序列,相较于 transformer 原始论文中最长 512 单词的限制有了很大的提升。
这些解码器模块和 transformer 原始论文中的解码器模块相比,除了去除了第二个自注意力层之外,并无很大不同。一个相似的架构在字符级别的语言建模中也被验证有效,它使用更深的自注意力层构建语言模型,一次预测一个字母/字符。OpenAI 的 GPT-2 模型就用了这种只包含解码器(decoder-only)的模块。
GPT2
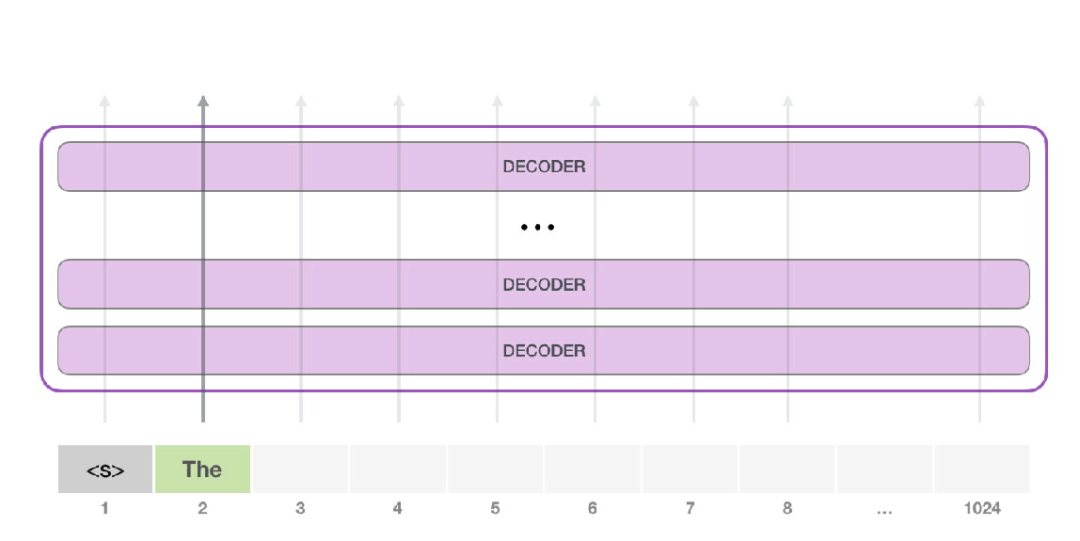
GPT-2 可以处理最长 1024 个单词的序列。每个单词都会和它的前续路径一起「流过」所有的解码器模块。
想要运行一个训练好的 GPT-2 模型,最简单的方法就是让它自己随机工作(从技术上说,叫做生成无条件样本)。换句话说,我们也可以给它一点提示,让它说一些关于特定主题的话(即生成交互式条件样本)。在随机情况下,我们只简单地提供一个预先定义好的起始单词(训练好的模型使用「|endoftext|」作为它的起始单词,不妨将其称为<s>),然后让它自己生成文字。
此时,模型的输入只有一个单词,所以只有这个单词的路径是活跃的。单词经过层层处理,最终得到一个向量。向量可以对于词汇表的每个单词计算一个概率(词汇表是模型能「说出」的所有单词,GPT-2 的词汇表中有 50000 个单词)。在本例中,我们选择概率最高的单词「The」作为下一个单词。
但有时这样会出问题——就像如果我们持续点击输入法推荐单词的第一个,它可能会陷入推荐同一个词的循环中,只有你点击第二或第三个推荐词,才能跳出这种循环。同样的,GPT-2 也有一个叫做「top-k」的参数,模型会从概率前 k 大的单词中抽样选取下一个单词。显然,在之前的情况下,top-k = 1。
第二个单词的路径是当前唯一活跃的路径了。GPT-2 的每一层都保留了它们对第一个单词的解释,并且将运用这些信息处理第二个单词(具体将在下面一节对自注意力机制的讲解中详述),GPT-2 不会根据第二个单词重新解释第一个单词。
输入编码
GPT-2 从嵌入矩阵中查找单词对应的嵌入向量,该矩阵也是模型训练结果的一部分。 
每一行都是一个词嵌入向量:一个能够表征某个单词,并捕获其意义的数字列表。嵌入向量的长度和 GPT-2 模型的大小有关,最小的模型使用了长为 768 的嵌入向量来表征一个单词。
所以在一开始,我们需要在嵌入矩阵中查找起始单词<s>对应的嵌入向量。但在将其输入给模型之前,我们还需要引入位置编码——一些向 transformer 模块指出序列中的单词顺序的信号。1024 个输入序列位置中的每一个都对应一个位置编码,这些编码组成的矩阵也是训练模型的一部分。
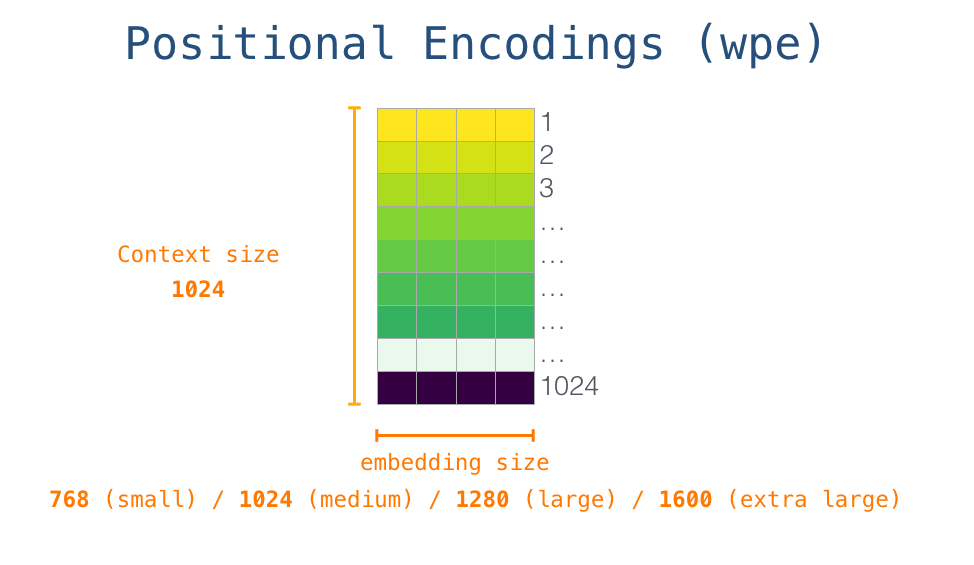
训练后的 GPT-2 模型包含两个权值矩阵:嵌入矩阵和位置编码矩阵。

将单词输入第一个 transformer 模块之前需要查到它对应的嵌入向量,再加上 1 号位置位置对应的位置向量。
自注意力
第一个 transformer 模块处理单词的步骤如下:首先通过自注意力层处理,接着将其传递给神经网络层。第一个 transformer 模块处理完但此后,会将结果向量被传入堆栈中的下一个 transformer 模块,继续进行计算。每一个 transformer 模块的处理方式都是一样的,但每个模块都会维护自己的自注意力层和神经网络层中的权重。

自注意力机制所做的工作是,在处理每个单词(将其传入神经网络)之前,融入了模型对于用来解释某个单词的上下文的相关单词的理解。具体做法是,给序列中每一个单词都赋予一个相关度得分,之后对他们的向量表征求和。
举个例子,(训练正确的话)最上层的 transformer 模块在处理单词「it」的时候会关注「a robot」,所以「a」、「robot」、「it」这三个单词与其得分相乘加权求和后的特征向量会被送入之后的神经网络层。
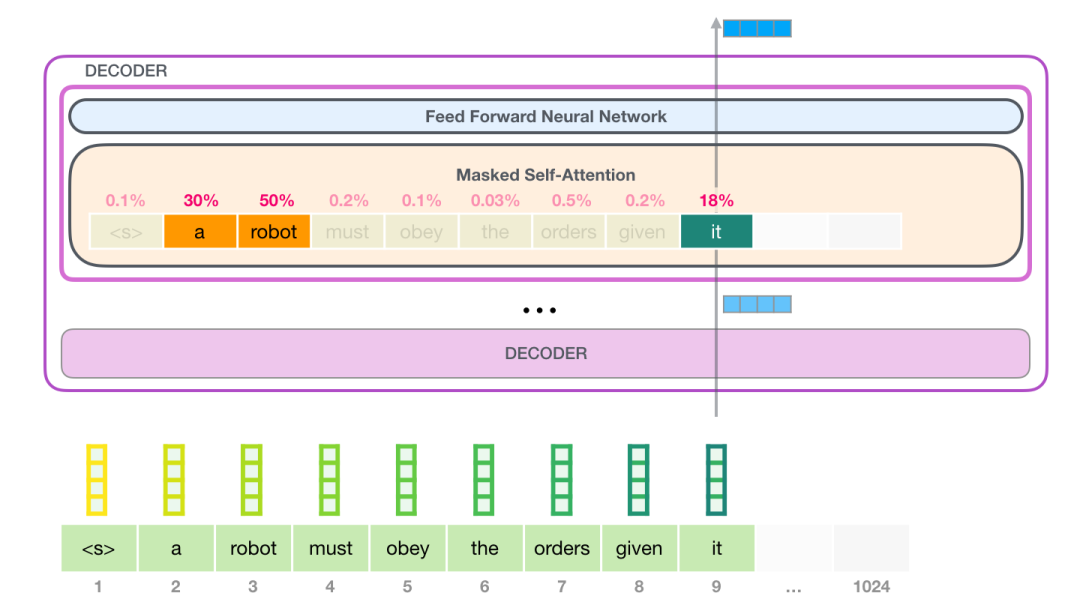
自注意力机制沿着序列中每一个单词的路径进行处理。
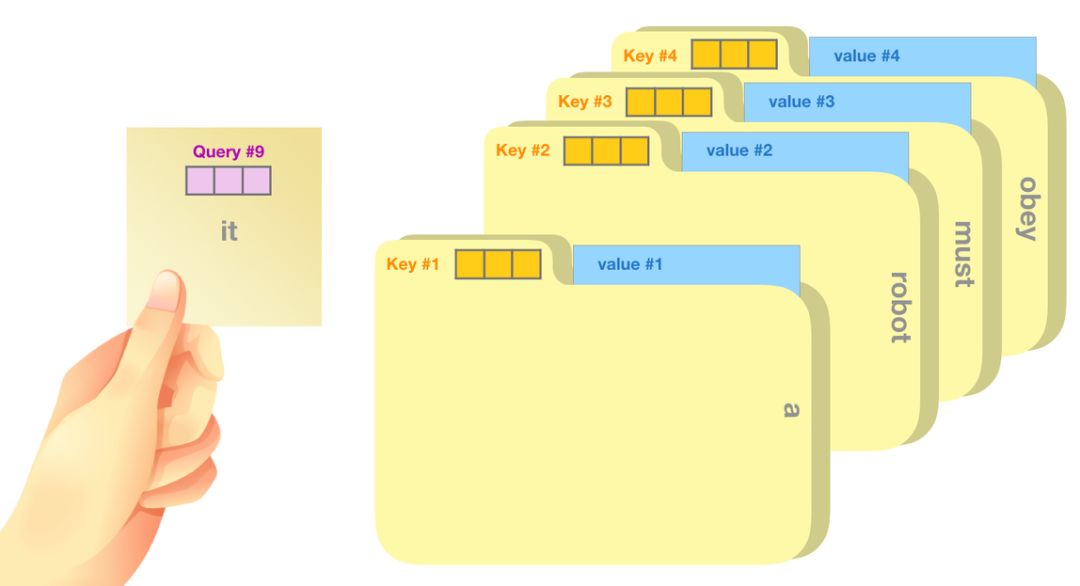
将单词的查询向量分别乘以每个文件夹的键向量,得到各个文件夹对应的注意力得分(这里的乘指的是向量点乘,乘积会通过 softmax 函数处理)。 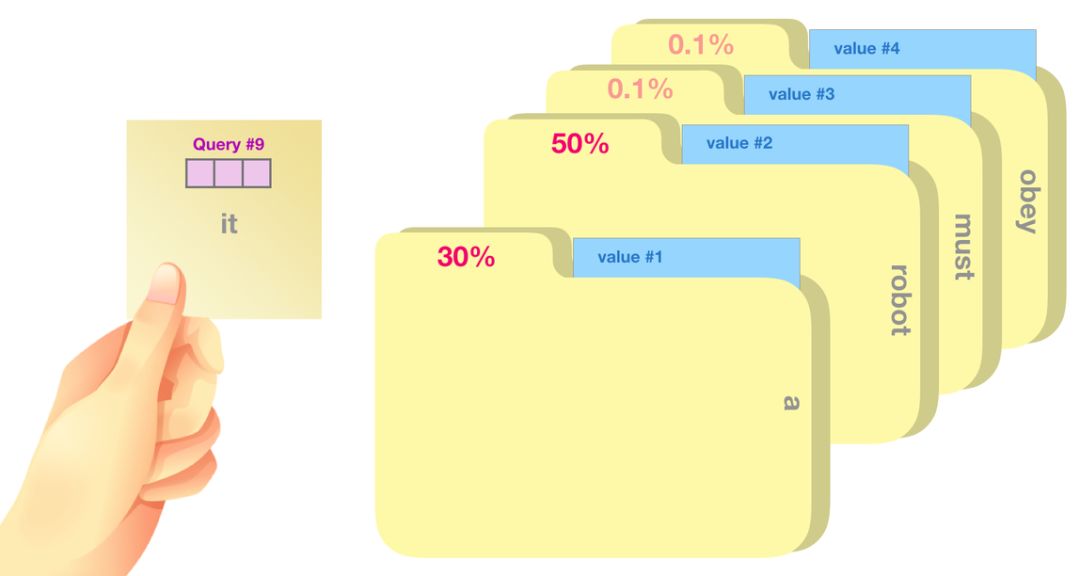
我们将每个文件夹的值向量乘以其对应的注意力得分,然后求和,得到最终自注意力层的输出。
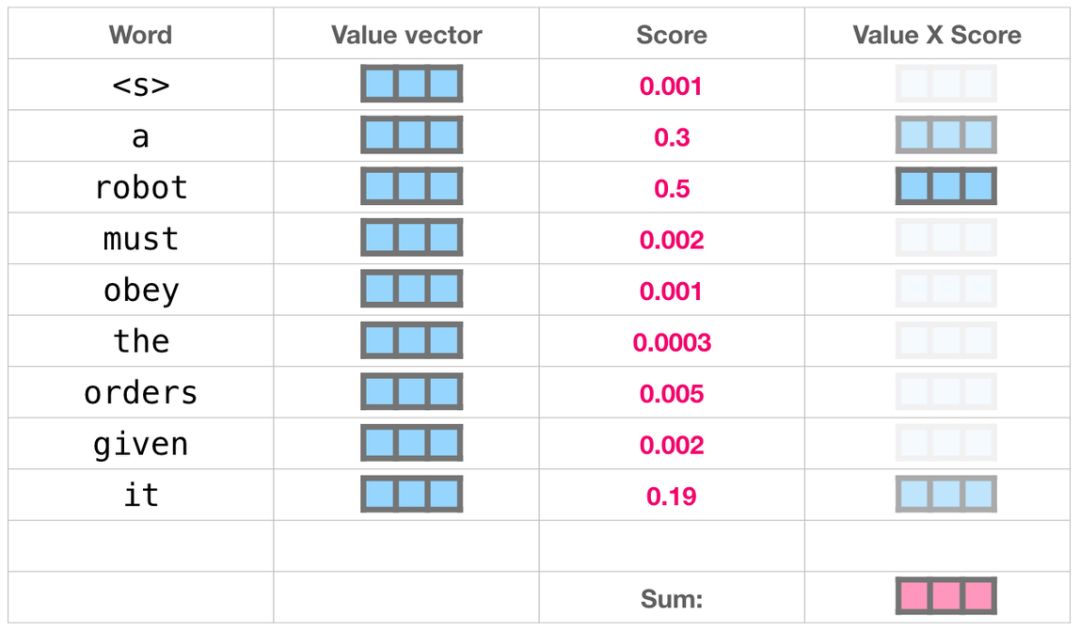
输出
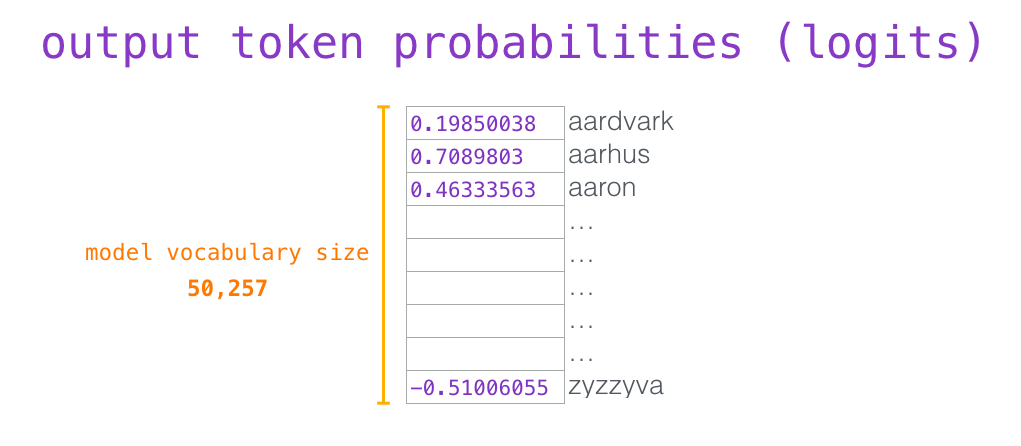
当最后一个 transformer 模块产生输出之后(即经过了它自注意力层和神经网络层的处理),模型会将输出的向量乘上嵌入矩阵。
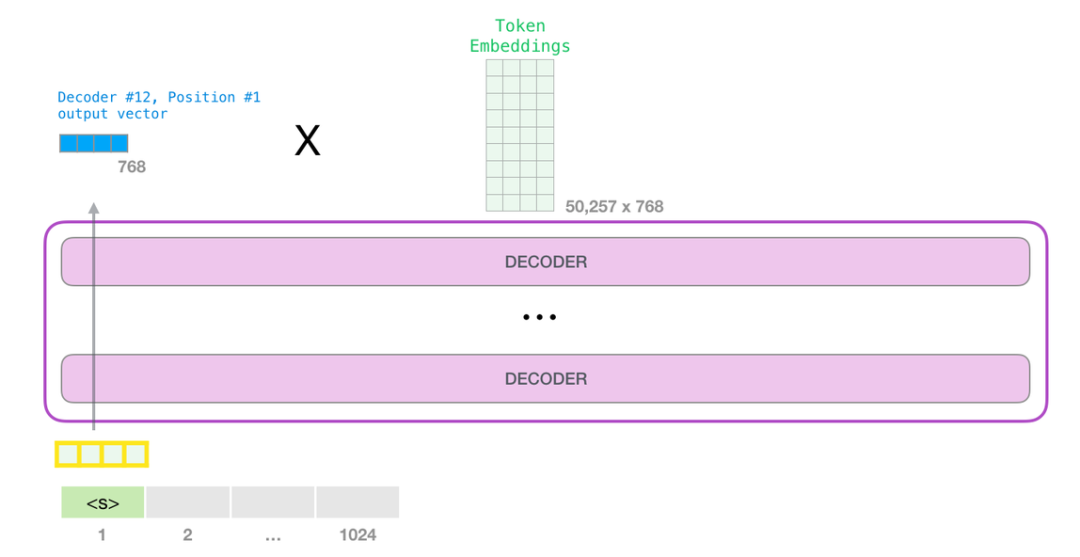
我们知道,嵌入矩阵的每一行都对应模型的词汇表中一个单词的嵌入向量。所以这个乘法操作得到的结果就是词汇表中每个单词对应的注意力得分。
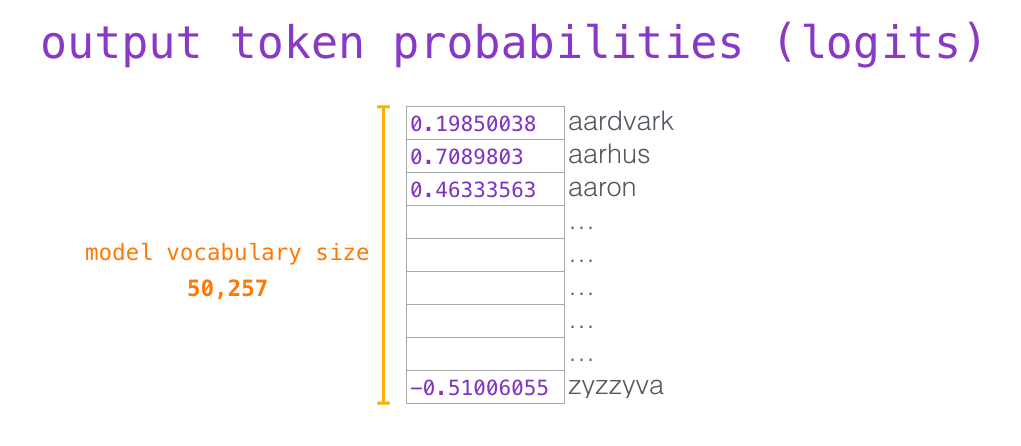
我们简单地选取得分最高的单词作为输出结果(即 top-k = 1)。但其实如果模型考虑其他候选单词的话,效果通常会更好。所以,一个更好的策略是对于词汇表中得分较高的一部分单词,将它们的得分作为概率从整个单词列表中进行抽样(得分越高的单词越容易被选中)。
这样,模型就完成了一轮迭代,输出了一个单词。模型会接着不断迭代,直到生成一个完整的序列——序列达到 1024 的长度上限或序列中产生了一个终止符。















 9032
9032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









