









 本文介绍了使用Python构建记忆游戏的步骤:1.生成16个随机数并打乱顺序;2.管理每张卡片的显示状态;3.定义点击卡片的不同状态;4.判断点击的两张卡片是否匹配;5.绘制匹配的卡片到画布上。通过if-else语句和条件判断,实现了游戏的核心逻辑。
本文介绍了使用Python构建记忆游戏的步骤:1.生成16个随机数并打乱顺序;2.管理每张卡片的显示状态;3.定义点击卡片的不同状态;4.判断点击的两张卡片是否匹配;5.绘制匹配的卡片到画布上。通过if-else语句和条件判断,实现了游戏的核心逻辑。
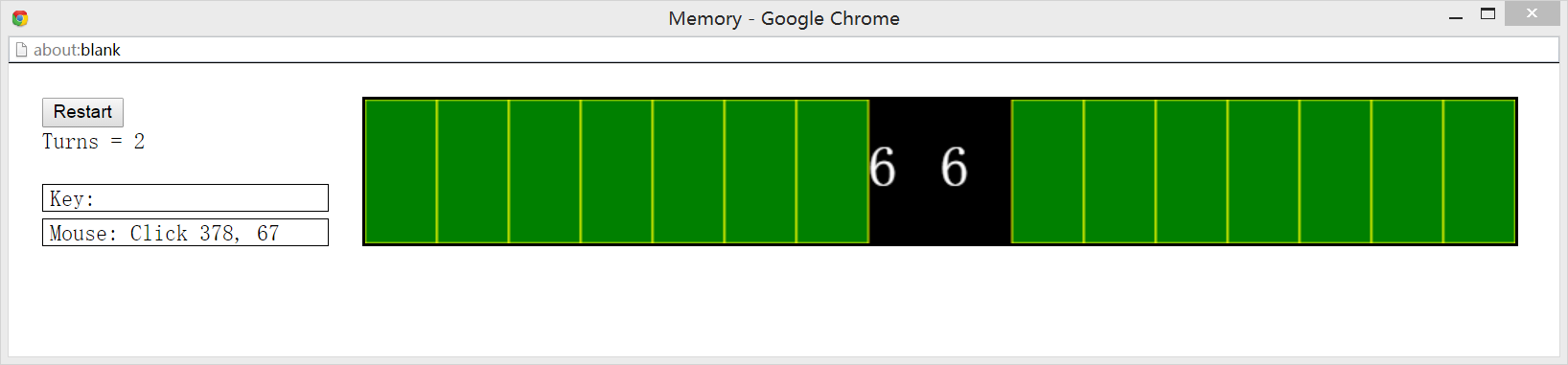
1,生成16个数(new game())
用到range,num.extend(),及random.shuffle()函数
2,每张卡片是否显示其值的状态
exposed = True or False
3,判定点击卡片时所处的状态(if,else语句)
通过常量state=0,1,2,,划定点击的状态,即点击前0,点击一张卡片后的状态1,点击2张卡片的状态2
4,判断点击的两张卡片 的值是否相等(if,else语句)
如果实现这一步就必须知道点击每张卡片的序列,通过num[index1]是否等于num[index2]
index =pos[0]/(卡片的宽度),pos[0]代表鼠标点击的横坐标
5,draw(canvas):
用for循环显示exposed=True的卡片 即连续点击的两个数值相等的卡片
for n in num:
if exposed[index]:
canvas.set_text(str(n), (position, 60), 46,”White”)
…….
具体程序如下
# implementation of card game - Memory
import simplegui
import random
turns=0
state=0
num=[]
fir_index=0
sed_index=0
# helper function to initialize globals
def new_game():
global state, turns,num,fir_index,sec_index,exposed
num=range(0,8)
num.extend(range(0,8))
random.shuffle(num)
exposed=[False]*16
turns=0
# define event handlers
def mouseclick(pos):
# add game state logic here
global state, exposed, fir_index, sec_index, turns
index=pos[0]/50
if not exposed[index]:
exposed[index]=True
if state==0:
state=1
fir_index=index
elif state==1:
state=2
sec_index=index
elif state==2:
if num[fir_index]!=num[sec_index]:
exposed[fir_index]=False
exposed[sec_index]=False
state=1
fir_index=index
turns+=1
# cards are logically 50x100 pixels in size
def draw(canvas):
global num
position=0
index=0
label.set_text("Turns= "+ str(turns))
for n in num:
if exposed[index]:
canvas.draw_text(str(n), (position, 60), 40, "White")
else:
canvas.draw_polygon([(position, 0), (position, 100),(position+50, 100),(position+50, 0)],1,"Yellow","Green")
position += 50
index += 1
# create frame and add a button and labels
frame = simplegui.create_frame("Memory", 800, 100)
frame.add_button("Reset", new_game)
label = frame.add_label("Turns = 0")
# register event handlers
frame.set_mouseclick_handler(mouseclick)
frame.set_draw_handler(draw)
# get things rolling
new_game()
frame.start()
# Always remember to review the grading rubric














 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









