









 OpenAI提出了一种名为CLIP的神经网络,它能从自然语言监督信号中有效提取视觉信息,实现多任务的零样本学习。CLIP通过大量互联网上的文本-图像对进行训练,无需直接针对特定基准优化,从而展现出优秀的泛化能力和鲁棒性,尤其在非ImageNet数据集上的表现。与传统模型相比,CLIP在不牺牲性能的情况下,降低了数据成本和模型的狭窄性,提升了在现实世界场景中的表现。
OpenAI提出了一种名为CLIP的神经网络,它能从自然语言监督信号中有效提取视觉信息,实现多任务的零样本学习。CLIP通过大量互联网上的文本-图像对进行训练,无需直接针对特定基准优化,从而展现出优秀的泛化能力和鲁棒性,尤其在非ImageNet数据集上的表现。与传统模型相比,CLIP在不牺牲性能的情况下,降低了数据成本和模型的狭窄性,提升了在现实世界场景中的表现。
本文翻译自OpenAI官方博客
[1], 于2021年1月5日发布.
0. 前言
本博客是openAI的大佬们的全新作品,其提出了可以用于从自然语言监督信号中有效提取视觉信息的,名为CLIP的神经网络. CLIP可以被用于任何视觉分类的benchmark(仅需提供其对应的视觉类别即可), 同GPT-2/3类似,有着强大的"zero-shot"能力。
我认为,CLIP和DALLE这2篇论文,核心是将万能的预训练模型扩展到多模态领域(visual-natural language)。这真心非常强…
1. 开篇介绍
尽管深度学习已经将计算机视觉进行了革命性的改造,但目前的方法还有一些主要的问题需要解决:
- 典型的vision数据集的构造通常是需要**很多人工标注(labor intensive)**并且价格昂贵。
- 典型的vision模型大多只能在单一任务上发挥作用,迁移到其它任务的能力非常弱。
- 在benckmark上表现很不错的vision模型,通常在压力测试(比如对实际生产场景中的数据)中表现不佳
[2,3,4,5]。这让人们对基于深度学习的Computer Vision产生了怀疑。
OpenAI的大佬们(Alec Radford, Ilya Sutskever, Jong Wook Kim, Gretchen Krueger, Sandhini Agarwal)提出了CLIP来尝试解决这些问题。其中数据方面: 作者们的原话是: " it is trained on a wide variety of images with a wide variety of natural language supervision that’s abundantly available on the internet. " 这也就是说,OpenAI搜集了大量的互联网数据来训练CLIP这个多模态(multi-model)模型。通过设计,该网络可以用自然语言指导执行各种benchmark数据的分类任务,而无需直接优化基准的性能,类似于GPT-2[6]和GPT-3[7]的“zero-shot”能力。
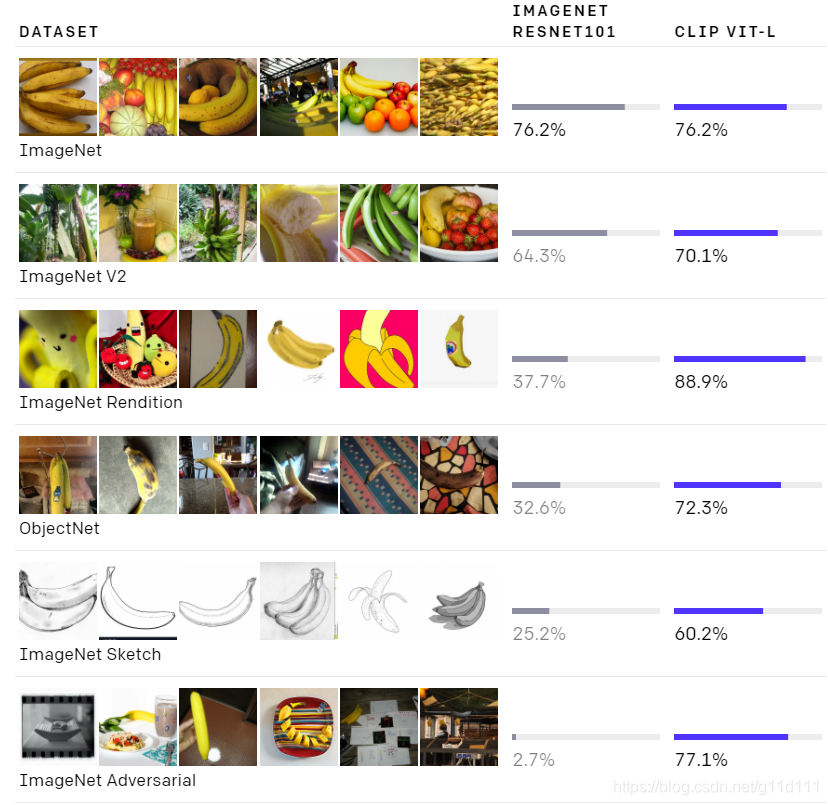
此处有一个关键的改变: 由于网络本身并没有直接对benchmark数据集进行优化(即没有对benchmark数据集进行finetune),而如下图的结果体现出了,CLIP模型的鲁棒性相比在IMageNet上训练的Resnet50,最好时要高出将近
75
%
75\%
75%。
尽管
CLIP和Resnet都在ImageNet的测试集有相同的精度,但是CLIP的性能更能代表它将在不同的,非imagenet的数据集(in the wild data)上的效果。例如,ObjectNet检查模型识别不同姿势和家庭背景下物体的能力,而ImageNet Rendition和ImageNet Sketch检查模型识别更抽象物体描述的能力。
2. 背景&相关工作
CLIP的全称是Contrastive Language-Image Pre-training,其架构建立在大量的zero-shot transfer, natural language supervision和multimodel learning的工作中。
关于zero-data learning的概念可以追溯在10前的工作了[8],虽然过去比较久了,但其实zero-data learning在目前(2021年)也是计算机视觉领域的最受人关注的研究方向,目标是让模型能在其处理未见过的数据时仍然能够保持良好的性能[9,10]。
一个重要的insight是利用自然语言作为一个 灵活的预测空间(a flexible prediction space) 来实现泛化和迁移。在2013年,斯坦福大学的Richer Socher和其合作者们发现[11],通过在CIFAR-10上训练一个模型,在**词向量嵌入空间(word vector embedding)**中进行预测,开发了一个概念证明,并表明该模型可以预测两个未见类。同年,DeVISE[12]将此方法的应用进行扩充,并证明了这种思路可以用于finetune一个ImageNet的网络模型,使模型能够 正确的预测除原始数据集提供的1000类以外的其它类别。
促成CLIP的诞生的最重要的论文当属Ang Li和其合作者在FAIR发表的论文 《Learning visual n-grams from web data》(ICCV2017), 用自然语言监督信号来让促成在一些现存的CV分类数据集(包含ImageNet数据集)实现zero-shot transfer。
他们通过对在ImageNet训练的CNN模型进行fine-tune,从3000万Flickr照片的标题、描述和标签的文本中预测出更广泛的视觉概念(视觉n-gram),并在ImageNet zero-shot上达到11.5%的准确性。
最后,CLIP属于根据自然语言监督信号来学习视觉表征的论文范畴。CLIP使用了更为先进的架构: Transformer[14],探索了自回归语言建模(autoregressive language modeling)的VirTex[15], ICMLM[16]: 研究了masked的语言模型, ConVIRT[17]: 研究和CLIP相同的目标,但是用在医疗成像领域。
3. 方法
CLIP作者们发现,可以仅凭对一个简单预训练任务进行scaling就可以在大量的图像分类数据集上达到良好的zero-shot性能。CLIP的方法使用了非常丰富的监督信号:
- 文本和其对应的图片对(互联网中找到)
此数据用于为CLIP创建以下代理训练任务: 给定一张图片,在我们的数据集中,从32,768个随机抽样的文本片段中,预测哪一个文本片段与该图片匹配。
为了解决这个任务,CLIP的作者的直觉想法是:让CLIP模型学习识别图片中的大量的visual concepts并将其与对应的文本名字联系起来。
结果是,CLIP模型可以被用于几乎任何视觉分类任务中。举个例子,如果一个数据集的任务是将进行猫狗的2分类,我们就会检查每个图像,看CLIP模型预测的文本描述“狗的照片”或“猫的照片”中哪个更有可能与此图像配对。
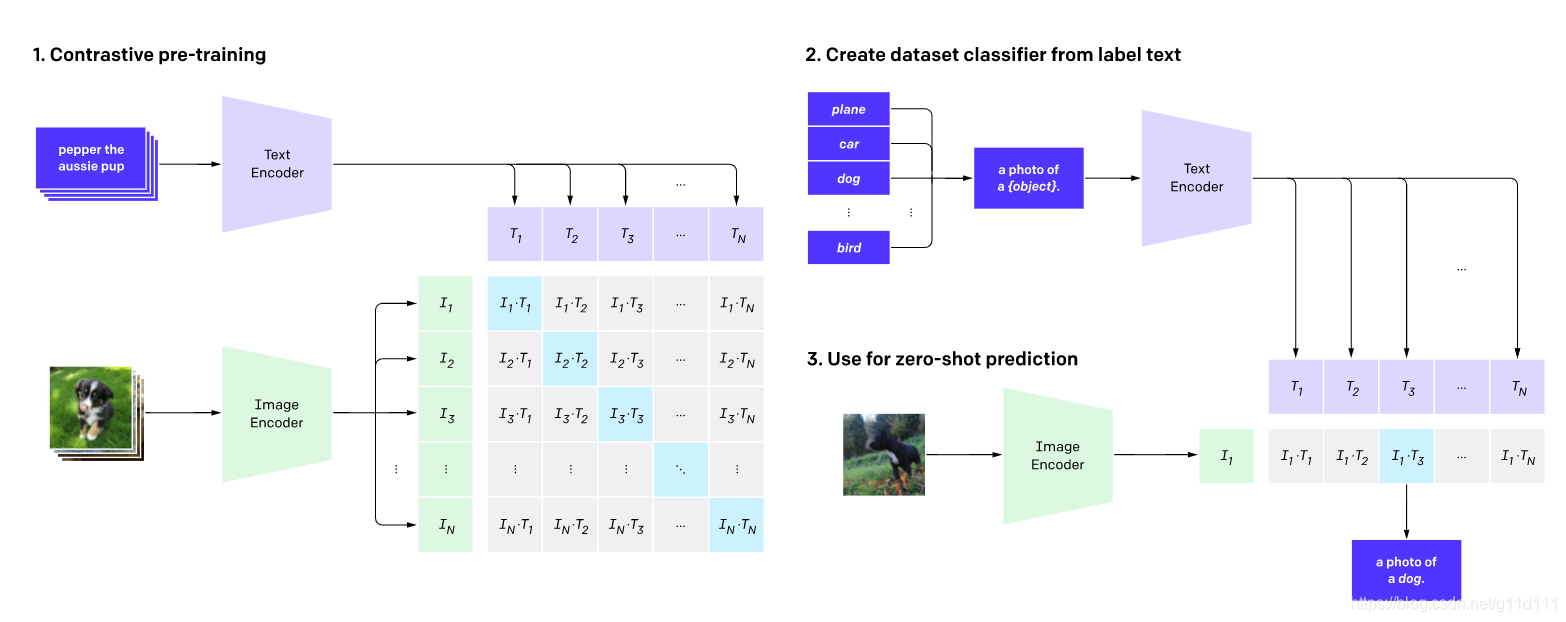
CLIP预训练一个image encoder和一个text encoder,训练的目标是让图片和文字被编码出的latent code匹配。我们利用这种思路,将CLIP转换为zero-shot分类器。我们将数据集的所有类别转换为标题,如“一张狗的照片”,并由CLIP预测图片的最佳配对文本。
设计CLIP的意义是缓解/减轻深度学习中的一些主要问题:
-
Costly datasets
深度学习需要大量的数据,通常来讲,视觉模型是使用大量的手工标注的数据集来进行训练的。这意味着构造此种数据集是一件昂贵且有限的事情(因为只能提供有限的visual concept)。CLIP通过学习互联网上大量的text-image pairs,这有效的减少了手工标注数据的复杂性和成本。减少对昂贵的大型标记数据集的需求已经在之前的工作中得到了广泛的研究,特别是self-supervised learning(自监督)[18,19,20], contrastive methods(对比学习)[21,22,23,24,25], self-training 方法[26,27]以及生成模型[28,29]。 -
Narrow
每个数据集都是有限的,没有一个能够包含所有类别数据的数据集。如果我们想要将在ImageNet上训练的模型用于其它的分类任务,那么这意味着我们需要构造一个新的数据集,并在这个新数据集上优化模型以期达到目标性能。
CLIP因为使用了大量的现成互联网数据,因此可以用于非常广泛的视觉分类任务中而无需额外的训练样本。而使用CLIP的方式也很简单,即告诉CLIP的text encoder,任务的visual concept的名称即可,它将输出CLIP的视觉表示的线性分类器。而这个分类器的准确性经常与fully supervised 模型相差不多。
下面是一些随机挑选的zero-shot CLIP分类器在不同数据上的效果:
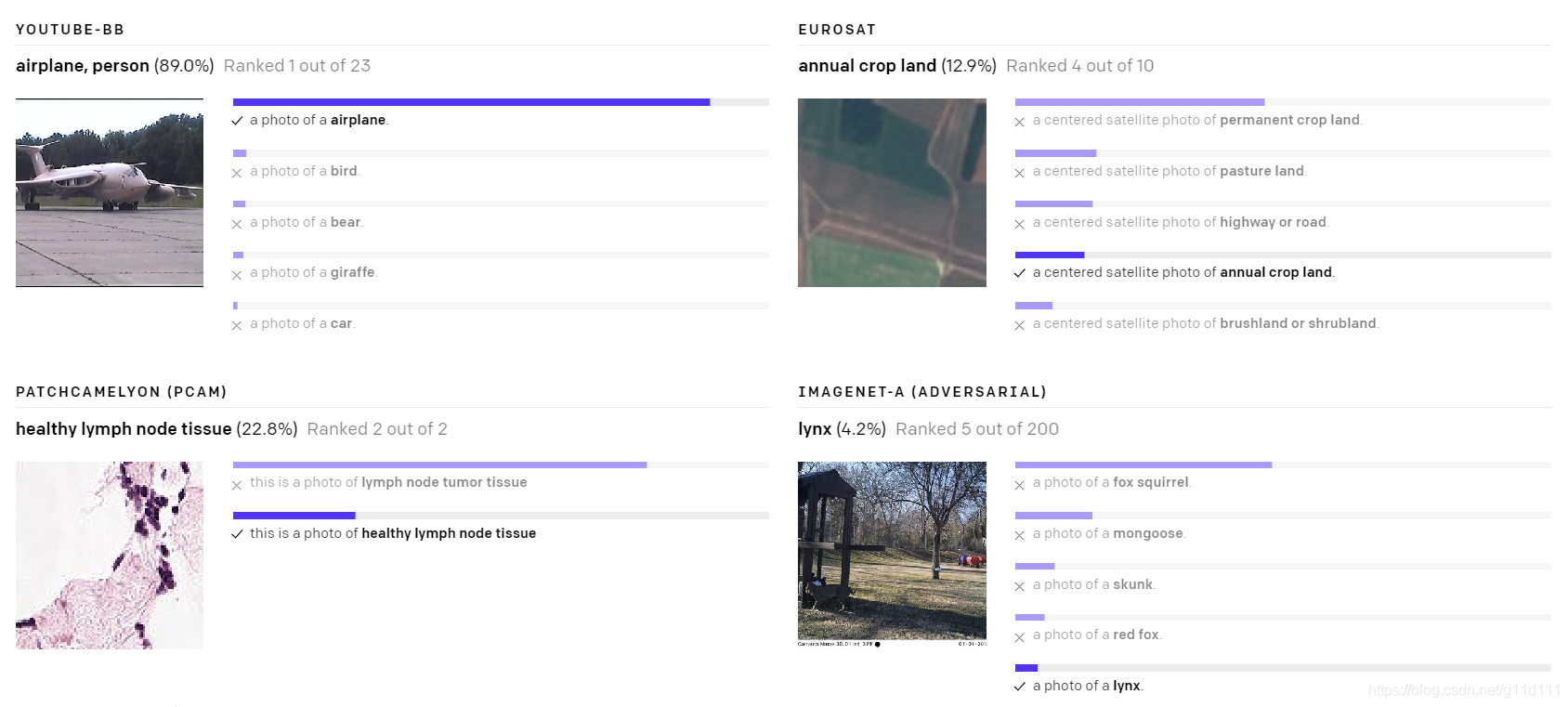
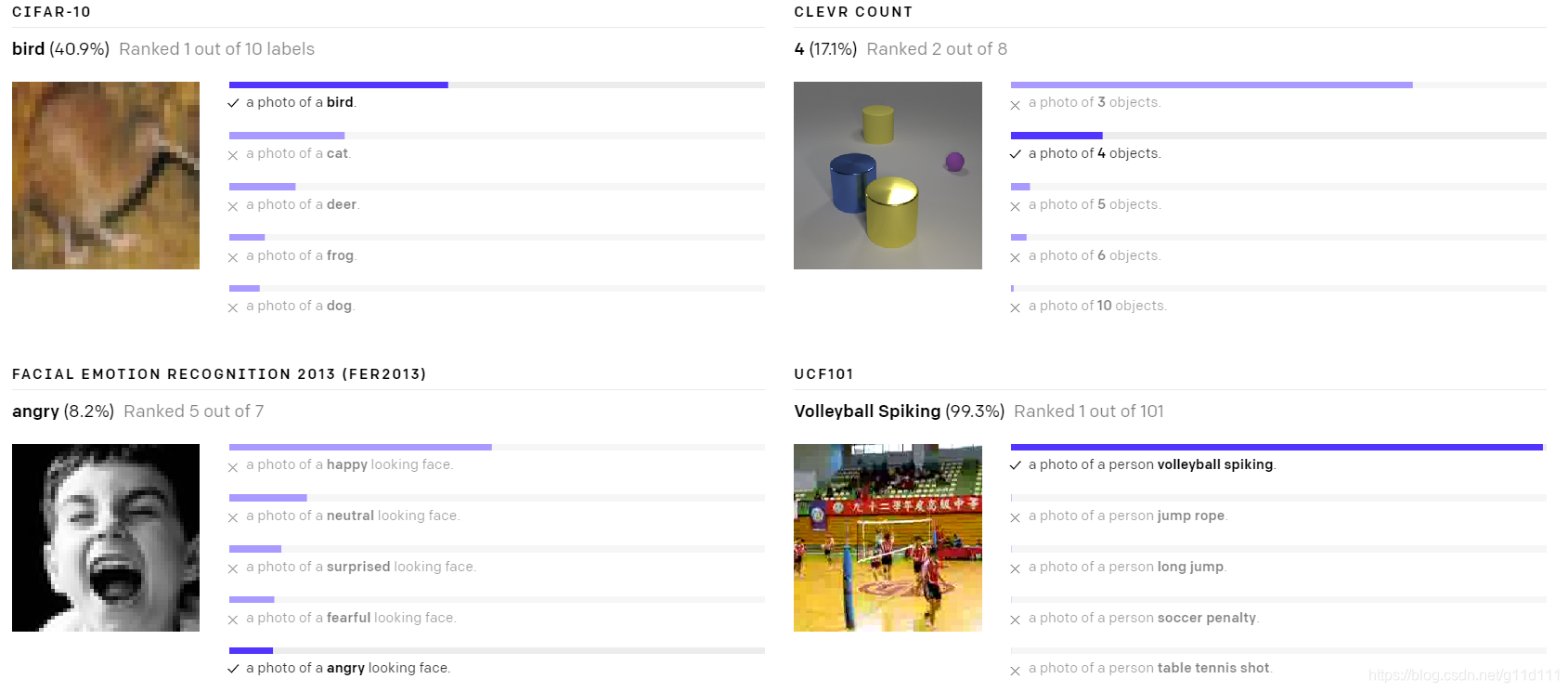
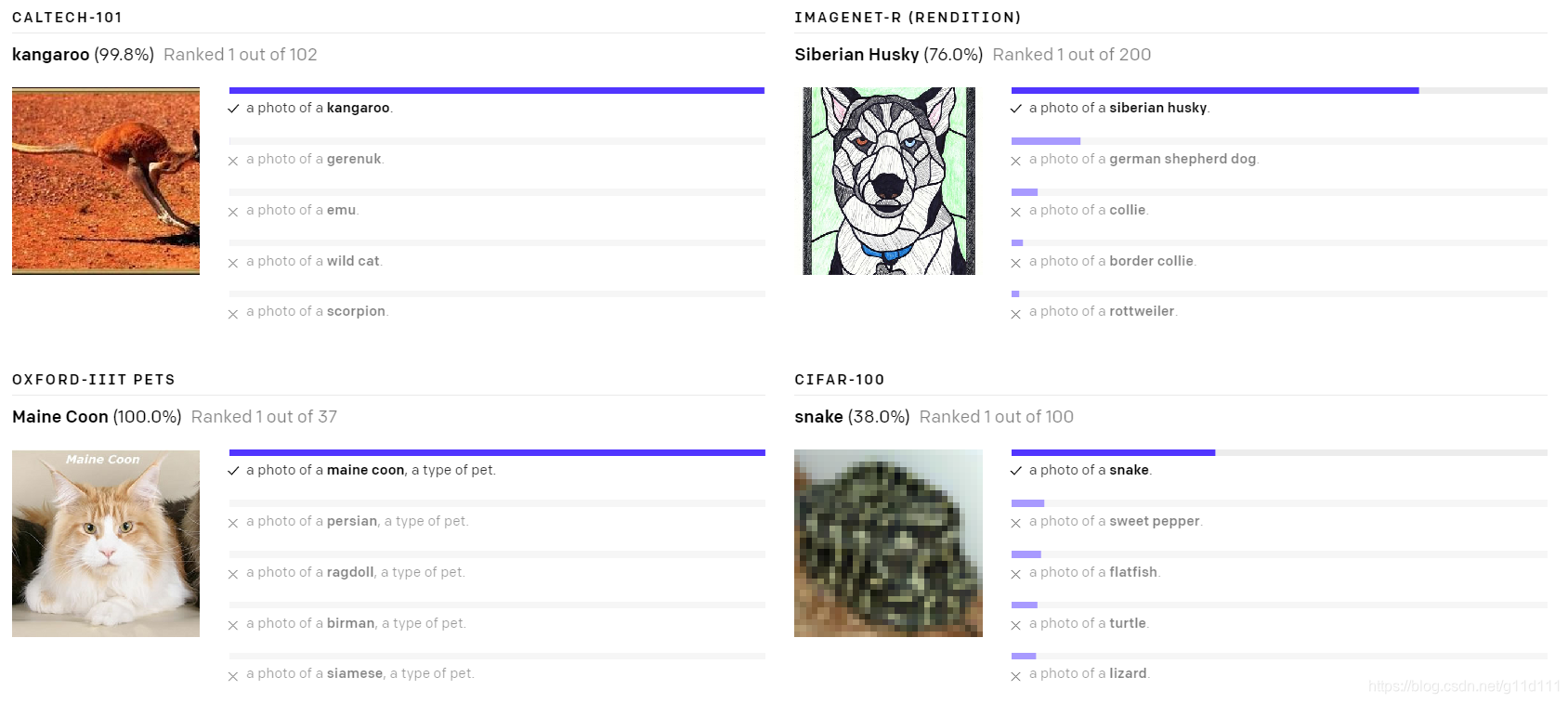
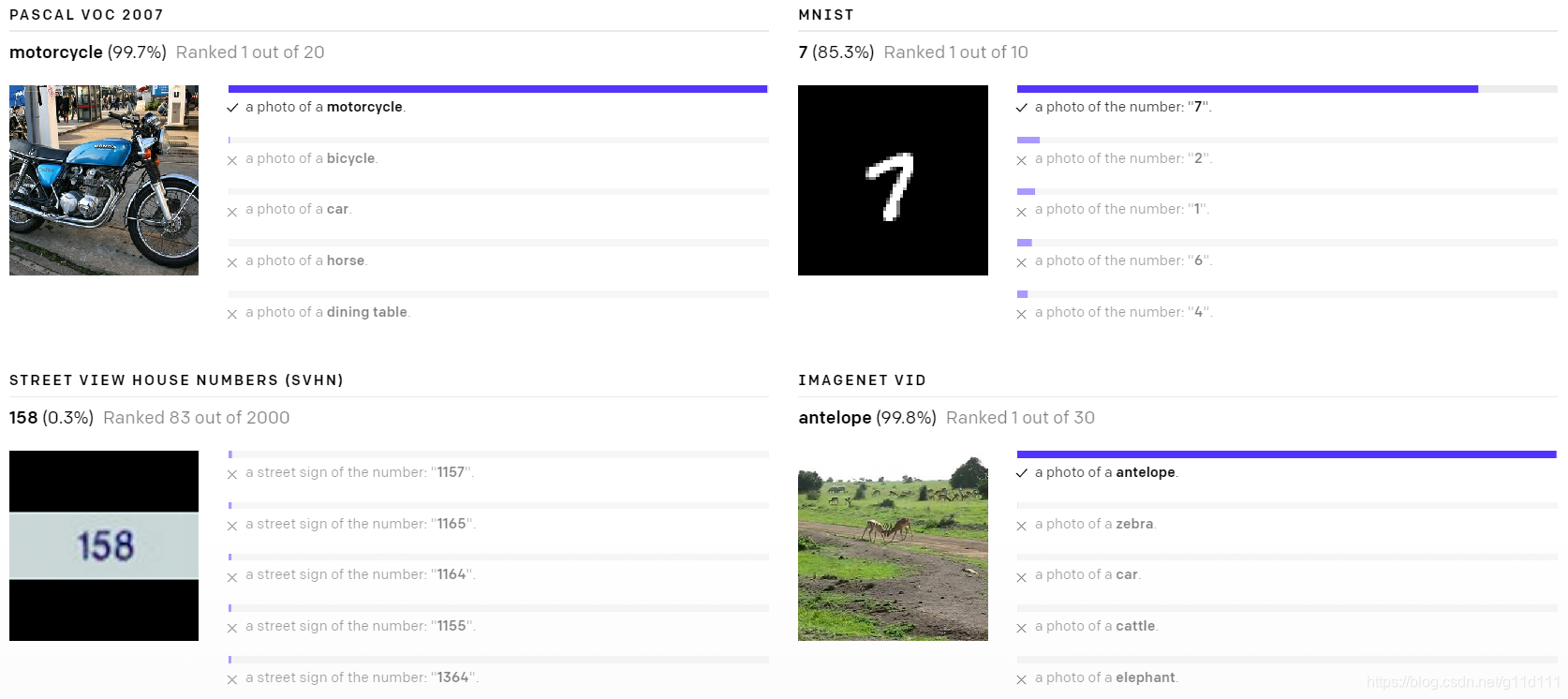
- Poor real-world performance
深度学习系统经常被宣传在一些vision benchmark上达到甚至超过人类水平。然而,对于in-the-wild数据,这些基于深度学习的视觉模型性能会出现很大的下降,远低于我们的预期。换句话说,在benchmark和real-world数据存在较大的gap。
我们推测,之所以会出现这种差距,是因为这些模型“作弊”,即只对benchmark数据集的性能进行优化,这很像一个学生只学习过去几年考试中的问题就通过了考试(没有良好的迁移和泛化能力)。
CLIP模型由于使用了大量的pair数据,因此不需要再去在这些具体的任务上finetune(因为CLIP的见多识广)。这使得它的benchmark测试的结果更能代表它在in-the-wild数据上的性能。
为了验证“cheating hypothesis”,作者们还测试了CLIP模型在ImageNet上“学习”时的性能变化。当一个线性分类器使用CLIP的特征上进行分类任务训练时,它将CLIP在ImageNet测试集上的精度提高了近
10
%
10\%
10%,但是这个现象在其它数据集上体现的并不明显[30]。
4. Key takeaways
4.1 CLIP is highly efficient
CLIP是从互联网中找的数据,特点是未经筛选,范围大,有大量的干扰数据影响,目标是被用于zero-shot范式。不同于GPT-2/3,CLIP的设计聚焦于减少所需算力,并提升训练的效率。
We report two algorithmic choices that led to significant compute savings.
在CLIP的实践中,有2个算法选择会极大的节省算力。
- ① 用contrastive objective来bridge gap between 图片和文本
在scaling小规模数据集的时候有极大的作用。
In small to medium scale experiments, we found that the contrastive objective used by CLIP is 4x to 10x more efficient at zero-shot ImageNet classification.
- ② 使用Vision Transformer
ViT[31]的使用相比传统Resnet有着近3倍的算力提升。OpenAI的最好的CLIP模型是在256个GPU上训练2周得到的。
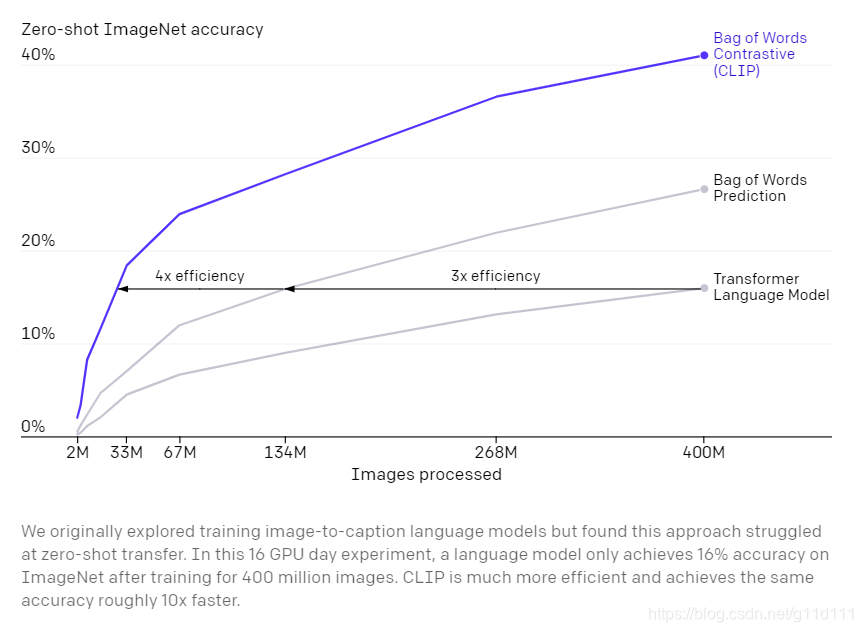
我们最初探索了训练图像到标题的语言模型,但发现这种方法很难实现zero-shot transfer。在实验中,在4亿图片上训练的语言模型(language model)只能在ImageNet上达到16%的准确率,而
CLIP的效率则要高的多,达到同样的精度的速度会比语言模型快10倍。
4.2 CLIP is flexible and general
由于可以学习到非常广泛的visual concept到自然语言的pair关系,CLIP模型显然比在ImageNet上训练的模型更加灵活和通用。
经过实验,作者发现CLIP可以在很多不同的任务上进行zero-shot迁移。为了验证性能,作者在超过30个不同的数据集上进行了CLIP的zero-shot的测试,包括: 细粒度目标分类(fine-grained object classification),视频动作识别(action recognition in videos),OCR等。
最好的CLIP模型在26个不同的迁移数据集中,在其中的20个数据集中超出了公开的最好的ImageNet模型以及Noisy Student EfficientNet-L2[27]。
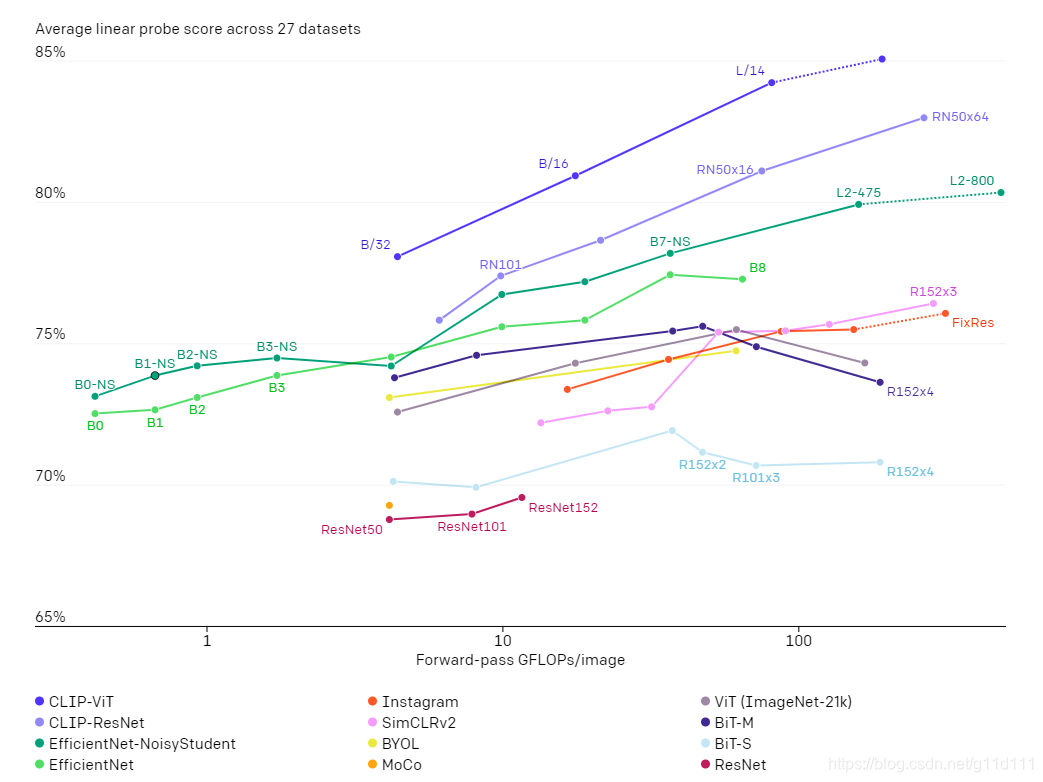
通过27个数据集的测试,如fine-grained object classification, OCR, activity recognition in videos, and geo-localization,我们发现
CLIP模型可以学习到更为有用的图像表征。CLIP模型也比我们之前比较的10种方法的模型计算效率更高。
5. 局限性和影响
5.1 局限性(Limitation)
CLIP目前在识别普通物体上的表现出不错的效果,但是对于更加抽象或者更为系统的任务,如: 数图片中物体的数量, 在一张图片中预测最近的车有多近,就无能为力了。
在这种情况下,zero-shot的CLIP模型和随机猜测的效果差不多。。。同样,对于细粒度分类任务,比如说: 区分不同汽车的细节, 不同的飞机类型或者花朵的种类,也表现不佳。
对于未包含在其预训练数据集中的图像,CLIP的泛化效果也很差。例如,尽管CLIP学习了一个有效的OCR系统,但当从MNIST数据集评估效果时,zero-shot CLIP仅达到88%的准确率,远低于数据集上99.75%的人类识别的准确率。
最后,作者观察到CLIP的zero-shot分类器对于措辞非常敏感,有时候需要一些微调甚至错误的表述(“prompt engineering”),才能有良好的表现。
5.2 广泛影响(broader impact)
CLIP允许研究人员和机器学习从业者们在设计分类器时需要对特定任务数据的要求。但这种方式也会严重影响模型性能和模型的bias(例子见原文[1])。
此外,由于CLIP不是需要task-specific training的模型,其可以容易的解锁/处理一些不确定的任务。其中一些任务可能会增加隐私或监视相关的风险,我们通过研究CLIP在名人身份识别中的表现来探讨这一问题。
CLIP 对"in the wild"名人数据集有着很高的top-1准确率
| 100 candidates | 1000 candidates |
|---|---|
| 59.2% | 43.3% |
尽管这是通过task-agnostic(任务无关)的预训练达到的效果。但是这种性能是无法真正的应用在实际的工业级应用中的。
在论文中,作者们进一步探索CLIP提出的挑战,作者们希望这一工作能够推动未来对这些模型的能力、缺点和偏见的表征的研究。并且很高兴能与研究团体就这类问题进行交流(多模态。。。)。
6. 结论
通过CLIP的提出,作者们测试了对于在互联网规模级别的自然语言上预训练的模型上的 不可知任务(task agnostic) 的效果,这种预训练的方式(GPT-2/3)不但在NLP领域带来了极大的突破,也可以被用于提高深度学习中其它领域的性能。
从上面的实验结果看来,CLIP这种预训练模型在CV方向也有着很强的性能(就像GPT-2/3之于NLP领域那样)。CLIP的作者们在ImageNet上的发现表明,zero-shot的性能是一个模型能力的更有代表性的衡量标准。
Reference
[1]: CLIP: Connecting Text and Images
[2]: Dodge, S., & Karam, L. (2017, July). “A study and comparison of human and deep learning recognition performance under visual distortions.” In ICCCN 2017.
[3]: Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F. A., & Brendel, W. (2018). “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.” In ICLR 2019.
[4]: Alcorn, M. A., Li, Q., Gong, Z., Wang, C., Mai, L., Ku, W. S., & Nguyen, A. (2019). “Strike (with) a pose: Neural networks are easily fooled by strange poses of familiar objects.” In CVPR 2019.
[5]: Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., … & Katz, B. (2019). “Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models.” In NeurIPS 2019.
[6] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). “Language Models are Unsupervised Multitask Learners.” Technical Report, OpenAI. ↩︎
[7] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). “Language Models are Few-Shot Learners.” In NeurIPS 2020. ↩︎
[8] Larochelle, H., Erhan, D., & Bengio, Y. (2008, July). “Zero-data learning of new tasks.” In AAAI 2008. ↩︎
[9] Lampert, C. H., Nickisch, H., & Harmeling, S. (2009, June). “Learning to detect unseen object classes by between-class attribute transfer.” In CVPR 2009. ↩︎
[10] Lei Ba, J., Swersky, K., & Fidler, S. (2015). “Predicting deep zero-shot convolutional neural networks using textual descriptions.” In ICCV 2015. ↩︎
[11] Socher, R., Ganjoo, M., Manning, C. D., & Ng, A. (2013). “Zero-shot learning through cross-modal transfer.” In NeurIPS 2013. ↩︎
[12] Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Ranzato, M. A., & Mikolov, T. (2013). “Devise: A deep visual-semantic embedding model.” In NeurIPS 2013. ↩︎
[13] Li, A., Jabri, A., Joulin, A., & van der Maaten, L. (2017). “Learning visual n-grams from web data.” In Proceedings of the IEEE International Conference on Computer Vision 2017. ↩︎
[14] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). “Attention is all you need.” In NeurIPS 2017.
[15] Desai, K., & Johnson, J. (2020). “VirTex: Learning Visual Representations from Textual Annotations.” arXiv preprint.
[16] Sariyildiz, M. B., Perez, J., & Larlus, D. (2020). “Learning Visual Representations with Caption Annotations.” In ECCV 2020.
[17] Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., & Langlotz, C. P. (2020). “Contrastive Learning of Medical Visual Representations from Paired Images and Text.” arXiv preprint.
[18] Doersch, C., Gupta, A., & Efros, A. A. (2015). “Unsupervised visual representation learning by context prediction.” In ICCV 2015. ↩︎
[19] Zhai, X., Oliver, A., Kolesnikov, A., & Beyer, L. (2019). “S4l: Self-supervised semi-supervised learning.” In ICCV 2019. ↩︎
[20] Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P. H., Buchatskaya, E., … & Piot, B. (2020). “Bootstrap your own latent: A new approach to self-supervised learning.” In NeurIPS 2020. ↩︎
[21] Oord, A. V. D., Li, Y., & Vinyals, O. (2018). “Representation Learning with Contrastive Predictive Coding.” arXiv preprint. ↩︎ ↩︎
[22] Hjelm, R. D., Fedorov, A., Lavoie-Marchildon, S., Grewal, K., Bachman, P., Trischler, A., & Bengio, Y. (2018). “Learning deep representations by mutual information estimation and maximization.” In ICLR 2019. ↩︎
[23] Bachman, P., Hjelm, R. D., & Buchwalter, W. (2019). “Learning representations by maximizing mutual information across views.” In NeurIPS 2019. ↩︎
[24] He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). “Momentum contrast for unsupervised visual representation learning.” In CVPR 2020. ↩︎
[25] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). “A simple framework for contrastive learning of visual representations.” arXiv preprint. ↩︎
[26] Lee, D. H. (2013, June). “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks.” In Workshop on challenges in representation learning, ICML (2013). ↩︎
[27] Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020). “Self-training with noisy student improves imagenet classification.” In CVPR 2020.
[28] Kingma, D. P., Mohamed, S., Jimenez Rezende, D., & Welling, M. (2014). “Semi-supervised learning with deep generative models.” In NeurIPS 2014. ↩︎
[29] Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). “Improved techniques for training gans.” In NeurIPS 2016. ↩︎
[30] Taori, R., Dave, A., Shankar, V., Carlini, N., Recht, B., & Schmidt, L. (2020). “Measuring robustness to natural distribution shifts in image classification.” In NeurIPS 2020. ↩︎
[31] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Uszkoreit, J. (2020). “An image is worth 16x16 words: Transformers for image recognition at scale.” arXiv preprint.

















 2999
2999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









