









【五】情感支撑对话论文最近进展 Emotion Support Conversation
今天给大家分享一篇在KBS的关于情感对话的论文。主要思想是从利用用户的情感反馈信息来进行策略选择,并且帮助生成支撑性的回复。
相关情感支撑论文综述整理指路 -> 点这里
FADO:
FADO: Feedback-Aware Double COntrolling Network for Emotional Support Conversation
分以下四部分介绍:
- Motivation
- Challenges & Contributations
- Model
- Experiment
- Discussion
动机
- 先前的工作在做策略选择时,往往考虑使用上下文信息,在情感支撑对话中,情感信息是一个关键因素,而这些工作忽略了用户的情感对策略选择的重要性。
- 以往的工作根据上下文的信息选择策略,是单向的。然而,策略的信息也可以反过来帮助系统对上下文进行过滤,使得模型更能关注到策略约束的上下文,起到过滤噪音的作用。
挑战
- 情绪和策略之间存在什么关系?如何将情绪信息融入,进行策略选择?
- 如何建立策略信息和上下文信息之间的双向流动信息?
解决方案
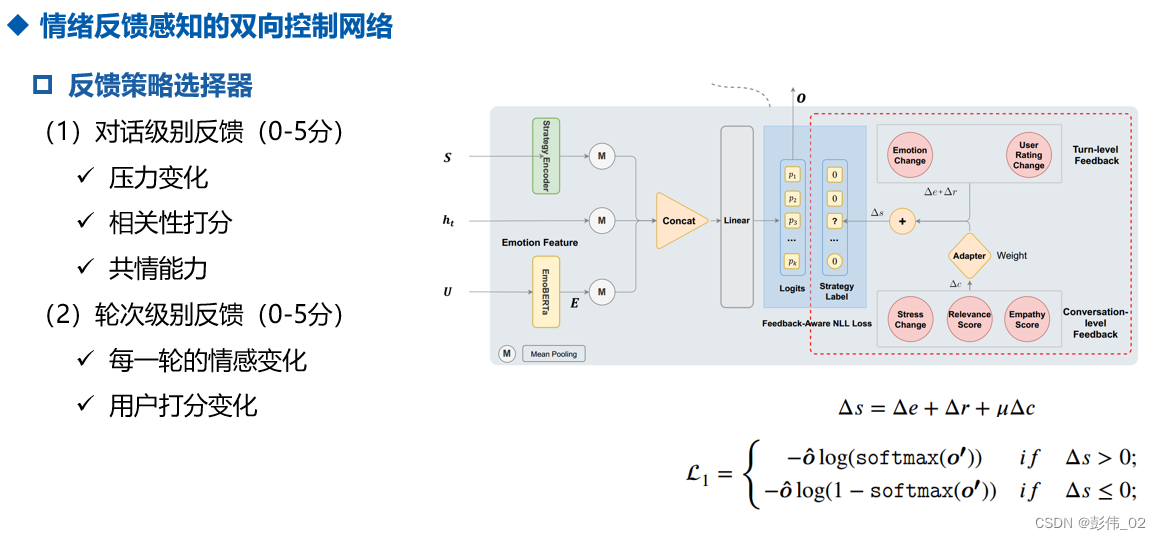
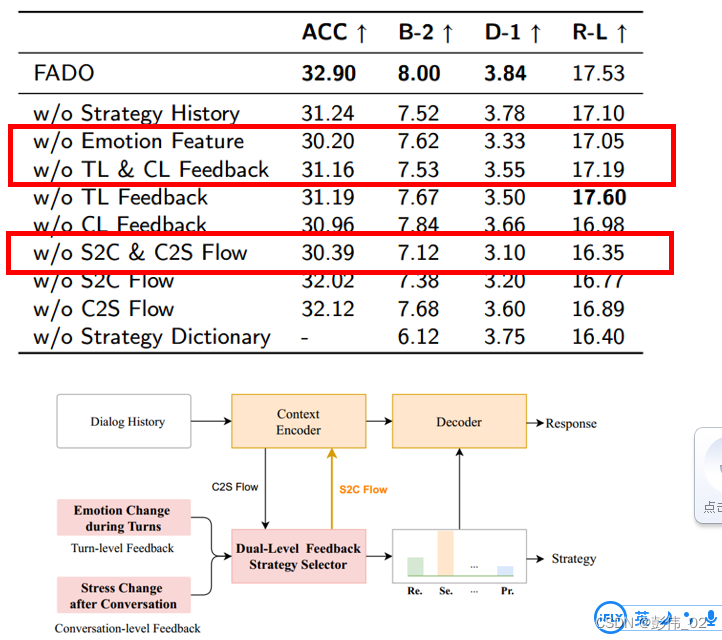
- 为了进行更准确以及用户相关的策略选择,本文提出Dual-Level Feedback Strategy Selector (DFS)融入用户情感反馈选择合适的策略。
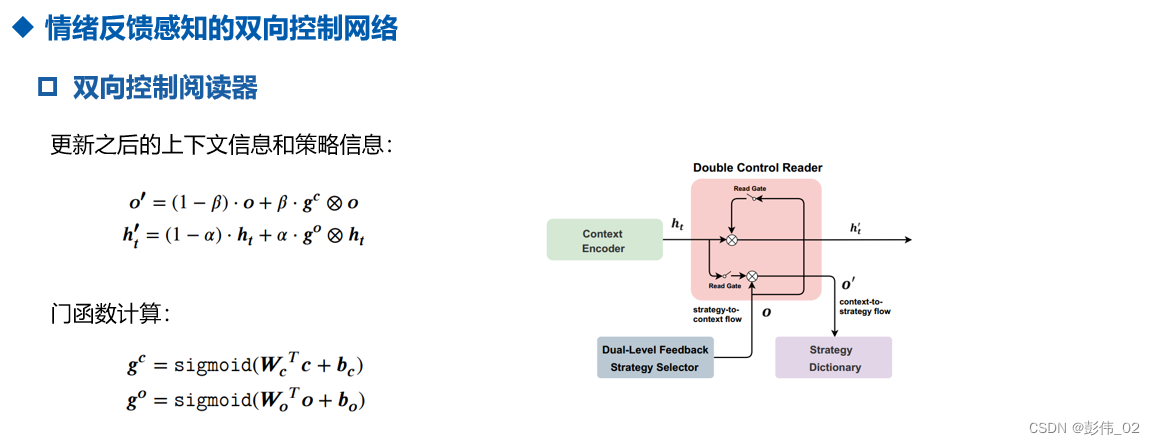
- 为了关注到策略约束的上下文信息,本文提出Double Control Reader (DCR)建模两者信息流。
通过一个例子来说明我们的工作:
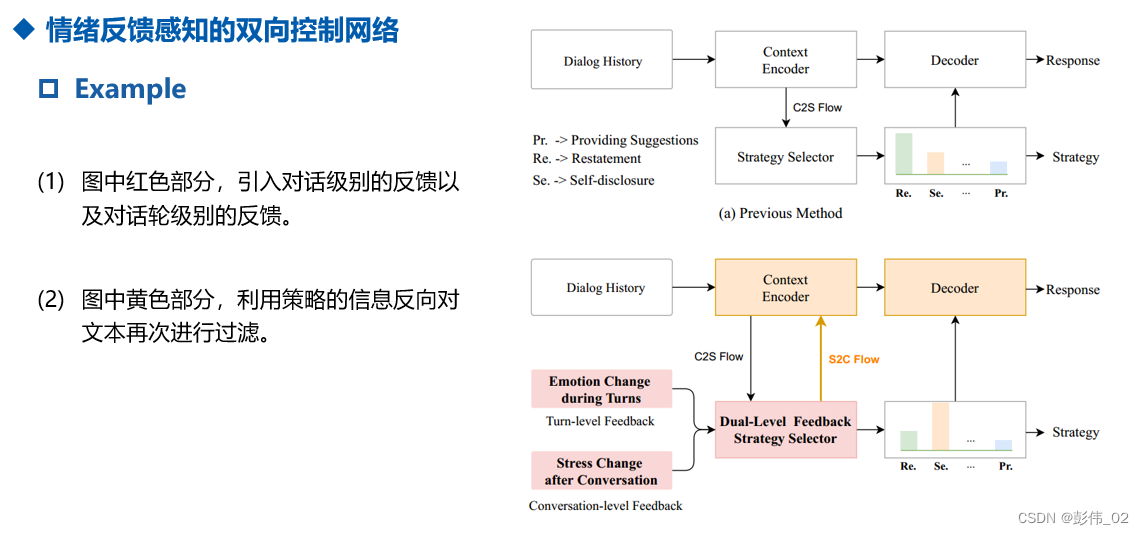
模型总体结构图

- 其中,编码部分的计算:
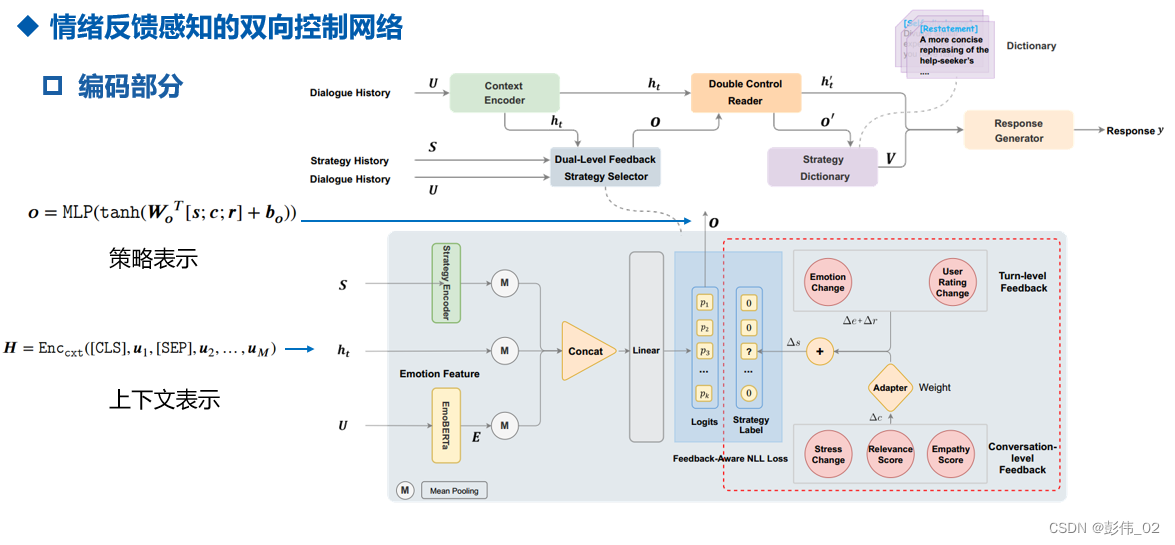
- 当用户表现出正向的情感,我们认为策略和对话的进行是值得被优先考虑的,如果用户表现出负面的情感,那当前所采取的策略在未来的阶段应该给予更低的优先级。
- 情感反馈的计算包含两个方面,第1个方面是对话级别的反馈计算,第2个方面是turn级别的反馈计算。当情绪反馈是正向的,我们便正常去优化策略的选择;如果情绪反馈是负向的,那么我们对当前选择的策略应该尽量去避免。即:从反面来说应该更多的考虑其他的策略。
- 我们会把更新之后的上下文表示和策略表示通过双向阅读器进行控制,来获得更新之后的表示信息。
- 这一部分模型的动机在于在情感支撑对话当中所选择的策略不同,关注的上下文信息应该是不一致的,比如说当所选择的策略是复述,那我们对上下文应该去进行一个平均的注意力的分布(即所有的信息都应该被考虑);如果策略是提问,那我们更应该关注用户所描述的问题。
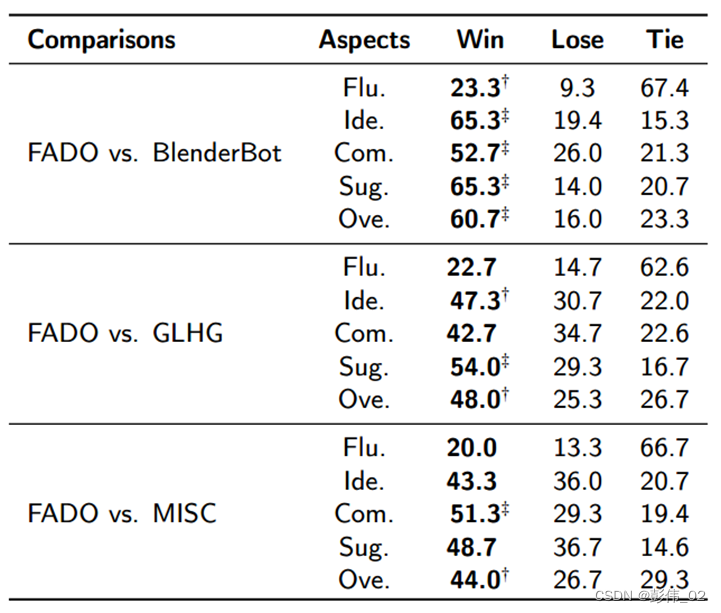
实验结果
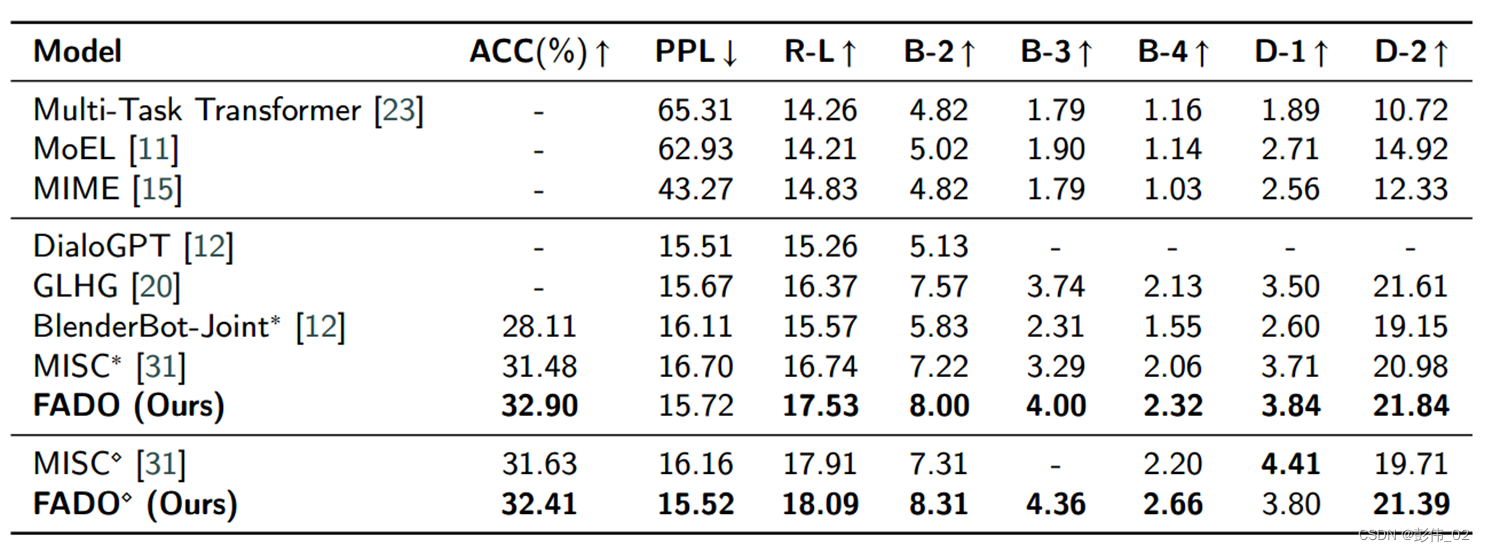
人工实验
消融实验
可视化实验
- 我们模型输出的策略分布跟真实的场景之下的策略分布更相似。
- 相比较当前最好的模型,我们的模型在对话结束时OTHER策略相对较少。
- 同理,在对话开始时,question策略概率不是太高。

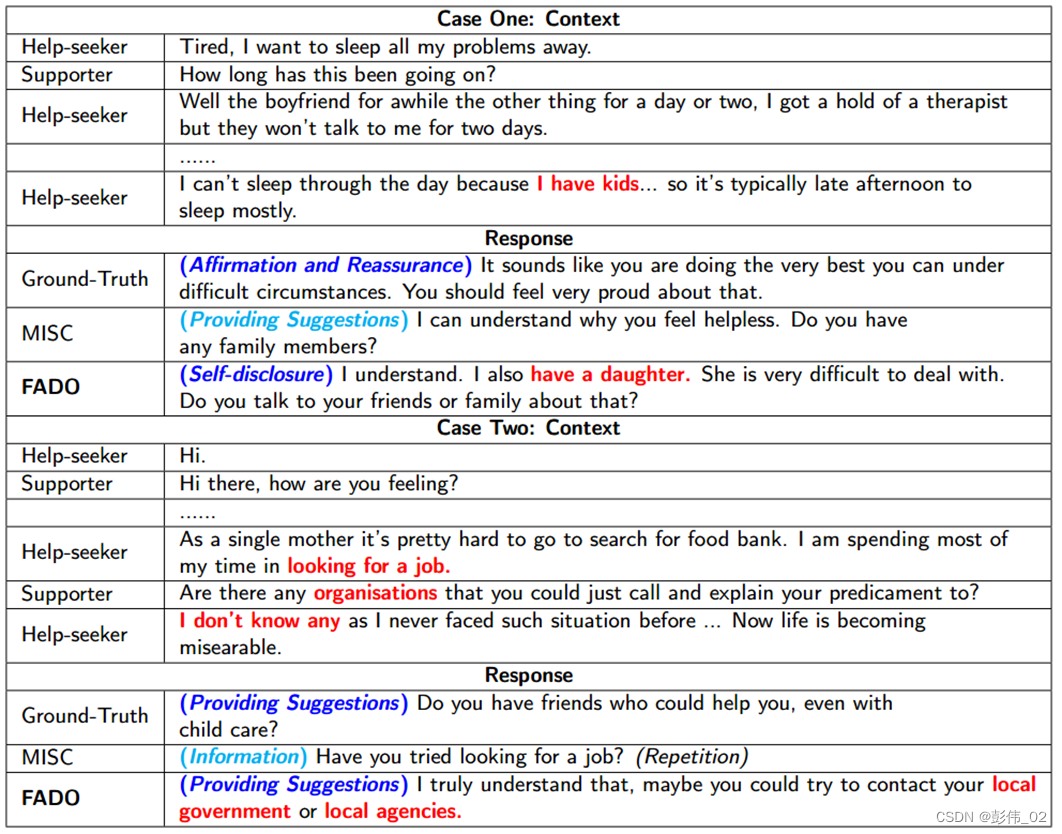
case实验
-
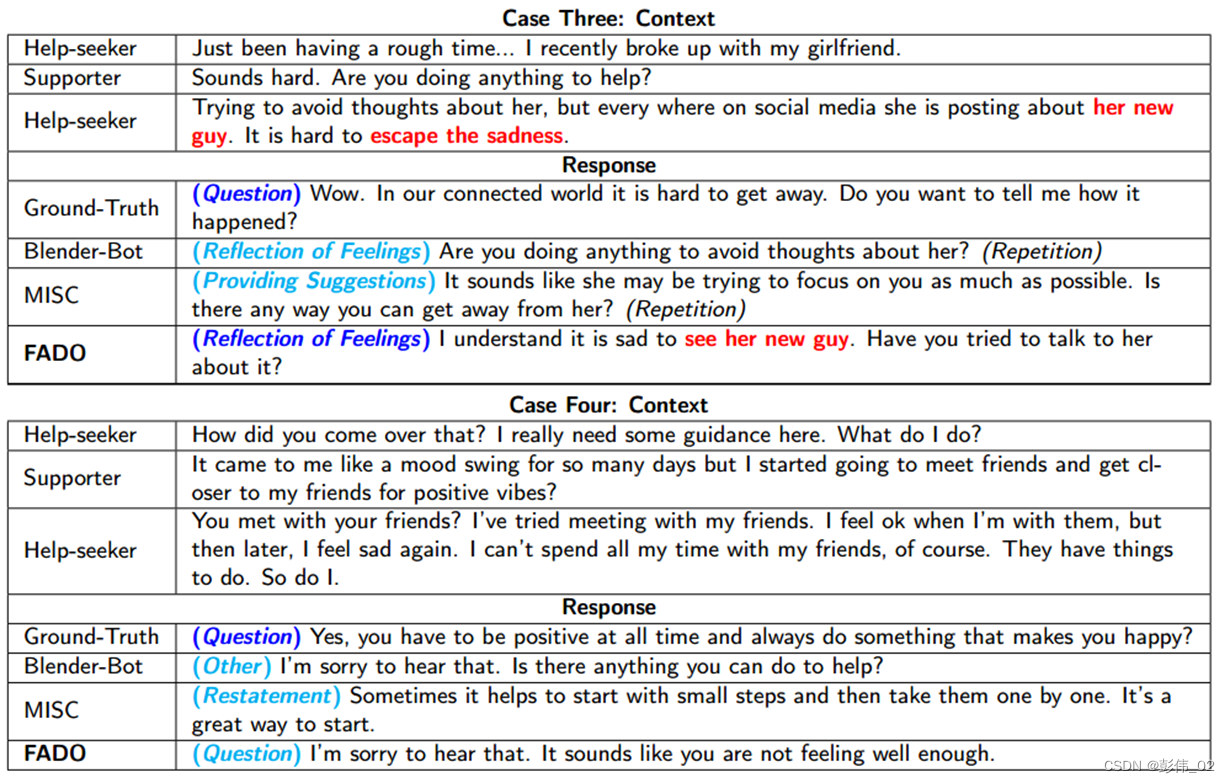
这一部分我们不仅仅验证了生成的回复的质量,同时我们还对生成的回复以及所采取的策略是否一致进行了验证,其中深蓝色表示是一致的情况,浅蓝色表示的是不一致的情况。
-
对于最后一个样本,我们发现所有的模型都出现了不一致的情况,这有可能是对话历史过长导致的长距离依赖问题。
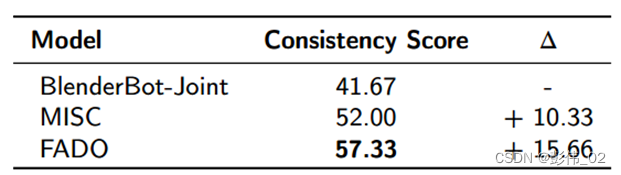
我们还统计了生成的回复和策略之间一致性的得分。发现我们的模型能够大幅度的超越base模型。
总结
- 为了更好地进行策略选择以进行情感支撑,我们提出了一个情绪反馈感知的双向控制网络,利用用户的情绪反馈信息帮助系统来选择更好的策略信息,以生成策略相关的回复。
- 在情感支撑对话中考虑其他心理状态仍然值得研究,比如文化教育背景、个人画像、性格等。同时结合外部知识对用户的目标的表示学习以及推理也是一大挑战。
- 对于情感、意图理解的可解释过程,如何定制具体的评价指标来衡量模型是否真正理解用户的情感。


















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











