






需要了解的概念:







ODS层所需的工作

拿到数据以后看各个字段的数据是否有空值 重复

查看数据是否不符合规范,如果有,就要跟业务方沟通
DWD层所需的工作
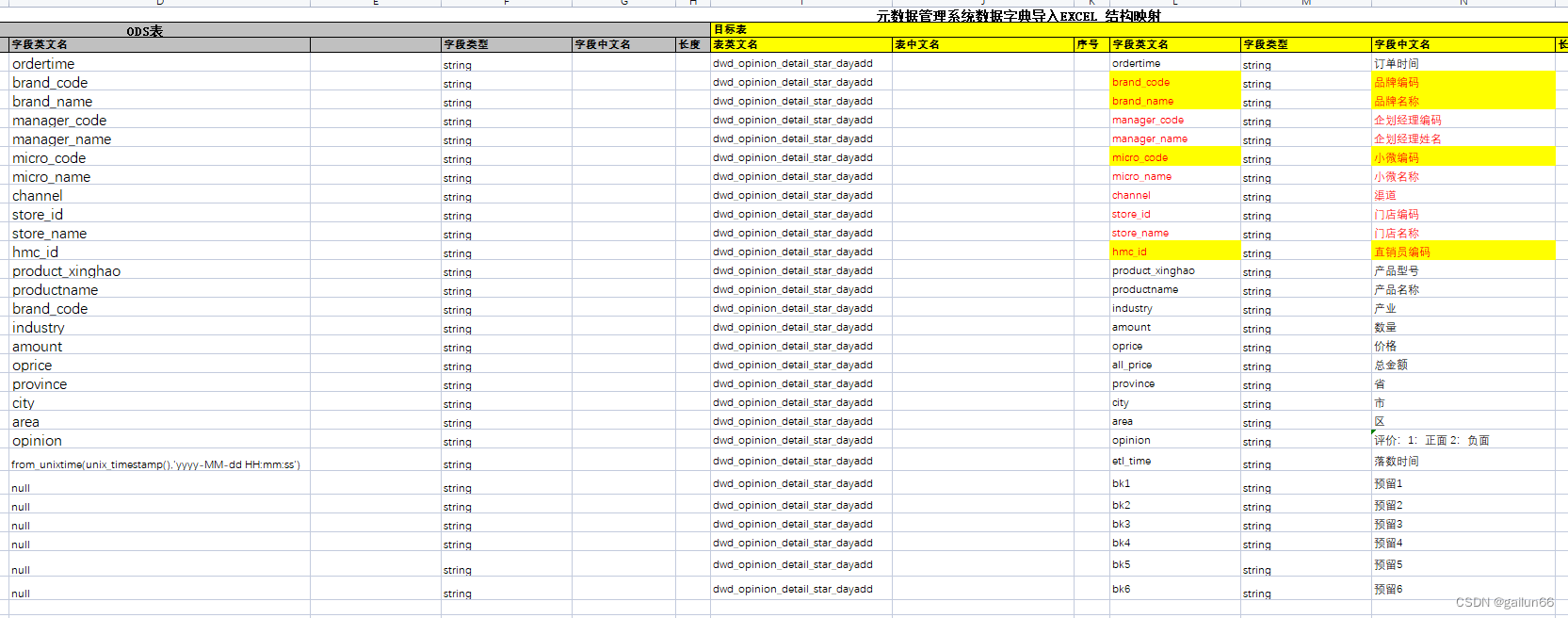
1 整理数据映射文档
1.1 使用excel将ods明细表和维度表中的字段提取出来整理成数据字典
ods中的维度表字段过于简单,可以直接加工成dim表(复杂的dim维度表也要写映射)
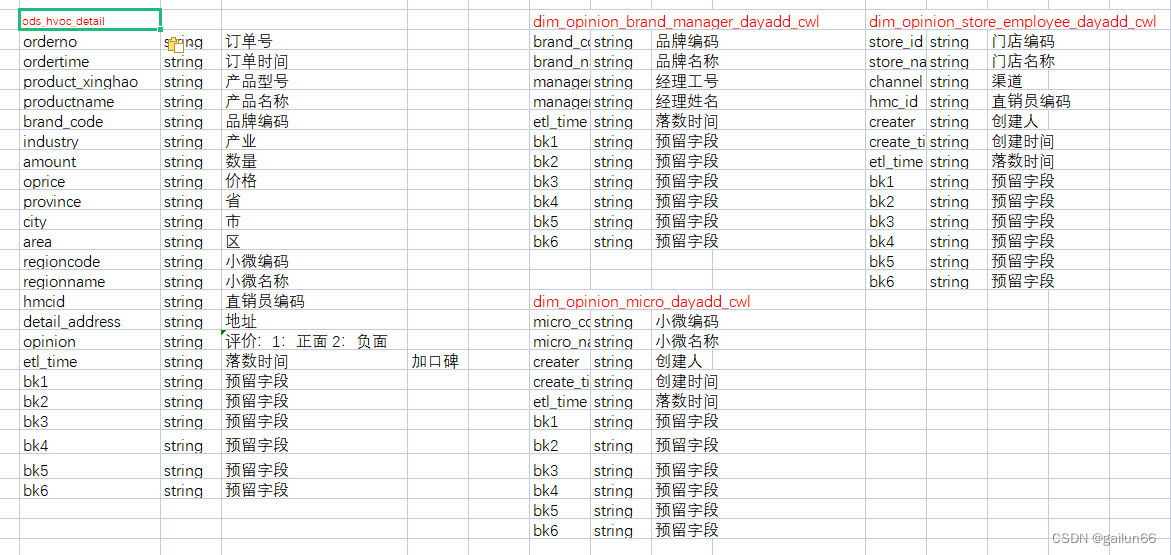
1.2 根据指标,标明关键字段,去除无用字段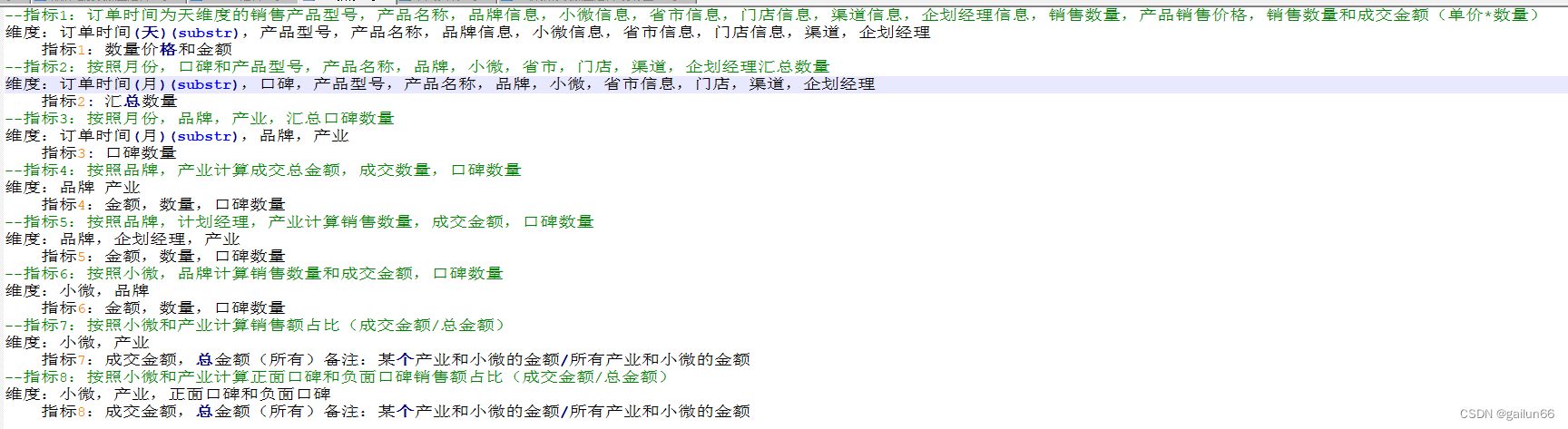
这三个字段是关联维度表的三个字段(JOIN ON的条件)

这是维度表中有用的字段

1.3 构建dwd事实表(明细表)映射关系文档
dwd层事实表(明细表)一般是把ods层的明细表和维度表的关键字段整合到一张表中
其中包括时间 维度 事实
dwd层事实表字段根据重要程度排序

时间
维度
事实


2 建表
DWD层 事实表(宽表)命名规范
dwd_需求主题_业务主题_star_dayadd(每日更新)
DIM 模型表(维度表)命名规范
dim_需求主题_维度主题_star_dayadd
2.1 根据数据字典建立dim维度表

注意品牌维度表在插入数据时需要brand和brand_manager两张ods表


2.2 根据映射文档构建dwd事实表(明细表)

3 插入数据
插入数据时使用where过滤脏数据
![]()




4 清空表中数据的方法:
工作中可能没有直接truncate的权限,可以用这种方法
INSERT overwrite TABLE 表名 PARTITION(dt='')
SELECT
所有字段(除了分区)
from 表名
where 1=0;
ADS应用层处理指标
观察指标

先确定维度字段,再确定指标字段

注意:
订单时间的粒度是天和月
建立指标表的过程(多张表)
根据维度建立指标表
每个指标对应一张表,复制粘贴即可,较为简单



指标4和指标5可以出自一张表(总金额这个字段可以累计)




7和8的指标可以出自一张表
建立指标表的过程(一张表)
打标签:
维度:订单时间,订单月份,产品型号,产品名称,品牌信息,小微信息,省市信息,门店信息,渠道,企划经理,产业,正负口碑(where)
指标类型(1-8),指标值1,指标值2
罗列法:
维度:订单时间,订单月份,产品型号,产品名称,品牌信息,小微信息,省市信息,门店信息,渠道,企划经理,产业,正负口碑(where)
指标1,指标2,指标3。。。指标8
打标签法
维度字段:将所有指标的维度都加上
指标类型:指标数决定
指标值:(1:value 2:value 3:value)
如果指标值很多就AS预留字段


罗列法

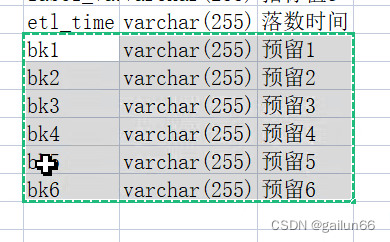

为什么左边少两个维度?
插入数据
分表

有几个指标就insert几次
打标签
有几个指标就insert几次
如果某个指标类型的指标值没有那么多,那么插入数据的时候插入空值即可
这里做指标1的时候使用shell脚本传递dt参数 后续全部使用
concat(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),'-指标类型')
指标1



指标1采用shell脚本传参的方式指定dt分区,后面几个指标全部采用时间戳函数
指标2

hdfs dfs -chmod -R 777 /tmp/hadoop-yarn
set hive.exec.dynamic.partition.mode=nonstrict;

指标7
写法1

不建议用这种写法
写法2
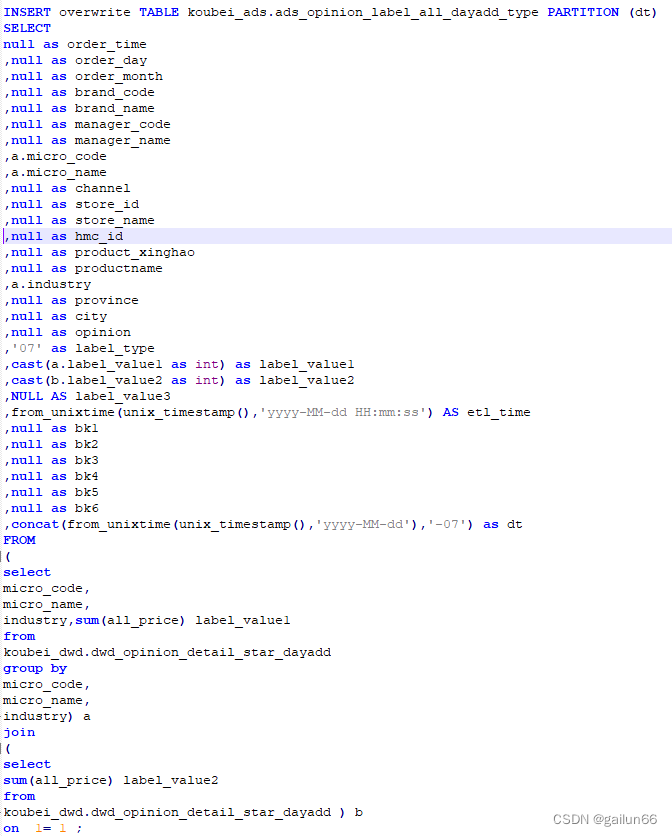
join on 1=1相当于cross join,即使没有关联条件,也会将两个表关联起来
调试报错?
hdfs dfs -chmod -R 777 /tmp/hadoop-yarn


罗列
维度一样,指标

有几个指标就insert几次,只填一个指标,其他指标为null
对数(自测)
怎么找测试用例?
找出能证明业务对象具有唯一性 典型性 代表性的字段 比如订单号
测试结果一般写在word中
ods和dwd的对数环节
在ods层找出若干个限定条件,在dwd层查询,看是否与ods层数据一致
ods层编写测试用例并与dwd层对比



ods和ads的对数环节
dwd和ads的对数环节
dwd层编写测试用例并与ads层对比


反思:
整个开发流程最为重要的两个环节
1.建模
包括建表 设计字段
2.开发指标
熟悉业务,较强的sql逻辑能力
dt的两种传参方式
第一种
![]()
![]()
![]()
第二种
![]()
加工指标表的时候注意最细粒度
比如订单时间还可以分为 每天的订单和每月的订单
分表 打标签 罗列法的优势和注意事项?
注意:
建立指标表的时候最好按维度和指标的先后顺序排列表中字段,后续方便比对
静态分区和动态分区的对比
静态分区,直接指定分区为all 将所有时间 所有指标都放在其中
INSERT overwrite TABLE koubei_ads.ads_opinion_label_all_dayadd_type_02 PARTITION (dt='all-08') 第八个指标
![]()
动态分区,以时间划分
INSERT overwrite TABLE koubei_ads.ads_opinion_label_all_dayadd_type PARTITION (dt)
concat(from_unixtime(unix_timestamp(),'yyyy-MM-dd'),'-08') as dt
静态分区
①静态分区是在编译期间指定的指定分区名
②支持load和insert两种插入方式
load方式
会将分区字段的值全部修改为指定的内容
一般是确定该分区内容是一致的时候才会使用
insert方式
必须先将数据放在一个没有设置分区的普通表中
该方式可以在一个分区内存储一个范围的内容
从普通表中选出的字段不能包含分区字段
③适用于分区数少,分区名可以明确的数据
动态分区
①根据分区字段的实际值,动态进行分区
②是在sql执行的时候进行分区
③需要先将动态分区设置打开
④只能用insert方式
⑤通过普通表选出的字段包含分区字段,分区字段放置在最后,多个分区字段按照分区顺序放置
静态分区和动态分区的应用场景
静态分区:适合已经确认分区的文件,分区相对较少的,适合增量导入的应用场景
动态分区:适合根据时间线做分区,分区比较多的,适合全量导入的场景
字段问题
对数的时候我发现dwd没有订单号这个字段,导致对数过程比较麻烦,以后建立dwd明细表的时候记得添加一些有代表性的字段
















 2211
2211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









